要在未来与技术先进的竞争对手的冲突中保持竞争力,就必须加快兵棋推演人工智能(AI)的研究与开发。更重要的是,利用机器学习进行智能作战行为开发将是有朝一日在这一领域实现超人性能的关键--提高在未来战争中的决策质量并加快决策速度。尽管深度强化学习(RL)在游戏中的智能体行为开发方面不断取得令人鼓舞的成果,但在战斗建模与仿真中常见的长视距复杂任务中,其表现尚未达到或超过人类水平。利用分层强化学习(HRL)已被证实的潜力和最近取得的成功,我们的研究正在调查和扩展 HRL 的使用,以创建能够在这些大型复杂模拟环境中有效执行任务的智能体。最终目标是开发出一种能够发挥超人性能的智能体,然后将其作为军事规划者和决策者的人工智能顾问。本文介绍了正在进行的研究方法,以及五个研究领域中的前三个领域,这些领域旨在管理迄今为止限制人工智能在作战模拟中应用的计算量指数级增长问题: (1) 为作战单元开发一个 HRL 训练框架和智能体架构;(2) 为智能体决策开发一个多模型框架;(3) 开发状态空间的维度不变观测抽象,以管理计算量的指数增长;(4) 开发一个内在奖励引擎,以实现长期规划;(5) 将此框架实施到更高保真的作战模拟中。这项研究将进一步推动国防部正在进行的研究兴趣,即扩展人工智能以处理大型复杂的军事场景,从而支持用于概念开发、教育和分析的兵棋推演。
人工智能(AI)技术的最新进展,如 OpenAI 的 ChatGPT,再次体现了人工智能在重塑各行各业方面的变革潜力。正如生成式预训练变换器(GPT)模型从根本上重新定义了对人工智能巨大威力的理解一样,其他人工智能方法也能为国防部门开发改变游戏规则的工具做出贡献,而迄今为止,人工智能已被证明过于复杂,无法有效解决这些问题。
人工智能可以产生变革性影响的一个领域是支持兵棋推演的战斗建模和仿真领域。但遗憾的是,就像兵棋推演的历史可以追溯到几个世纪前一样,如今用于现代兵棋推演的大多数工具和技术也是如此。虽然传统兵棋推演工具(如实体游戏棋盘、纸牌和骰子)绝对仍有其作用,但将兵棋推演带入 21 世纪的压力也越来越大(Berger,2020 年,2022 年;美国国防科学委员会,2021 年;美国国防部副部长,2015 年;美国政府问责局,2023 年),并利用现代技术进步,如人工智能(Davis & Bracken,2022 年),"从技术和方法两方面发展当前的兵棋推演范式"(Wong 等人,2019 年)。
虽然美国在大多数领域都享有军事优势,但机器学习(ML)的大众化已开始为竞争对手和其他国家行为体提供无数的破坏机会(Zhang 等人,2020)。因此,比以往任何时候都更有必要积极投资于研究与开发,以建立对人工智能优缺点的扎实基础理解(Schmidt 等人,2021 年),以及如何将其用于设计、规划、执行和分析各种目的的兵棋推演。只有这样,国防部(DOD)才能更好地应对战略突袭和破坏(Zhang 等人,2020 年)。
然而,兵棋推演和军事规划与迄今为止成功利用人工智能的传统领域--如图像分类和后勤相关的优化问题--有很大不同。由于战争的复杂性,任务分析和规划通常需要在早期应用直觉和思维启发法来限制搜索问题的规模(Zhang 等人,2020 年)。虽然启发式方法确实能让我们更容易地找到可接受的解决方案,但这些解决方案的可扩展性或可靠性通常不足以评估可能出现的大量突发事件。此外,直觉也不足以解决高度复杂的问题,例如那些涉及许多不同参与者的高维空间以及复杂的武器和传感器相互作用的问题(Zhang 等人,2020 年)--然而这些复杂性正是可能决定未来战争的特征(Narayanan 等人,2021 年)。
虽然不认为人工智能会在可预见的未来取代人类的判断或决策,但我们确实认为,人工智能在融入决策辅助工具后,有机会加快决策过程并提供新的见解。事实上,如果不能充分利用人工智能的力量,那么当我们深入多域作战时,就可能会面临巨大风险(Narayanan 等人,2021 年)。最终,通过利用超人智能体作为人类决策者决策支持工具的基础,有望在未来战争中取得超越对手的决策优势--加快决策速度,提高决策质量。因此,要想在未来与技术先进的竞争对手的冲突中保持竞争力,就必须加快对兵棋推演人工智能的研究和开发。更重要的是,利用机器学习进行智能作战行为开发将是有朝一日在这一领域实现超人表现的关键。
本文介绍了在扩展人工智能方面的研究方法,以处理兵棋推演中战斗建模和模拟所特有的复杂而错综复杂的状态空间。虽然研究仍在进行中,而且还不完整,但将在本文中介绍总体方法、初步成果和前进方向。
研究规划
研究利用 RL 已证明的潜力和 HRL 最近取得的成功,打算进一步提高扩展机器学习的能力,以开发智能体行为,用于战斗建模和仿真中常见的大型复杂场景。为了实现这一目标,我们打算吸收文献中的许多见解,同时为这一领域做出我们自己的独特贡献。研究主要分为五个研究领域:(1) HRL 训练框架和作战单元的智能体架构;(2) 用于智能体决策的多模型框架;(3) 状态空间的维度不变观测抽象;(4) HRL 框架的内在奖励工程;(5) 将此框架实施到高保真作战模拟中。本文仅关注前三个研究领域。
HRL 训练框架和智能体架构
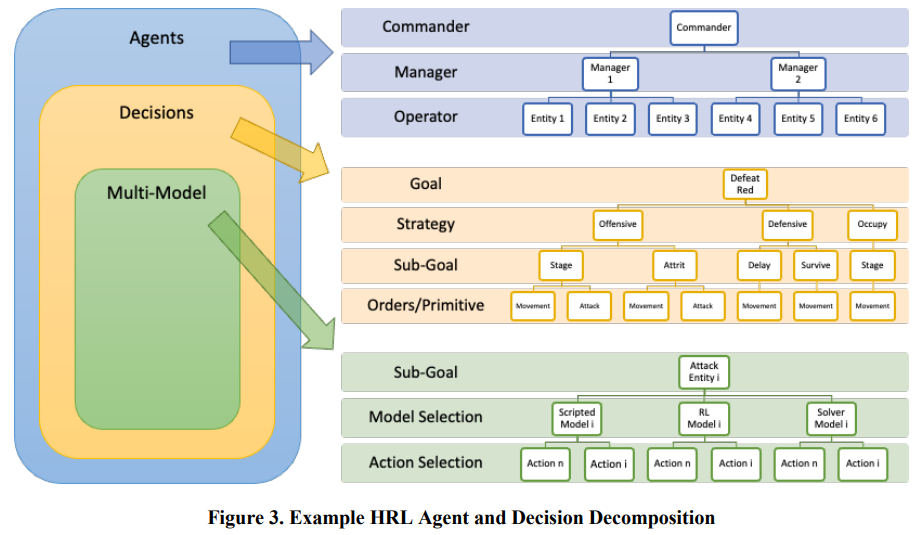
首先开发了一个 HRL 训练框架,通过扩展和吸收 Dayan & Hinton(Dayan & Hinton, 1992)、Vezhnevets 等人(Vezhnevets et al、 2017)、Levy(Levy 等人,2019)、Pope 等人(Pope 等人,2021)、Wang 等人(Wang 等人,2021)、Rood(Rood,2022)和 Li 等人(S. Li 等人,2022)。为了支持这一框架,我们还开发了一种新的智能体架构,由智能体层次结构和决策层次结构组成--每个单独的智能体都是一个多模型智能体。
如图 3 所示,"智能体层次结构 "中的每个层次主要对不同数量的下级智能体实施控制,最低层次控制单个实体。为便于说明,我们将这些层级命名为 指挥官、经理和操作员。然而,我们可以把这种层次结构看作从 1 到 n 层的任何深度,其中最低层级为 1,最高层级为 n。只有少数单元的简单任务可能只需要两个层级,而涉及多个交互单元的复杂任务可能需要三个或更多层级。由于我们的研究打算考察更复杂的场景,因此我们预计至少需要三个层次。
在这一分层框架内,还制定了决策分层。值得注意的是,尽管在图 3 中列出了具体的决策,但这只是为了说明问题,并不一定 是决策的最终细分。萨顿等人最初为决策层次概念创造了 "选项 "一词(萨顿等人,1999 年)。选项是对行动的概括,萨顿等人正式将其用于原始选择。之前的术语包括宏观行动、行为、抽象行动和子控制器。在层次结构中表示这一概念时,我们使用了决策一词。在传统的 RL 问题中,智能体接受观察结果,并在固定的时间步输出一个动作,而在 HRL 问题中,智能体要么被给予背景知识,要么必须发现背景知识,从而以显式或隐式的方式分解问题(Sammut & Webb,2010 年)。然后,智能体利用这些知识,通过训练优化未来回报的策略,更高效地解决问题。
分层结构中的多个层次还允许每个层次针对不同的目标和不同的抽象程度进行训练,从而使扩展到非常复杂的场景成为一个更容易解决的问题。此外,这种分层方法还隐含着对智能体协调与合作的训练,因为上层控制着下层的总体行为(Wang 等人,2021 年)。除最底层外,层次结构的每一层都可以被视为抽象或认知层(即,它们最初是高层决策,最终将为原始行动提供信息)。只有处于层次结构最底层的智能体才是游戏板上的实际实体,会采取影响环境的离散或原始行动。
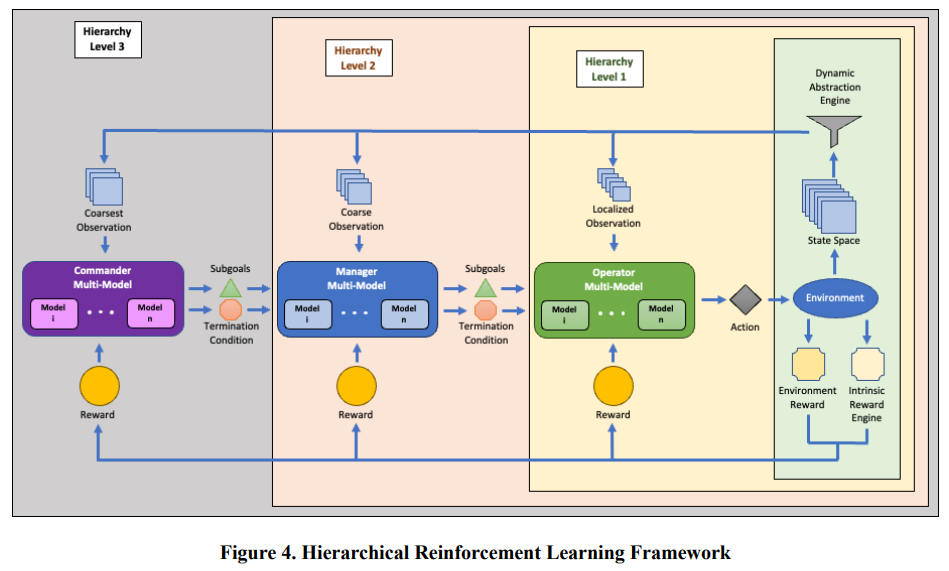
图 4 展示了 HRL 框架。层级结构的指挥官层级接收自己对状态空间的独特抽象观察,并向下一层级输出子目标和终止条件。在下一级中,管理者接收指挥者的子目标和对状态空间的不同抽象观察结果,并输出其 自己的子目标。最后,在最底层,操作员接收子目标和对状态空间的抽象本地观察,并利用我们的多模型智能体框架输出一个供实体采取的行动。
多模型智能体
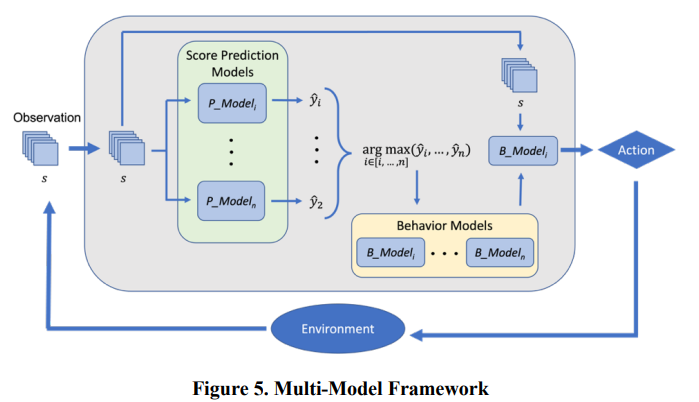
为了构建我们的多模型智能体框架,我们借鉴并采用了专家混合(MoE)(Jacobs 等人,1991 年)、"多模型思想家"(Page,2018 年)、集合方法和 RL 的概念。尽管我们从 MoE 和集合文献中借鉴了采用各种专家网络的想法,但我们偏离了这些传统方法提出的中心思想。虽然我们仍然利用了许多不同的模型,但我们并没有采用纯粹的分而治之的方法(Jacobs 等人,1991 年)或模型输出的汇集(Page,2018 年),而是对模型进行了区分,以确定哪个特定的模型可以在每个行动选择步骤中最大化智能体的整体性能。换句话说,我们并不是将模型输出进行组合,而是简单地将它们作为一个评估函数的输入,然后由该函数决定在每个步骤中应使用哪个特定的行为模型。集合方法要求建模者考虑模型的偏差或缺陷,而我们的多模型方法则允许我们利用一组不同的模型(脚本模型或机器学习训练的模型),而无需考虑模型的平衡或验证。之所以能做到这一点,是因为我们不是将模型预测结合在一起,而是对模型预测进行区分,并采用能最大化特定目标的单一最佳策略。
多模型框架如图 5 所示。在每个行动选择步骤中,多模型都会接收一个观察结果作为输入,并将其传递给每个得分预测模型。每个得分预测模型都会推导出一个预测的游戏得分,并将其输入评估函数。然后根据评估函数选择特定的行为模型。最后,原始观察结果被传递给选定的行为模型,由其产生一个动作。
为了提供选择适当行为模型的评估函数,我们为资源库中的每个行为模型训练了一个单独的分数预测模型。该分数预测模型是一个卷积神经网络(CNN),可根据当前游戏状态推断出游戏分数。预测的游戏得分假定蓝方按照各自的行为模型继续游戏,红方按照特定的对手行为模型继续游戏。鉴于 Atlatl 是一款回合制游戏,而非时间步进模拟,我们将棋盘上实体被提示采取某项行动的每个实例都称为行动选择步骤。尽管迄今为止,我们一直在使用监督学习方法训练得分预测模型,并在游戏中使用了 "行动选择 "模型。数据来训练得分预测模型,但我们最近开发了一个单独版本的得分预测模型,并正在对其进行测试。
在实验中评估了这种多模型方法相对于传统单模型方法(无论是脚本还是基于 RL 的)的有效性,发现多模型方法比表现最好的单模型提高了 62.6%。此外,我们还发现,由更多模型组成的多模型明显优于由较少模型组成的多模型,即使这些额外模型的整体性能较差。这表明,即使我们的某些单个模型在总体上表现不佳,但它们很可能在非常特殊的情况下取得了成功--我们的分数预测模型似乎准确地捕捉到了这一现象,而我们的评估函数也正确地用于为每个行动选择步骤选择最佳模型。
更重要的是,使用这种方法,不必训练一个能够在所有可能情况下都有效执行任务的单一模型,而是可以开发或训练能够在特定情况下执行任务的非常专业的模型,然后在遇到这些特定情况(即游戏中的特定状态)时自动调用这些专业模型。此外,由于我们的多模型可以区分其嵌入的模型,因此我们可以根据需要加入新的模型,而无需考虑行为验证、平衡甚至偏差等问题--传统的集合建模方法通常需要将结果汇集在一起。
状态空间的观测抽象
即使使用 Atlatl 这样的简单环境,将其扩展到更大的场景也会导致性能不佳(Boron,2020;Cannon & Goericke,2020;Rood,2022)。部分原因在于,与人类不同,RL 的样本效率不高,需要大量的训练数据(Botvinick 等人,2019 年;Tsividis 等人,2017 年),而庞大的行动和观察空间则进一步加剧了这一问题。不过,Abel 等人指出,RL 中的抽象可以提高采样效率(Abel 等人,2020 年),从而有可能让我们扩展到处理非常复杂的环境。此外,学习和使用适当的世界抽象表征是任何智能体(无论是生物还是人工智能)都必须具备的基本技能(Abel,2020)。
然而,由于抽象本质上会丢弃信息--这可能会损害基于这些抽象所做决策的有效性--我们必须在使学习变得更容易(或可操作)与保留足够信息以实现最优策略发现之间权衡利弊(Abel,2020)。我们对状态空间抽象得越多,丢失的信息就越多,就越难保证获得最优或接近最优的解决方案(L. Li 等人,2016 年)。不过,这也是一种权衡,因为尽管更粗略的抽象可能会导致次优行动,但它们确实可以更好地进行规划和价值迭代(李玲等人,2016 年)。
为了克服在大型状态空间中进行训练时所面临的一些权衡挑战,同时保留足够的信息以找到最优或接近最优的解决方案,我们目前正在开发一种方法,其中包括根据层次结构的级别应用不同级别的抽象。在《模拟与兵棋推演》一书中,Tolk 和 Laderman 讨论了 "任务通常会驱动所需的抽象层级"(Turnitsa 等人,2021 年)。同样,正如我们在军事规划中通常看到的那样,高层次的抽象会更粗,而低层次的抽象会更细(FM 5-0 Planning and Orders Production, 2022;Joint Publication 5-0 Joint Planning, 2020;MCWP 5-10 Marine Corps Planning Process, 2020)。因此,我们的 HRL 框架涉及在较高层次的决策中应用较粗略的抽象层次,同时仍通过本地观测为较低层次的决策保留所有本地状态空间信息。我们认为,这种方法将使高层的长期规划更加有效,并使低层的计划在当地得到更有效的实时执行。
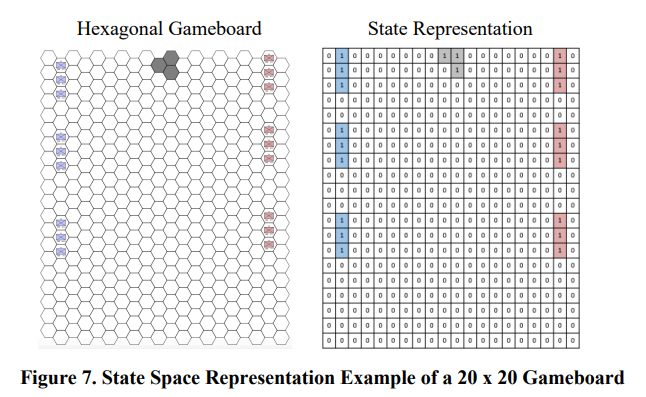
为了说明这一概念,我们首先描述了一般的 Atlatl 观测空间。尽管观察空间在不断演变,但最近的一个观察空间由 n x m 网格的 17 个通道组成,其中网格的每个入口代表 n x m 大小棋盘的一个十六进制。这个观察空间被编码为张量。图 6 举例说明了每个通道所代表的信息。例如,每个通道编码的信息包括单元移动、单元类型、地形类型等。
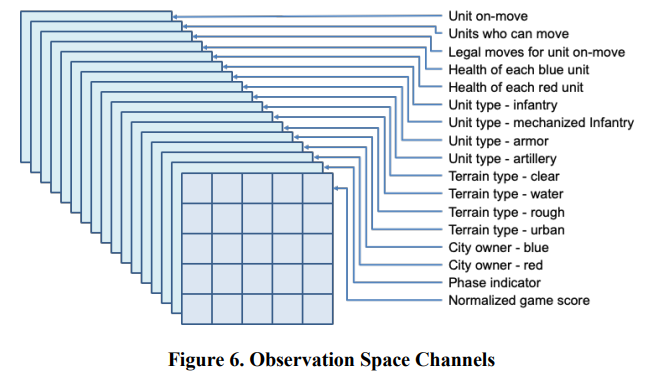
图 7 显示了一个 20 x 20 棋盘的状态空间表示示例,其中叠加了三个通道(蓝色部队、红色部队、城市六角形)。我们在下面所有图中叠加了三个通道,仅供参考;但在 Atlatl 中,这些通道将表示为 3 个独立通道(共 17 个通道),如图 6 所示。