
机器之心报道 编辑:泽南高质量数据,由 ChatGPT「自我博弈」生成。
ChatGPT 出现之后,科技公司正在争相追赶,学界也在不断寻找开源且轻量的解决方案。
此前,人们基于 Meta 的 LLaMA 构建了一系列参数较少的新模型,只用几十亿参数就可以获得接近 GPT-3.5 的效果。然而从 ChatGPT 和 GPT-4 的发展中我们可以看到,高质量的标注数据至关重要,OpenAI 对数据和标注工作下了很大力气。
对于学界来说,很难在短期做同样的事。最近,有研究者尝试通过让 ChatGPT 自我对话生成多轮对话的「数据集」,最终训练出了强大的语言模型。
4 月 4 日,来自加州大学圣迭戈分校、中山大学和微软亚研的研究者提出了「白泽」。
论文《Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data》:

论文链接:https://arxiv.org/abs/2304.01196
白泽目前包括四种英语模型:白泽 -7B、13B 和 30B(通用对话模型),以及一个垂直领域的白泽 - 医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。
白泽的数据处理、训练模型、Demo 等全部代码已经开源。

Github:https://github.com/project-baize/baize/blob/main/README.md * 在线 Demo:https://huggingface.co/spaces/project-baize/baize-lora-7B
在新研究中,作者提出了一个自动收集 ChatGPT 对话的流水线,通过从特定数据集中采样「种子」的方式,让 ChatGPT 自我对话,批量生成高质量多轮对话数据集。其中如果使用领域特定数据集,比如医学问答数据集,就可以生成高质量垂直领域语料。
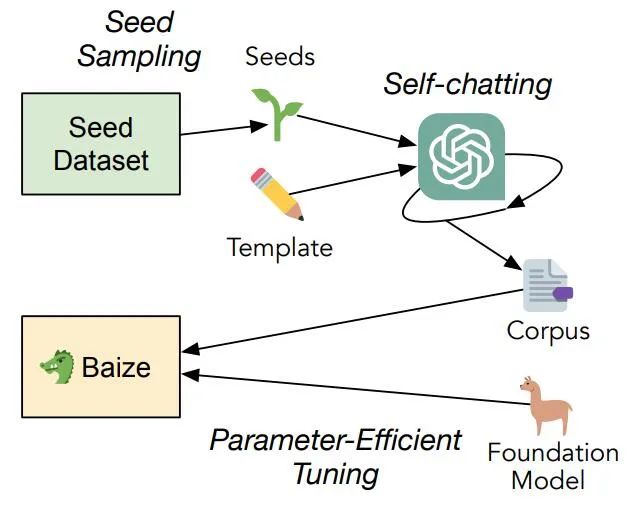
白泽提出的训练方法。通过利用 ChatGPT 的功能自动生成高质量的多轮聊天语料,让 ChatGPT 与自己进行对话,模拟用户和 AI 的响应。
为了在资源匮乏的环境中微调大语言模型,作者采用了有效利用计算资源的参数高效调优方法。该策略使最先进的语言模型保持了高性能和适应性。白泽改进了开源大型语言模型 LLaMA,通过使用新生成的聊天语料库对 LLaMA 进行微调,该模型在单个 GPU 上运行,使其可供更广泛的研究人员使用。
自聊天的过程是训练内容的基础,为了让 ChatGPT 能够有效生成数据,研究人员应用一个模板来定义格式和要求,让 ChatGPT 的 API 持续为对话双方生成抄本,直到达到自然停止点。对话以「种子」为中心,「种子」可以是一个问题,也可以是设置聊天主题的关键短语。
通过这样的方法,研究人员分别收集了 5 万条左右 Quora、StackOverflow(编程问答)和 MedQA(医学问答)的高质量问答语料,并已经全部开源。

ChatGPT 使用从 Quora 数据集采样的种子生成的自我聊天示例。
相比之下,Vicuna 使用从 sharegpt.com 上抓取的对话,这样做的一个好处是收集到的数据质量很高。但是,此来源可能存在严重的隐私和法律问题。值得注意的是,sharegpt.com 最近已经禁止抓取,这意味着该数据源不再可用,Vicuna 难以复现。
在取得这些数据后,作者使用 LoRA(low-rank adaptation)方法在英伟达 A100 单卡下训练了三种尺寸的白泽模型,最短训练时长只需要 5 小时(医疗模型),最长也只需要 36 小时(30B 通用对话模型)。训练的权重最大也仅有 54.6M 的参数量。

研究人员将白泽与 Alpaca-LoRA、ChatGPT 进行比较,展示了常识问答、事件分析、解释笑话、问题拒答、写代码,以及医疗模型的健康咨询等能力。

表 5:解释雷曼兄弟破产。总体而言,Baize-7B 提供了比 Alpaca-LoRA 更全面的答案,同时包含了 ChatGPT 答案中的大部分要点。另一方面,ChatGPT 提供了更长更详细的答案。

表 6:解释笑话的示例。Baize-13B 和 ChatGPT 可以成功解释这个笑话,Alpaca-LoRA 未能做到。

表 7:聊天模型如何响应用户不道德请求的示例。Baize 和 ChatGPT 拒绝回答不道德的问题,而 Alpaca-LoRA 提供答案。

表 8:生成代码示意。
除了一般模型外,研究人员还在医疗从业者的帮助下测试了 Baize-Healthcare,专业人员已确认白泽有关医疗问题的回应是适当的。
目前,「白泽」支持 20 种语言,对于英语以外的内容质量有限,继承了 LLaMA 的知识,可能会出现幻觉,或用过时知识进行回答。
下一步,研究人员计划探索引入强化学习以进一步提高白泽模型的性能。
© THE END 转载请联系本公众号获得授权 投稿或寻求报道:content@jiqizhixin.com
