大模型已成为 AI 圈的一种潮流,不仅横扫各大性能榜单,更产生了诸多有趣应用。
例如,微软和 OpenAI 开发的自动代码建议补全神器 Copilot,化身程序员最佳助手,提升工作效率。
![]()
OpenAI 刚刚发布能以假乱真的文本生成图像模型 DALL-E 2,Google 便紧接着发布了 Imagen,在大模型上,大公司也是相当的卷,丝毫不比 CV 刷榜差。
![]()
文本到图像生成样例“一个被猫绊倒的希腊人雕像”
(左侧两列为 Imagen,右侧两列为 DALL·E 2)
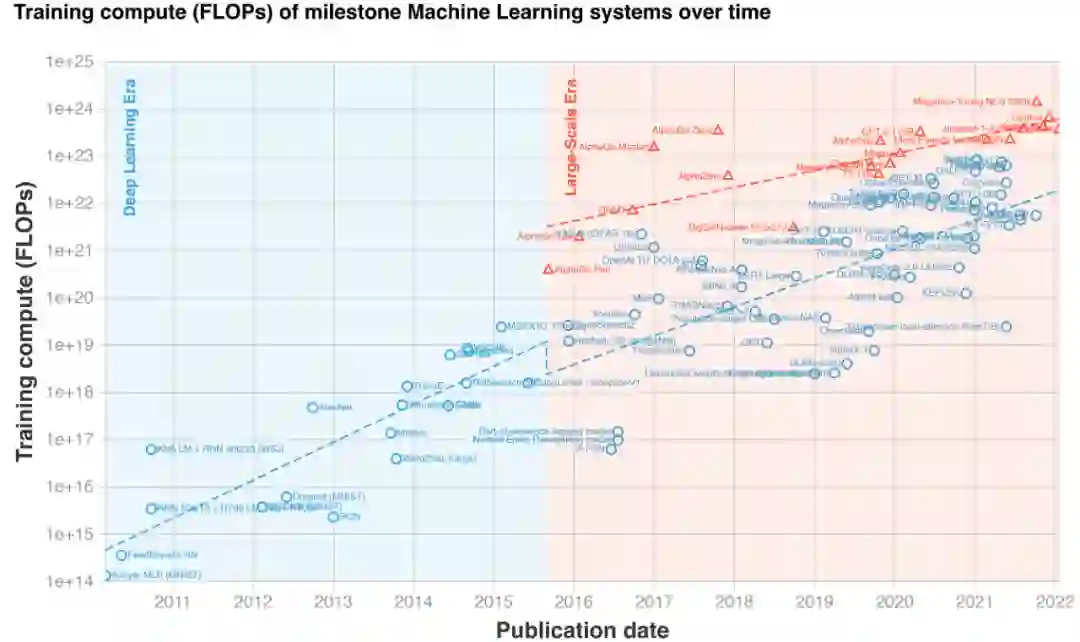
模型增大带来的神奇表现,使得近几年预训练模型规模呈现爆炸式增长。然而,训练甚至微调大模型都需要非常高的硬件成本,动辄几十、上百张 GPU。此外,PyTorch、TensorFlow 等现有深度学习框架也难以有效处理超大模型,通常需要专业的 AI 系统工程师做针对具体模型做适配和优化。
更重要的是,不是每一个实验室以及研发团队都具备 “钞” 能力,能够随时调用大规模 GPU 集群来使用大模型,更不用提仅有一张显卡的个人开发者。因此,尽管大模型已经吸引了大量关注,高昂的上手门槛却令大众“望尘莫及”。
![]()
导致大模型使用成本增高的核心原因是显存限制。GPU 计算虽快,但显存容量有限,无法容纳大模型。Colossal-AI 针对这一痛点,通过异构内存系统,高效地同时使用 GPU 显存以及价格低廉的 CPU 内存,在仅有一块 GPU 的个人 PC 上便能训练高达 180 亿参数 GPT,
可提升模型容量十余倍,大幅度降低了 AI 大模型微调和推理等下游任务和应用部署的门槛,还能便捷扩展至大规模分布式。
Hugging Face 为深度学习社区提供了超过 5 万个 AI 模型的实现,最其中也不乏像 GPT, OPT 这样的大模型,现已成为最流行的 AI 库之一。
![]()
Colossal-AI 无缝支持 Hugging Face 社区模型,让大模型对每一位开发者都变得触手可及。接下来,我们将以 Meta 发布的大模型 OPT 为例,展现如何使用 Colossal-AI,
仅需添加几行代码,便可实现大模型的低成本训练和微调。
开源地址:
https://github.com/hpcaitech/ColossalAI
OPT 的全称为 Open Pretrained Transformer,是 Meta(Facebook) AI 实验室发布的对标 GPT-3 的大规模 Transformer 模型。与 OpenAI 尚未公开模型权重的 GPT-3 相比,Meta AI 慷慨地开源了所有的代码以及模型权重,极大推动了 AI 大模型的民主化,每一位开发者都能以此为基础开发个性化的下游任务。接下来,我们将用 Hugging Face 提供的 OPT 模型的预训练权重进行 Casual Language Modelling 的微调。
想要使用 Colossal-AI 中各个强大功能,用户无需更改代码训练逻辑,只用添加一个简单的配置文件,即可赋予模型所期望的功能,比如混合精度、梯度累积、多维并行训练、冗余内存优化等。
在一张 GPU 上,以异构训练为例,我们只需在配置文件里加上相关配置项。其中 tensor_placement_policy 决定了我们异构训练的策略,这个参数可以为 cuda、cpu 以及 auto。各个策略有不同的优点:
-
cuda: 将全部模型参数都放置于 GPU 上,适合不 offload 时仍然能进行训练的传统场景;
-
cpu 则会将模型参数都放置在 CPU 内存中,仅在 GPU 显存中保留当前参与计算的权重,适合超大模型的训练;
-
auto 则会根据实时的内存信息,自动决定保留在 GPU 显存中的参数量,这样能最大化利用 GPU 显存,同时减少 CPU-GPU 之间的数据传输。
对于一般用户而言,仅需选择 auto 策略,由 Colossal-AI 自动化地实时动态选择最佳异构策略,最大化计算效率。
from colossalai.zero.shard_utils import TensorShardStrategy
zero = dict(model_config=dict(shard_strategy=TensorShardStrategy(), tensor_placement_policy="auto"), optimizer_config=dict(gpu_margin_mem_ratio=0.8)
在配置文件准备好之后,
我们只需插入几行代码即可启动声明的新功能。
首先,通过一行代码,使用配置文件启动 Colossal-AI,Colossal-AI 会自动初始化分布式环境,并读取相关配置,之后将配置里的功能自动注入到模型以及优化器等组件中。
colossalai.launch_from_torch(config='./configs/colossalai_zero.py')
接下来,用户可以照常定义数据集、模型、优化器、损失函数等,例如直接使用原生 PyTorch 代码。在定义模型时,只需将模型放置于 ZeroInitContext 下初始化即可。在例子里,我们使用 Hugging Face 提供的 OPTForCausalLM 模型以及预训练权重,在 Wikitext 数据集上进行微调。
with ZeroInitContext(target_device=torch.cuda.current_device(), shard_strategy=shard_strategy, shard_param=True): model = OPTForCausalLM.from_pretrained( 'facebook/opt-1.3b' config=config )
接着,只需要调用 colossalai.initialize,便可将配置文件里定义的异构内存功能统一注入到训练引擎中,即可启动相应功能。
engine, train_dataloader, eval_dataloader, lr_scheduler = colossalai.initialize(model=model, optimizer=optimizer, criterion=criterion, train_dataloader=train_dataloader, test_dataloader=eval_dataloader, lr_scheduler=lr_scheduler)
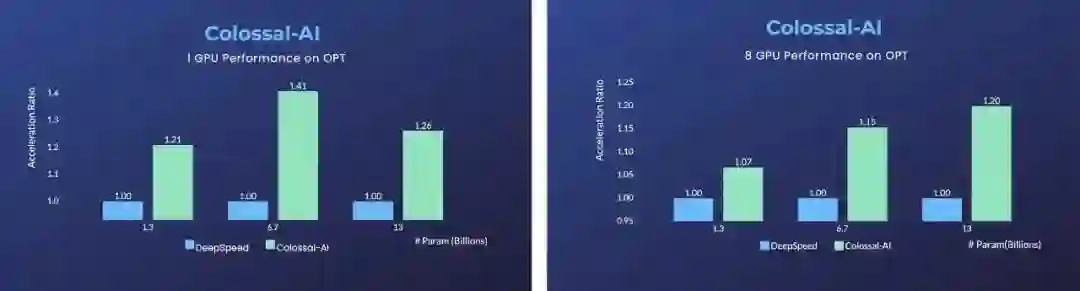
在单张 GPU,与微软 DeepSpeed 相比,Colossal-AI 的使用自动化的 auto 策略,在不同的模型规模上相比 DeepSpeed 的 ZeRO Offloading 策略,均体现出显著优势,
最快可实现 40% 的加速。
而 PyTorch 等传统深度学习框架,在单张 GPU 上已经无法运行如此大的模型。
![]()
对于使用 8 张 GPU 的并行训练,Colossal-AI 仅需在启动命令中添加 - nprocs 8 即可实现!
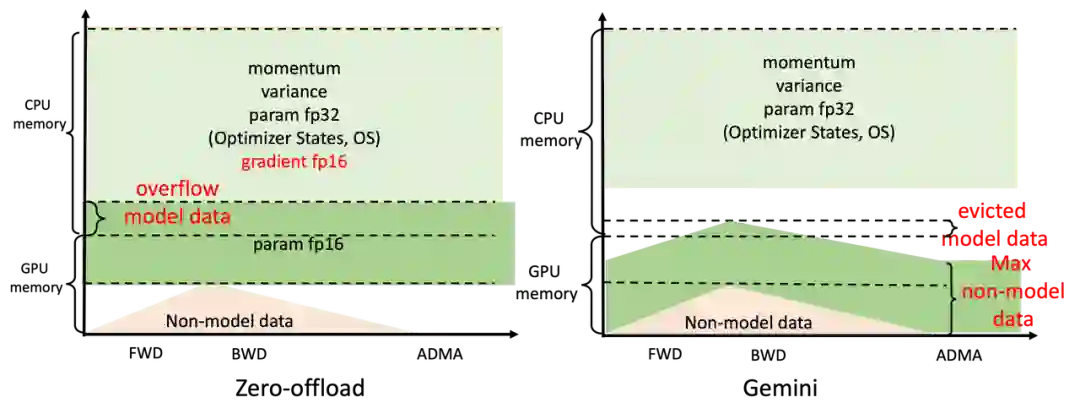
如此显著的提升来自于 Colossal-AI 的高效异构内存管理子系统 Gemini。简单的来说,在模型训练时,Gemini 在前面的几个 step 进行预热,收集 PyTorch 动态计算图中的内存消耗信息;在预热结束后,计算一个算子前,利用收集的内存使用记录,Gemini 将预留出这个算子在计算设备上所需的峰值内存,并同时从 GPU 显存里移动一些模型张量到 CPU 内存。
![]()
Gemini 内置的内存管理器给每个张量都标记一个状态信息,包括 HOLD、COMPUTE、FREE 等。然后,根据动态查询到的内存使用情况,不断动态转换张量状态、调整张量位置,相比起 DeepSpeed 的 ZeRO Offload 的静态划分,Colossal-AI Gemini 能更高效利用 GPU 显存和 CPU 内存,实现在硬件极其有限的情况下,最大化模型容量和平衡训练速度。
![]()
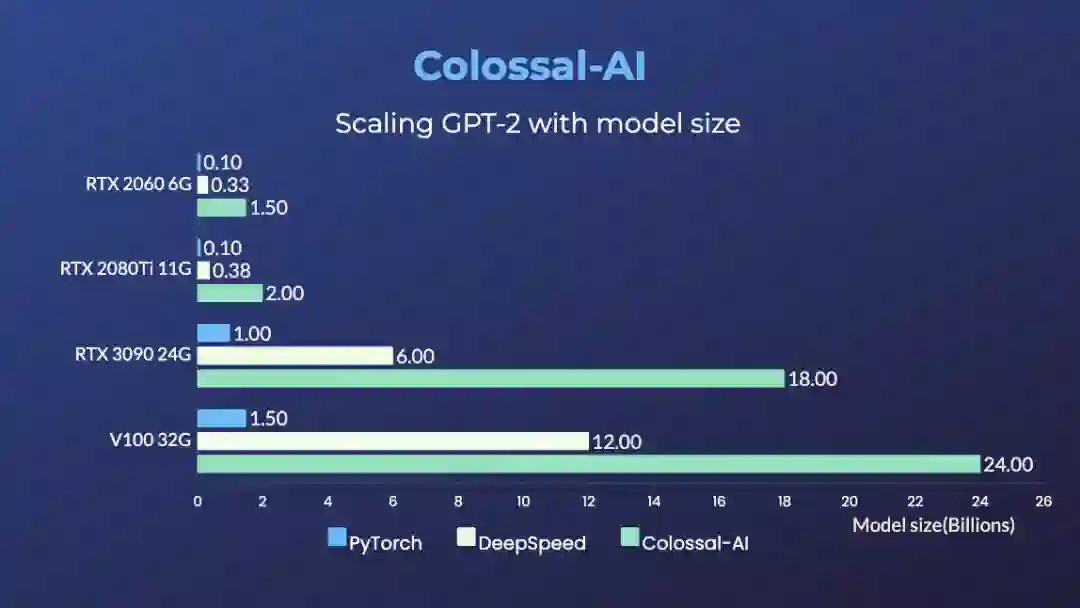
对于大模型的代表 GPT,使用 Colossal-AI 在搭载 RTX 2060 6GB 的普通游戏笔记本上,也足以训练高达 15 亿参数模型;对于搭载 RTX3090 24GB 的个人电脑,更是可以直接训练 180 亿参数的模型;对于 Tesla V100 等专业计算卡,Colossal-AI 也能显示出显著改善。
并行分布式技术是进一步加速模型训练的重要手段,想要以最短时间训练当今世界最大最前沿的 AI 模型,仍离不开高效的分布式并行扩展。针对现有方案并行维度有限、效率不高、通用性差、部署困难、缺乏维护等痛点,Colossal-AI 通过高效多维并行和异构并行等技术,让用户
仅需极少量修改,即可高效快速部署 AI 大模型训练。
例如,对于同时使用数据并行、流水并行、2.5 维张量并行等
复杂并行策略,仅需简单声明,即可自动实现,
Colossal-AI 无需像其他系统和框架侵入代码,手动处理复杂的底层逻辑。
Pythonparallel = dict( pipeline=2, tensor=dict(mode='2.5d', depth = 1, size=4))
具体来说,对于 GPT-3 这样的超大 AI 模型,相比英伟达方案,
Colossal-AI 仅需一半的计算资源,
即可启动训练;若使用相同计算资源,则能提速 11%,
可降低 GPT-3 训练成本超百万美元。
Colossal-AI 相关解决方案已成功
自动驾驶、云计算、零售、医药、芯片
等行业知名厂商落地应用,广受好评。
![]()
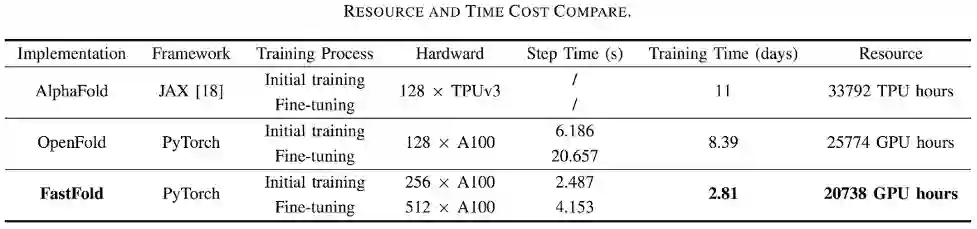
例如,对于蛋白质结构预测应用 AlphaFold2,基于 Colossal-AI 的加速方案的 FastFold,成功超越谷歌和哥伦比亚大学的方案,将 AlphaFold2 训练时间从 11 天减少到 67 小时,且总成本更低,在长序列推理中也实现 9.3~11.6 倍的速度提升。
![]()
Colossal-AI 注重开源社区建设,提供中文教程,开放用户社群及论坛,对于用户反馈进行高效交流与迭代更新,不断添加 PaLM、AlphaFold 等前沿应用。
自然开源以来,Colossal-AI 已经
多次在 GitHub 及 Papers With Code 热榜位列世界第一,
与众多已有数万 star 的明星开源项目一起受到海内外关注!
![]()
https://github.com/hpcaitech/ColossalAI
https://medium.com/@yangyou_berkeley/colossal-ai-seamlessly-accelerates-large-models-at-low-costs-with-hugging-face-4d1a887e500d
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com