

部署大型语言模型(LLMs)具有挑战性,因为它们在实际应用中的内存效率低下且计算密集。为了应对这一问题,研究人员通过微调人类标签或利用LLM生成的标签进行蒸馏,训练更小的任务特定模型。然而,微调和蒸馏需要大量的训练数据,以达到与LLMs相当的性能。**我们引入逐步蒸馏,一种新的机制:(a)训练比LLMs表现更好的较小模型;(b)通过利用比微调或蒸馏所需的更少训练数据来实现这一点。我们的方法在多任务训练框架内为小型模型提取LLM rationales(基本原理/解释/依据),作为额外的监督。**我们在4个NLP基准测试中得出三个发现:首先,与微调和蒸馏相比,我们的机制在使用更少的标注/未标注训练样本的情况下实现了更好的性能。其次,与LLMs相比,我们使用明显较小的模型大小实现了更好的性能。第三,我们减少了模型大小和超过LLMs所需的数据量;在一个基准任务中,我们的770M T5模型使用仅80%的可用数据就超过了540B PaLM模型。
https://www.zhuanzhi.ai/paper/fa04cb640eb5b7dd65cddc946c76b80f
1. 引言
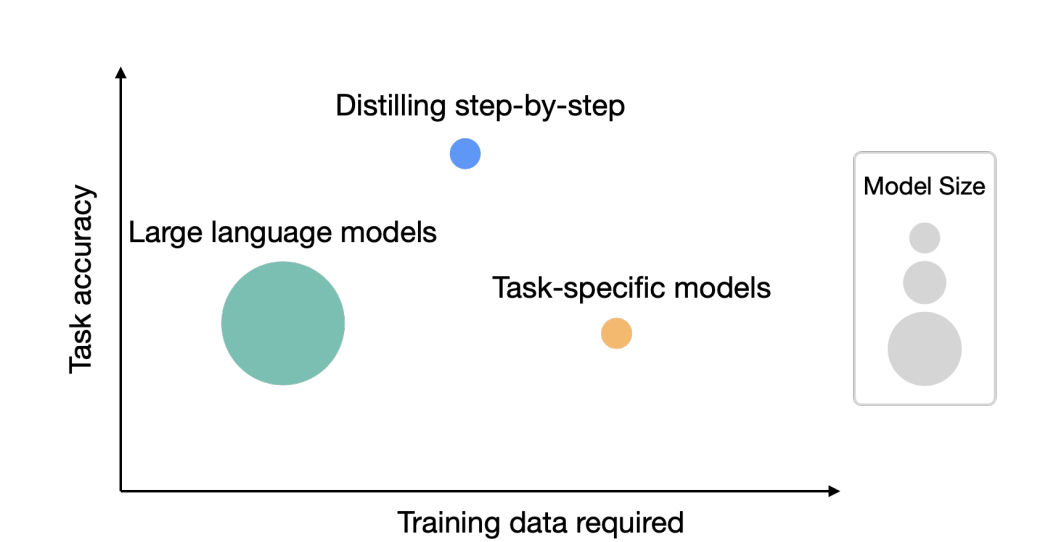
图1:虽然大型语言模型(LLM)提供了强大的零样本/少样本性能,但在实践中具有挑战性。另一方面,传统的训练小型特定任务模型的方法需要大量的训练数据。本文提出逐步蒸馏(Distilling step),一种新的范式,从LLM中提取基本原理作为信息性任务知识训练小型模型,既减少了部署的模型大小,也减少了训练所需的数据。
尽管大型语言模型(LLMs)(Brown等人,2020;Chowdhery等人,2022;Thoppilan等人,2022;Hoffmann等人,2022;Smith等人,2022b;Zhang等人,2022)提供了令人印象深刻的少样本学习能力,但由于其庞大的规模,这些模型在实际应用中具有挑战性。运行单个1750亿参数的LLM至少需要350GB GPU内存,并使用专门的基础设施(Zheng等人,2022)。更糟糕的是,如今的顶级LLMs包含超过5000亿个参数(Chowdhery等人,2022),需要更多的内存和计算资源。这样的计算需求远远超出了大多数产品团队的承受能力,特别是对于需要低延迟性能的应用程序。
为了规避大型模型的部署挑战,从业者通常选择部署较小的专用模型。这些较小的模型使用两种常见范式之一进行训练:微调或蒸馏。微调使用下游人类注释数据更新预训练的较小模型(例如BERT(Devlin等人,2018)或T5(Raffel等人,2020))(Howard和Ruder,2018)。蒸馏使用由更大的LLM生成的标签训练相同的较小模型(Tang等人,2019;Wang等人,2021;Smith等人,2022a;Arora等人,2022)。不幸的是,这些范式以成本降低模型大小:为了达到与LLMs相当的性能,微调需要昂贵的人类标签,而蒸馏需要大量无标签数据,这些数据可能难以获得(Tang等人,2019;Liang等人,2020)。
在这项工作中,我们引入逐步蒸馏,一种用更少训练数据训练较小模型的新型简单机制。我们的机制减少了将LLMs微调和蒸馏为较小模型所需的训练数据量。我们的机制的核心是从将LLMs视为嘈杂标签的来源转变为将它们视为可以推理的代理:LLMs可以生成自然语言rationales(基本原理/解释/依据),为其预测的标签辩护(Wei等人,2022;Kojima等人,2022)。例如,当被问到“一个绅士正在携带高尔夫球设备,他可能有什么?(a)球杆,(b)礼堂,(c)冥想中心,(d)会议,(e)教堂”时,LLM可以通过链式思考(CoT)推理(Wei等人,2022)回答“(a)球杆”,并通过陈述“答案必须是用于高尔夫球的东西。在上述选项中,只有球杆是用于高尔夫球的。”来合理化标签。我们使用这些提取的rationales(基本原理/解释/依据)作为额外的、更丰富的信息,在一个多任务训练设置中训练较小的模型,包括标签预测和rationales(基本原理/解释/依据)**预测(Raffel等人,2020;Narang等人,2020)。
逐步蒸馏使我们能够学习任务特定的较小模型,这些模型在使用超过500倍更少的模型参数时胜过LLMs,并且与传统微调或蒸馏相比,需要更少的训练样本(图1)。我们在4个NLP基准测试中得出三个有前景的实证结论。首先,与微调和蒸馏相比,我们的模型在各个数据集上平均使用超过50%更少的训练样本(最多减少超过85%)时,实现了更好的性能。其次,我们的模型在模型大小上大大优于LLMs(最多小2000倍),大大降低了模型部署所需的计算成本。第三,我们同时减少了模型大小和超过LLMs所需的数据量。我们使用一个770M T5模型超过了540B参数LLM的性能;如果使用现有的微调方法,这个较小的模型只需使用80%的标记数据集。当只有未标记的数据时,我们的小型模型仍然与LLMs表现相当或更好。我们仅使用一个11B T5模型就超过了540B PaLM的性能。我们进一步表明,当一个较小的模型比LLM表现差时,逐步蒸馏可以更有效地利用额外的未标记数据来匹配LLM的性能,与标准蒸馏方法相比。
2 逐步蒸馏
我们提出了一种新的范式,逐步蒸馏,它利用LLMs对其预测进行推理的能力,以数据高效的方式训练较小的模型。我们的整体框架如图2所示。我们的范式有两个简单的步骤:首先,给定一个LLM和一个未标记的数据集,我们提示LLM生成输出标签以及支持标签的rationales(基本原理/解释/依据)。**rationales(基本原理/解释/依据)**是自然语言解释,为模型预测的标签提供支持(见图2)。rationales(基本原理/解释/依据)是当今自监督LLM的一种新兴行为特性。其次,我们利用这些rationales以及任务标签来训练较小的下游模型。直观地说,**rationales(基本原理/解释/依据)**提供了关于为什么输入映射到特定输出标签的更丰富、更详细的信息。
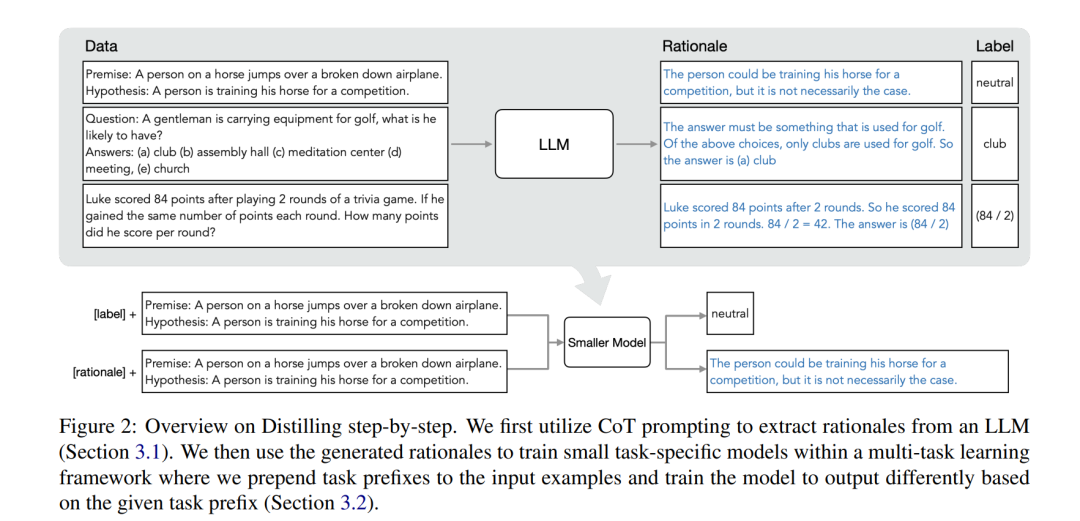
2.1 从LLMs中提取rationales(基本原理/解释/依据)
最近的研究发现LLMs有一个有趣的新兴特性:它们能够生成支持其预测的rationales(Wei等人,2022;Kojima等人,2022)。虽然这些研究主要关注如何从LLMs中引出这种推理能力(Nye等人,2021;Wei等人,2022;Kojima等人,2022),但我们在训练较小的下游模型时使用了它们。具体来说,我们利用链式思考(CoT)提示(Wei等人,2022)从LLMs中引出和提取rationales。

2.2 用原理训练较小的模型
本文首先描述了当前学习特定任务模型的框架。有了这个框架,我们对其进行了扩展,以将基本原理纳入训练过程。形式上,我们将数据集表示为D = {(xi, yi)} N i=1,其中每个xi表示一个输入,yi是相应的所需输出标签。虽然所提出框架支持任何模态的输入和输出,但实验将x和y限制为自然语言。这个文本到文本框架(Raffel等人,2020)包含各种自然语言处理任务:分类、自然语言推理、问题回答等。 训练特定任务模型的最常见做法是使用监督数据对预训练模型进行微调(Howard和Ruder, 2018)。在没有人工标注标签的情况下,特定任务的蒸馏(Hinton等人,2015;Tang et al., 2019)使用LLM教师生成伪噪声训练标签,yˆi代替yi (Wang et al., 2021;Smith等人,2022a;Arora等人,2022年)。 在这项工作中,我们没有将rationales作为额外的模型输入,而是将学习rationales视为一个多任务问题。具体来说,我们训练模型 f(xi) → (ˆyi, rˆi),不仅预测任务标签,还根据文本输入生成相应的rationales。

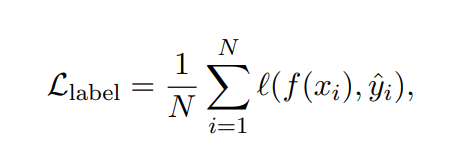
3 实验
我们通过实证验证了逐步蒸馏方法的有效性。首先,与标准的微调和任务蒸馏方法相比,我们展示了逐步蒸馏方法实现的优势。在训练样本数量较少的情况下,逐步蒸馏方法表现更优,显著提高了学习小型任务专用模型的数据效率(第4.1节)。其次,我们展示了逐步蒸馏方法在模型大小远小于大型语言模型(LLMs)的情况下,仍能取得更好的性能,与大型语言模型相比,大幅降低了部署成本(第4.2节)。最后,我们研究了逐步蒸馏方法在超越大型语言模型性能方面所需的最小资源,包括训练样本数量和模型大小。我们发现逐步蒸馏方法在使用更少数据和更小模型的情况下,胜过大型语言模型,同时提高了数据效率和部署效率(第4.3节)。
在实验中,我们将540B PaLM模型(Chowdhery等人,2022年)视为大型语言模型(LLM)。对于任务特定的下游模型,我们使用T5模型(Raffel等人,2020年),并从公开可用的资源中获取预训练权重来初始化模型。对于CoT提示,我们在可用时遵循Wei等人(2022年)的方法,并为新数据集策划我们自己的示例。我们在附录A.1中提供了更多实现细节。
3.1 减少训练数据
我们将逐步蒸馏方法与学习任务特定模型的两种最常见方法进行比较:(1)当有人类标注的样本可用时,使用标准微调方法;(2)当仅有未标注样本可用时,使用标准任务蒸馏方法。具体来说,标准微调是指使用标准标签监督通过预训练然后微调模型的流行范式(Howard和Ruder,2018年)。另一方面,当仅有未标注样本可用时,标准任务蒸馏方法将教师大型语言模型预测的标签视为真实标签,从而学习任务特定模型(Hinton等人,2015年;陈等人,2020年;Wang等人,2021年;Smith等人,2022a;Arora等人,2022年)。
在以下一系列实验中,我们将任务特定模型固定为220M T5-Base模型,并比较在可用训练样本数量不同的情况下,不同方法所实现的任务性能。
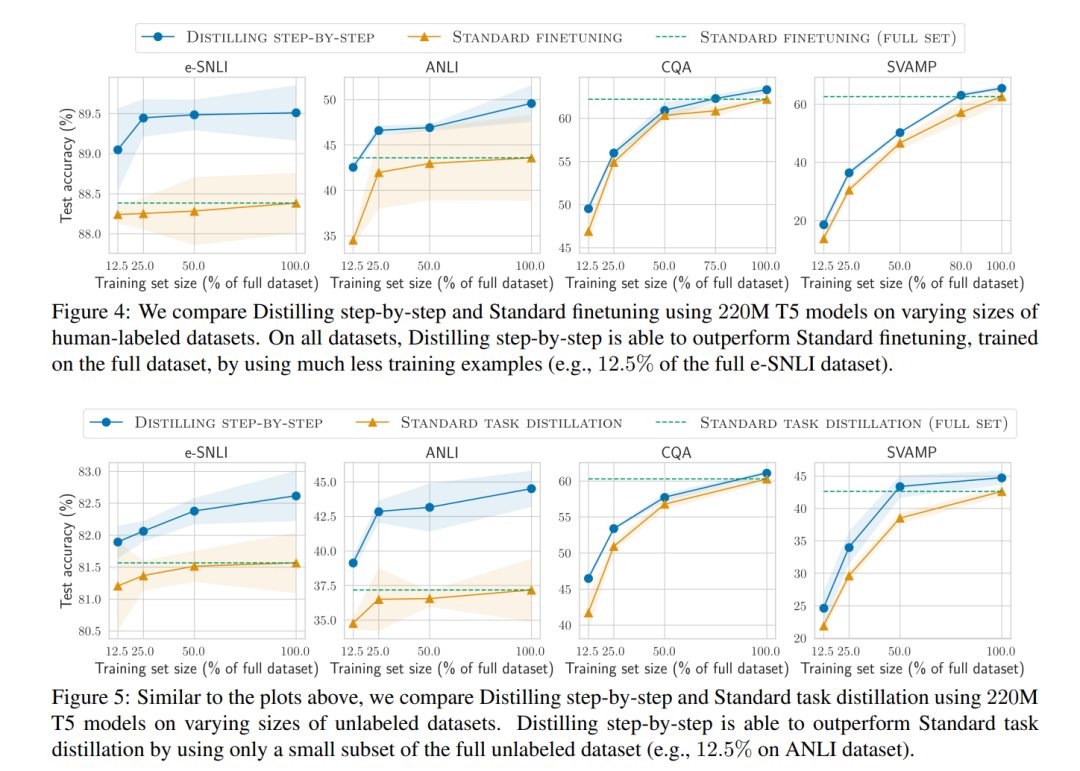
逐步蒸馏方法在使用更少的标注样本情况下优于标准微调。当使用人类标注的样本进行微调时,图4显示,在使用不同数量的标注样本时,逐步蒸馏方法始终比标准微调表现更好。此外,我们发现逐步蒸馏方法可以在使用更少的标注样本的情况下达到与标准微调相同的性能。特别是,仅使用eSNLI完整数据集的12.5%,逐步蒸馏方法就可以在性能上超过使用完整数据集100%训练的标准微调。同样,我们分别在ANLI、CQA和SVAMP上实现了减少75%、25%和20%训练样本数量以超过标准微调的表现。 逐步蒸馏方法在使用更少的未标注样本时,优于标准蒸馏方法。当仅有未标注数据可用时,我们将逐步蒸馏方法与标准任务蒸馏方法进行比较。在图5中,我们观察到与微调设置相类似的整体趋势。具体来说,我们发现逐步蒸馏方法在所有4个数据集上,在使用不同数量的未标注数据情况下,均优于标准任务蒸馏方法。我们同样发现,逐步蒸馏方法在使用更少的未标注数据时仍能胜过标准任务蒸馏方法。例如,在e-SNLI数据集上,我们只需要完整未标注数据集的12.5%,就可以超过使用100%训练样本的标准任务蒸馏方法所取得的性能。
4.2 减小模型大小
在以下一系列实验中,我们将训练集大小固定(使用数据集的100%),并将使用逐步蒸馏方法和标准方法训练的不同大小的小型T5模型与大型语言模型(LLMs)进行比较。具体来说,我们考虑了3种不同大小的T5模型,即220M T5-Base、770M T5-Large和11B T5-XXL。对于LLMs,我们包括两种基线方法:(1)少样本CoT(Wei等人,2022年);(2)PINTO微调(Wang等人,2022a)。少样本CoT直接利用CoT示范来提示540B PaLM模型在预测最终标签之前生成中间步骤,而无需对LLM进行进一步的微调。PINTO微调是指我们扩展Wang等人(2022a)的方法来处理除问答任务之外的任务,这些任务没有被Wang等人(2022a)研究。在这里,我们在PaLM模型生成的输出基础上对220M T5-Base模型进行微调,这可以看作是带有额外参数的LLMs的微调方法(Zhang等人,2020年;Lester等人,2021年)。我们分别在图6和图7中呈现了在有标签数据集或无标签数据集的两种广泛场景下的实验结果。我们按照预测时部署的模型大小(x轴)和相应任务性能(y轴)绘制每种方法。
逐步蒸馏方法在使用不同模型大小时,相较于标准基线方法有所提升。在图6和图7中,我们分别看到逐步蒸馏方法在所有大小的T5模型上始终优于标准微调和标准蒸馏。在ANLI上的提升最为显著,其中逐步蒸馏方法在任务准确性方面分别比标准微调和蒸馏提高了平均8%和13%。 逐步蒸馏方法通过使用更小的任务特定模型超越LLMs。在图6中,当有人类标注的数据集可用时,逐步蒸馏方法可以始终使用更小的T5模型,在所有4个考虑的数据集上优于少样本CoT和PINTO微调。例如,我们可以在eSNLI上使用220M(超过2000倍小)的T5模型实现比540B PaLM模型的少样本CoT更好的性能,使用770M(超过700倍小)的T5模型在ANLI和SVAMP上取得更好的性能,以及使用11B(超过45倍小)的T5模型在CQA上取得更好的性能。无标签数据增强进一步改进了逐步蒸馏。

3.3 使用最小模型大小和最少训练数据超越LLMs
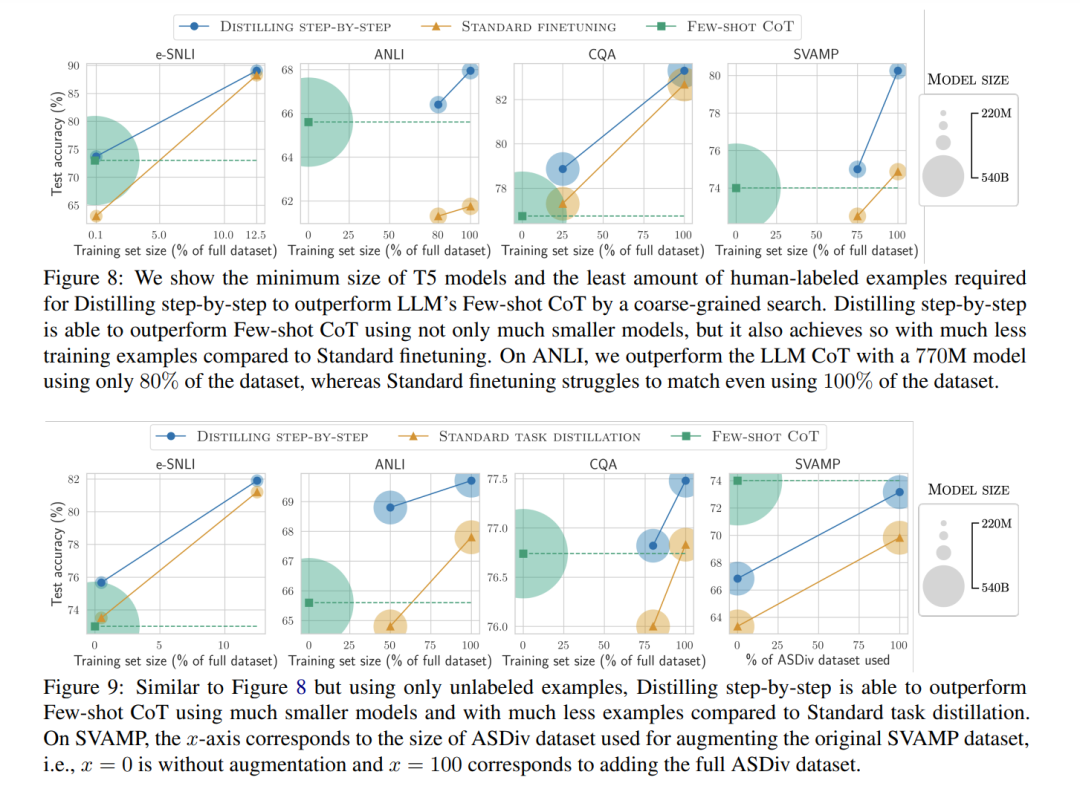
在这里,以LLM的性能作为锚点,我们探讨了逐步蒸馏方法和标准微调/蒸馏在超越LLM所需的最高效资源需求,包括训练样本数量和部署模型大小。我们分别在图8和图9中呈现了在人类标注设置和无标注设置下的结果。我们通过绘制不同结果模型的(1)使用的训练样本数量(x轴),(2)实现的最终任务性能(y轴)以及(3)模型大小(通过阴影区域的大小可视化)来展示结果。
逐步蒸馏方法在使用更少数据的情况下,使用更小的模型超过LLMs。在图8中的所有数据集上,我们发现逐步蒸馏方法在使用更少的数据时,性能优于PaLM的少样本CoT,在只使用部分可用训练样本的情况下,使用更小的T5模型。具体来说,在e-SNLI上,逐步蒸馏方法可以在模型大小减小2000倍(220M T5)且只使用完整数据集的0.1%的情况下,实现比少样本CoT更好的性能。在图9中,只有无标签数据集可用时,我们观察到同样的趋势,即逐步蒸馏方法在大多数情况下,可以使用更小的模型和更少的数据超过少样本CoT。例如,在ANLI上,逐步蒸馏方法在模型缩小45倍且只使用完整无标签集50%的情况下,超过了LLM。标准微调和蒸馏需要更多的数据和更大的模型。最后,在图8和图9中,我们看到标准微调和蒸馏通常需要更多的数据或更大的模型来匹配LLM的性能。例如,在图8中的e-SNLI上,我们观察到逐步蒸馏方法在只使用数据集的0.1%的情况下就超过了LLM,而标准微调需要更多的数据来匹配性能。此外,在图8中的ANLI上,我们观察到逐步蒸馏方法可以在只使用80%的训练集的情况下,使用770M模型超过PaLM,而标准微调即使使用完整数据集也难以匹配LLM,因此需要更大的模型来缩小性能差距。
4 结论
我们提出了逐步蒸馏方法,从LLMs中提取rationales作为有益的监督信息,以训练小型任务特定模型。我们展示了逐步蒸馏方法减少了训练数据集的需求,以创建任务特定的较小模型;它还减少了实现甚至超过原始LLM性能所需的模型大小。与现有方法相比,逐步蒸馏方法提出了一种资源高效的训练到部署范式。

