从此告别繁琐的模型微调,LLM-Adapters助力NLP任务快速高效微调!


大型语言模型(LLMs)的成功,如 GPT-3 和 ChatGPT,发起了许多替代方案的开发。这些替代方案通过使用特定于任务的数据(如 ChatDoctor)或指令数据(如 Alpaca),微调 LLMs 来提高性能。但是,其中最具吸引力的方法是基于 Adapter 的参数微调(PEFT),因为它只需要微调插入的外部参数,而不是整个与训练模型,就能获得不错的性能。
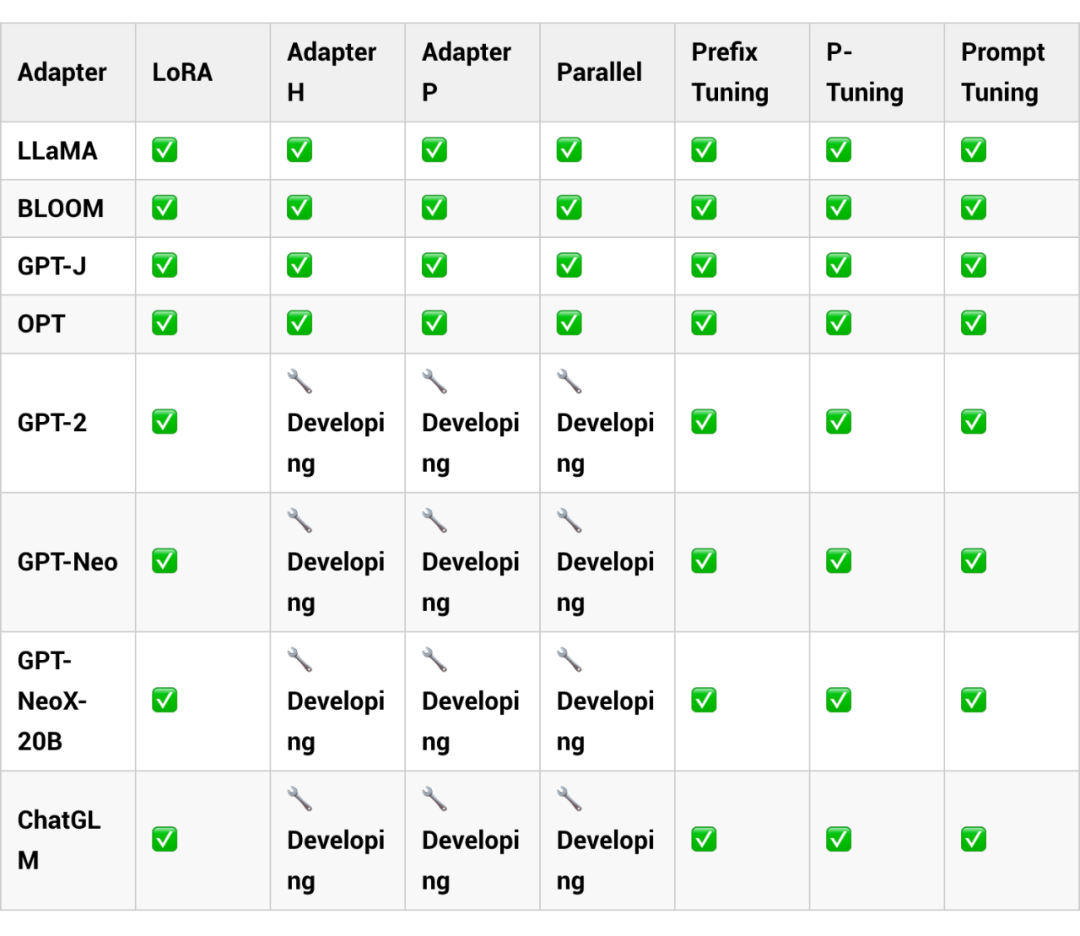
为了进一步研究 LLM 的 PEFT 方法,我们开发了一个易于使用的框架——LLM-Adapters,它将各种 Adapter 集成到 LLMs 中。该框架包括最先进的 LLMs,如 LLaMA、BLOOM 和 GPT-J 等模型,以及广泛使用的 Adapter,如 Series adapter、Parallel adapter 和 LoRA。同时,我们也会持续更新新的 LLMs 和 Adapter,以满足用户不断变化的需求。

项目名称:
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language
https://arxiv.org/abs/2304.01933
https://github.com/AGI-Edgerunners/LLM-Adapters

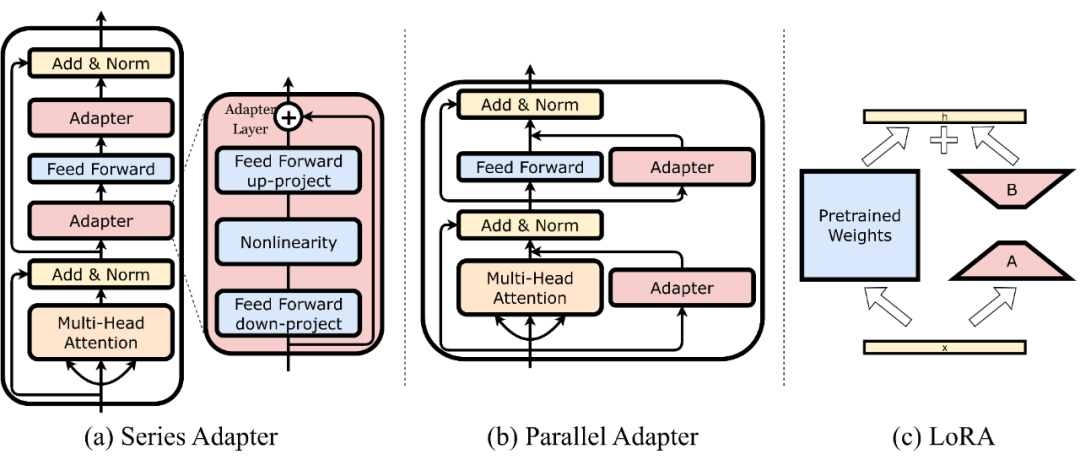
Adapters 是包含少量可训练参数并集成到 LLM中的外部模块。在训练期间,LLM 的参数保持固定,而 Adapter 模型的参数被调整以执行特定的任务。因此,由 LLM 生成的表示不会因任务特定的调整而扭曲,而 Adapter 模型则获得了编码特定任务信息的能力。
本框架在 LLM 中提出了三种 Adapter 类型:Series Adapter, Parallel Adapter 和 LoRA。我们将在之后的工作更新更多的 Adapter。
Series Adapter:受 [1] 的启发,我们的框架将瓶颈前馈层依次添加到 Transformer 的多头注意力层和前馈层。图(a)显示了瓶颈 Adapter 由两层前馈神经网络组成,包括一个下投影矩阵,一个非线性函数,和投影,以及输入和输出之间的残差连接
Parallel Adapter:将瓶颈前馈层与 LLMs 中 Transformer 的多头注意力层和前馈层并行集成。如图(b)所示,Adapter 与每个 Transformer 合并在一起
LoRA:[2] 提出了 LoRA,旨在用更少的可训练参数有效地微调预训练模型。LoRA 在 LLMs 的现有层中引入了可训练的低秩分解矩阵,使模型能够适应新的数据,同时保持原始 LLMs 固定以保留现有的知识。

数据集验证
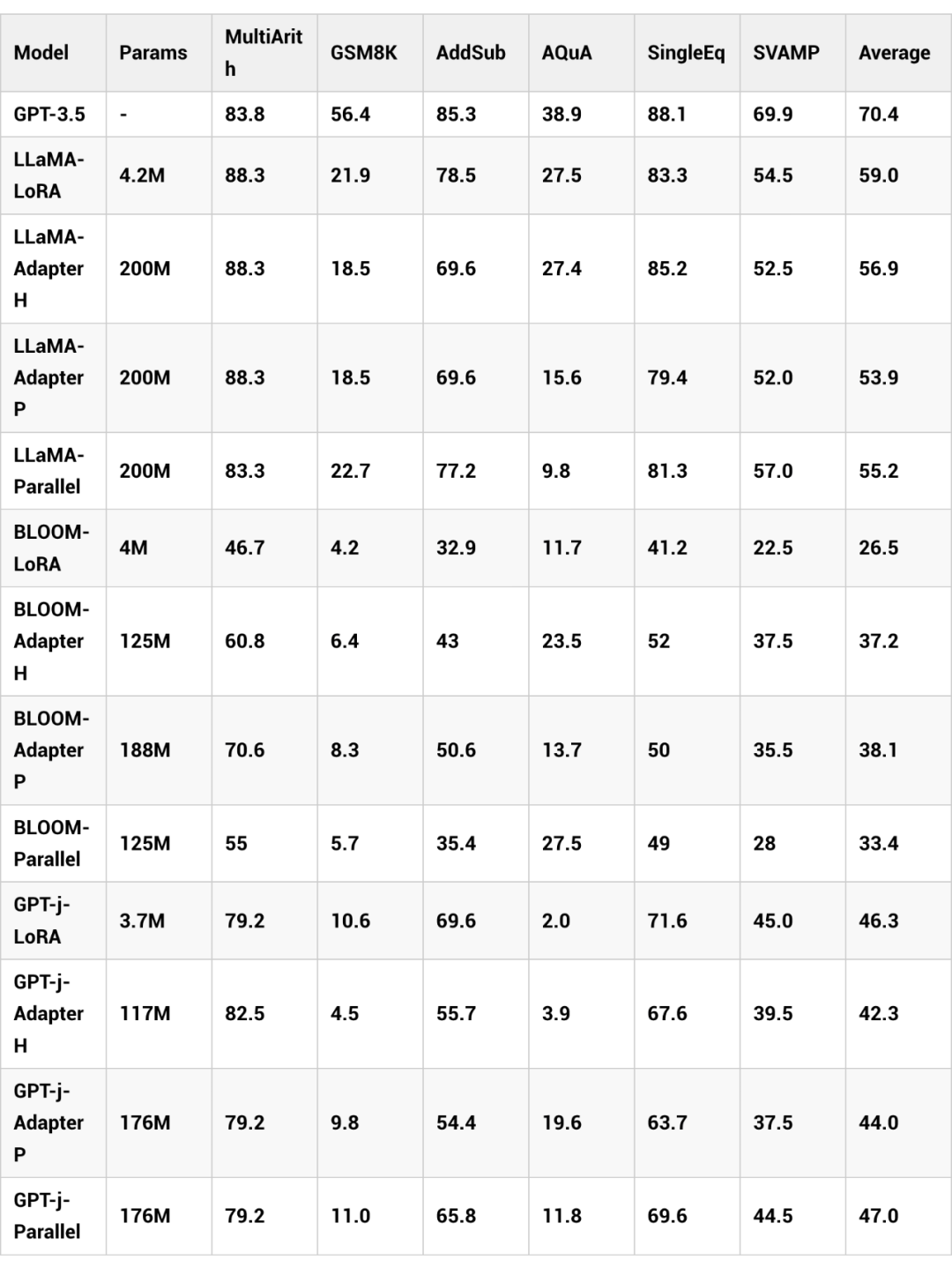
我们 6 个数学推理数据集上,测试不同 LLMs 参数高效微调的精度,6 个数据集分别是:(1)MultiArith;(2)GSM8K;(3)AddSub;(4)AQuA;(5) SingleEq;(6)SVAMP.

未来规划
在任务和数据集上:我们计划进一步扩展我们的推理任务,尽可能多的收集数据集
在 Adapter 上:我们将整合更多类型的 Adapter,并在大语言模型上测试

参考文献
[1] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR. 2,3,4
[2] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685. 2,3,4

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


