
原创作者:赵伟翔,赵妍妍,陆鑫,王世龙,童彦澎,秦兵
转载须标注出处:哈工大SCIR引言
情感对话技术旨在赋予对话机器人类似人类的情感,使它们具备识别、理解和表达情感的能力,从而为用户提供更为人性化和多样化的回复。让计算机具备“情商”可以说是人工智能领域的更高追求。人工智能之父马文·明斯基(Marvin Minsky)在其著作《情感机器》[1]中指出:“只具备智力而无情感的人工智能,并非真正的智能。这表明对话机器人不仅需要“智商”,还要具备“情商”。因此,研发具备情感功能的对话机器人成为学术界和产业界共同关注的课题。近年来,产业界的许多对话机器人产品都增加了情感功能,以提高产品的趣味性和人性化,例如微软的小冰、小黄鸡聊天机器人等。情感对话技术成为了提升这些应用产品(如闲聊机器人[2]、智能客服[3]、语音助手[4]等)性能的核心技术。通过在这些产品中加入情感对话技术,可以使得机器人更好地理解用户的需求和情感,从而提供更为贴近用户心理的服务。随着ChatGPT[5]的问世,对话机器人领域迎来了革新。作为一款先进的大型语言模型,ChatGPT为对话机器人带来了更为丰富且精确的语义理解和回复生成能力,极大地提升了与人类用户的交互体验。考虑到ChatGPT在基本对话技术方面的重要突破,以及近期研究分析了其在各项传统自然语言处理任务中的表现[6, 7],我们对ChatGPT在情感对话技术发展方面的影响产生了兴趣。因此,在本文中,我们将探讨ChatGPT在情感对话领域的多个任务上的性能表现,分析其优缺点,并思考情感对话领域未来的研究方向。
任务设置
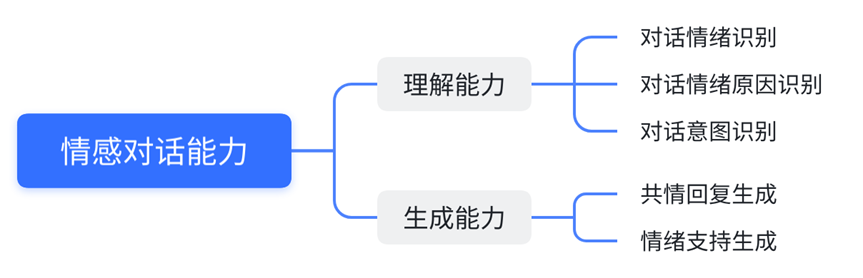
我们将从情感对话理解和生成能力这两个维度出发,对ChatGPT在其下各个主流任务的性能表现进行比较和分析。评测方法对于各个任务上的SOTA模型,我们直接引用了其原论文的实验结果,而ChatGPT的性能测试则全部使用OpenAI开放API的"gpt-3.5-turbo"模型(截止至3.8日的模型版本)。我们测试了ChatGPT在各个任务上零式学习(Zero-shot Learing)和上下文学习(In-context Learning)的表现。
评测详情
对话情绪识别
任务定义
对话情绪识别是一个分类任务,旨在对一段对话中的话语进行情绪分类。任务的输入是一段连续的对话,输出是这段对话中所有话语的情绪,图1给出了一个简单的示例。对话中的话语情绪识别并不简单等同于单个句子的情绪识别,需要综合考虑对话中的背景、上下文、说话人等信息。对话情绪识别可广泛应用于各种对话场景中,如社交媒体中评论的情感分析、人工客服中客户的情绪分析等。此外,对话情绪识别还可应用于聊天机器人中,实时分析用户的情绪状态,实现基于用户情感驱动的回复生成。
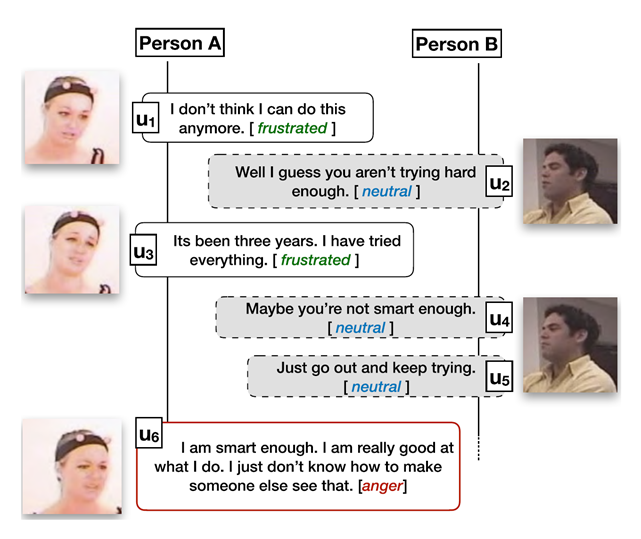
图1. 对话情绪识别示例[8]
数据集介绍
IEMOCAP
[9]南加州大学SAIL实验室收集,由人扮演的双人对话,12小时的多模态视听数据。10个专业演员(5男5女),一共分为5个Session,每个Session分配1男1女。对话分为两部分,一部分是固定的剧本,另一部分是给定主题情景下的自由发挥。151段对话,共7433句。标注了6类情绪:Neutral, Happiness, Sadness, Anger, Frustrated, Excited,非中性情绪占比77%。IEMOCAP是对话情绪识别中常用的数据集之一,质量较高,优点是有多模态信息,缺点是数据规模较小。本次测试仅使用其文本模态数据。数据集链接:https://sail.usc.edu/iemocap/MELD[10]来源于老友记,多人对话形式,是EmotionLines[11]老友记部分的多模态扩充(文本+视频)。1432段对话,共13708句。标注了7类情绪:Neutral, Happiness, Surprise, Sadness, Anger, Disgust, Fear和3类情感:Positive, Negative, Neutral,非中性情绪占比53%。MELD是对话情绪识别中常用的数据集之一,优点是数据集质量较高,缺点是数据集中的对话涉及到的剧情背景太多,情绪识别难度很大。本次测试仅使用其文本模态数据。数据集链接:https://affective-meld.github.io/EmoryNLP[12]来源于老友记,多人对话形式。897段对话,共12606句。标注了7类情绪:Sad, Mad, Scared, Powerful, Peaceful, Joyful, Neutral,非中性情绪占比70%。EmoryNLP是对话情绪识别中常用的数据集之一,由于和MELD来源相同,故优缺点与MELD数据集类似。数据集链接:https://github.com/emorynlp/emotion-detectionDailyDialog[13]高质量多轮对话数据集,纯文本,噪声小,对话反映不同主题的日常生活,无固定说话人。数据集除了7类情绪标注,还有10类主题标注以及4类对话行为标注。13118段对话,共102979句。标注了7类情绪:Neutral, Happiness, Surprise, Sadness, Anger, Disgust, Fear,非中性情绪占比16.8%。DailyDialog是对话情绪识别中常用的数据集之一,优点是数据规模较大,缺点是中性情绪占比过高。数据集链接:http://yanran.li/dailydialog评价指标介绍对于IEMOCAP、MELD和EmoryNLP数据集,目前大部分论文使用Weighted-F1指标进行评价;对于DailyDialog数据集,由于其中性占比实在太高,目前大部分论文都使用不考虑中性类别的Micro-F1指标进行评价。
主实验结果
下面是主实验结果,从中可以看出ChatGPT相比于最先进的微调模型普遍还有10—20百分点的性能差距。模型IEMOCAPMELDEmoryNLPDailyDialogCoMPM[14] (NAACL 2022)69.4666.5238.9360.34SPCL[15] (EMNLP 2022)69.7467.2540.94—ChatGPT, 0-shot44.9757.3037.4740.66ChatGPT, 1-shot47.4658.6335.6042.00ChatGPT, 3-shot48.5858.3535.9242.39
案例展示
下面是从DailyDialogue数据集中找到的一段对话数据,模拟了医生和病人的对话场景,我们将其翻译成中文展示。说话人对话内容数据集标注ChatGPT预测A早上好。你怎么了?中性中性B早上好,医生。我头疼得厉害。中性难过A好的,年轻人。告诉我它是怎么开始的。中性中性B昨天我流鼻涕,现在我鼻塞了,喉咙痛,恐怕我发烧了。我感觉很糟糕。中性难过A别担心,年轻人。让我给你做个检查。首先让我看看你的喉咙。张开嘴说“啊”。中性中性B啊。中性中性A你的喉咙发炎了。你的舌头上有厚厚的舌苔。你有流感的症状。中性恐惧B那我该怎么办?中性恐惧A你只需要好好休息,多喝水。我给你开药方。中性积极B非常感谢。中性积极
分析与讨论
案例展示部分中,我们将数据集可能的标注错误用红色字体展示,将ChatGPT扭转了标注错误用绿色字体展示;另外ChatGPT预测结果中还有黄色字体的标签,这是我们额外发现的问题:ChatGPT与数据集规范不匹配问题。从这部分实际预测样例看,ChatGPT做不好的最大问题是它的标准与数据集的标准有偏差。数据集标注时可能按一种标注规范来确定什么情况是什么情绪,而ChatGPT自己有一套理解和规范。具体来说,在上面医生和病人的对话中,病人在描述自己头疼症状时,数据集标注的是中性,而ChatGPT则认为这是难过,这个不能说是谁对谁错,而是两者认识的标准不同。更进一步讨论,这种标准的不匹配可能并不是ChatGPT能力的问题,而是Few-Shot设定的问题。因为当标注规范细致繁琐到一定程度后,就已经不可能仅由几个示例覆盖了,这是Few-shot天然所不能做好的事情。基于此可对未来方向有所推测:如果是不追求与特定规范严格对齐的场景,那么基于ChatGPT等Few-Shot设定下的改进是可行的,但是使用数据集标签评价是不合适的,可能需要广泛的人工评价;如果是追求与特定规范严格对齐的场景,Few-Shot设定可能并不是一个好的选择,有监督微调模型仍然是更好的方案。
对话情绪原因识别
任务定义
对话情绪原因识别,旨在找出一段对话中,引起目标句情绪的原因。任务的输入是一段连续的对话和目标句,输出引发目标句情绪的原因。在这里,情绪原因有两种存在形式,分别为句子级情绪原因和词组级情绪原因,图2给出了一个简单的示例。这本次测试中,我们仅关注在对句子级情绪原因的识别。

图2 对话情绪原因识别示例
数据集介绍
我们在基准数据集RECCON-DD[16]上进行了实验。它是在对话情绪识别数据集DailyDialog[13]的基础上,进行情绪原因的标注。我们只考虑存在于对话上文中的情绪原因,并且重复的因果语句被删除。数据集链接:https://github.com/declare-lab/RECCON评价指标介绍我们分别对负例和正例因果对计算F1值,以及计算二者的macro-F1值。
主实验结果
模型Neg. F1Pos. F1Macro F1KBCIN[17] (AAAI 2023)89.6568.5979.12ChatGPT 0-shot85.2551.3368.29ChatGPT 1-shot82.1052.8467.47
分析与讨论
对于 ChatGPT 的错误案例分析,可以发现其在 Pos. F1 上的性能与 SOTA 存在较大差距的原因在于数据集中有大量情绪原因样本存在于目标句本身。ChatGPT 未能对这种样例进行正确的预测,而更偏向于从对话上文中寻找原因语句。这一现象与上述对话情绪识别的分析是相符的。ChatGPT 的性能不佳的最大问题在于其预测标准与数据集的标注标准存在很大偏差。在给定一个示例后,ChatGPT 的性能下降进一步表明,对于情绪原因这类标注规范较为复杂的任务,充分发挥 ChatGPT 性能的关键是使其能够深刻理解数据集构建时的规范,从而冲破其自身的语言模型先验,以获得更符合下游测试数据的性能表现。
对话动作识别
任务定义
为对话中的每一个轮次,都进行一次对话动作的分类,是一个四分类任务,我们认为每一个轮次都完成了一个对话动作,动作标签集合:{告知(inform), 提问(question), 指示(directive), 承诺(commissive)},对话动作的理解能力是对话情感理解能力的一个重要组成部分。
数据集介绍
采用DailyDialog[13]作为实验数据集,相关介绍同对话情绪识别。评价指标介绍分类任务多采用weighted-F1与macro-F1作为评测指标,本任务中,ChatGPT会给出四分类以外的无意义标签,严重拉低宏平均值,故采用加权平均f1值作为评价指标。
主实验结果
ModelAccweighted-F1Co-GAT-0.79ChatGPT, oneshot0.670.65ChatGPT, oneshot+prompt-engineering0.710.70ChatGPT, fewshot0.730.71ChatGPT, fewshot+prompt-engineering0.730.72
案例展示
下面是测试数据集中的一个数据实例,对话翻译成中文展示如下。说话人话语ChatGPT预测标签真实标签A我们什么时候才能盼到你来吃晚餐?今天能来吗?提问指示B不行。我答应和我的妹妹去听音乐会了。告知承诺A好吧...那周日怎么样?提问指示B那听起来不错。承诺承诺分析与讨论ChatGPT对于指示、承诺这两类标签的理解能力较差,经常将提问与指示,告知与承诺混淆,正如案例所示。这是两个难以区分的标签,如果没有明显的定义区别,它们之间会有语义上的重叠:“今天能来吗”是一种引导性的问句,“我答应和我妹妹去音乐会了”是一种承诺性的告知。这不能说明ChatGPT的对话动作理解能力差,仍表现出ChatGPT的标签体系与数据集的标签体系存在差异。若在提示词中加入详细的标签解释(提示词工程),评价指标会有明显提升。从实验结果可以观察到:在本任务上,few-shot是一种对于ChatGPT最高效的提示词增强方式,无需复杂的提示词工程(本实验是对commissive和directive标签做了详细解释,具体见
任务提示模板
节),也能使得评价指标得到可观的提升。本实验的设定few-shot为3个样本,提示词工程也是简单地进行设计,我们有理由相信,在精细挑选更多示例,以及更精细化地做提示词工程,能进一步降低ChatGPT理解的标签体系与数据集原始标签体系的差异,从而进一步提升ChatGPT在该任务的上限,但与上述两个任务中提及的观点相似,这种追求与数据集标签体系对齐的评价体系仍然值得思考。共情回复生成****任务定义给定对话历史,模型将扮演倾听者的角色,设身处地理解用户处境,生成感同身受的共情回复。数据集介绍EmpatheticDialogues[19]:一个大规模的多轮双人共情对话数据集,包含了众包收集的24850段共情对话,并为每个对话提供了一个情绪标签(一共有32种分布均匀的情绪)。
数据集链接:https://github.com/facebookresearch/EmpatheticDialogues评价指标介绍自动评价指标:○Bleu-n (B-1, B-2, B-3, B-4)[20],Rouge-L (R-L)[21]:评估生成回复与参考回复的相似程度。○**Distinct-n **(D-1, D-2, D-3)[22]:评估生成回复的多样性。人工评价指标:我们采取了基于属性的成对人工偏好评价方式。具体来说,100对分别由DialoGPT和ChatGPT生成的回复语句被随机选取出来,2位志愿者依据以下三个方面挑选出哪一句回复更好:○流畅度:评价哪一条回复更流畅,与对话历史更相关。○共情能力:评价哪一条回复更共情,展现出对于用户状态和处境更好的理解。○信息量:评价哪一条回复展现出与对话历史相关的更多信息。
主实验结果
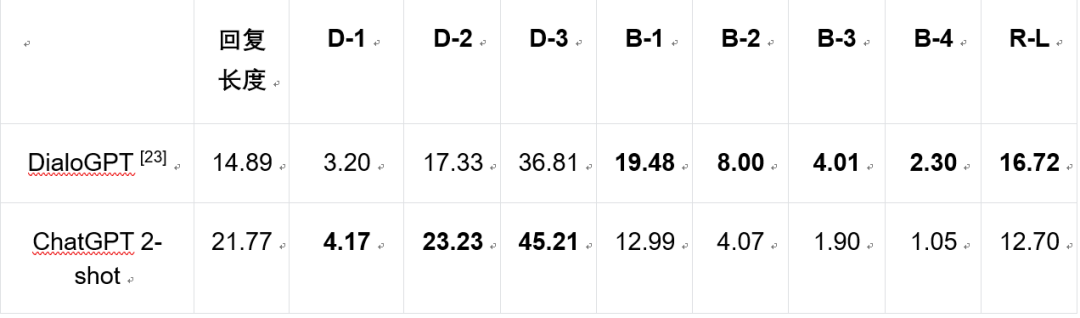
人工评价结果
WinLossTieEmpSOA [24] v.s ChatGPT流畅度844.547.5共情能力1053.536.5信息量98011分析与讨论在共情回复生成时,ChatGPT更倾向于生成更长更具多样性的回复。此外,其尤其倾向于提出建议解决用户面临的问题**,**从而与真实回复产生偏差。更进一步,从人工评价来看,SOTA方法的流畅度和共情能力勉强能够与ChatGPT相比,但回复的信息量相差甚远。ChatGPT生成的回复能够完全理解用户处境,回复质量也相当之高,从而明显优于目前的SOTA模型。但在共情能力方面,ChatGPT在表达共情时会频繁重复这样的模式:复述情绪➕信息扩展。反复循环着同样一种模式不免使得用户产生乏味。对于该任务的未来方向,首先一点是提升模型的个性化共情能力,模板且套路化的共情表达方式显然还未能够与真实的人类共情对话所对齐。其次,由自动评价和人工评价得到的模型性能差异化表现,进一步说明了目前仍缺乏一个合理的评价指标,来衡量共情对话系统的优劣。情绪支持对话****任务定义情绪支持对话是一个生成任务,旨在为处于消极情绪状态时,前来寻求帮助的求助者给予情绪支持。任务的输入为发生在求助者和支持者之间的双人对话历史,输出为生成的支持者轮次的情绪支持回复。情绪支持对话可以分为三个阶段:支持者需要(1)确定求助者所面临的问题,(2)安慰求助者,然后(3)提供一些建议或信息,以帮助求助者采取行动来应对他们的问题。支持者在此过程中可以使用以下8种策略,分别为:提问(Question), 复述或改述(Restatement or Paraphrasing), 反思感受(Reflection of Feelings), 自我揭示(Self-disclosure), 肯定和安慰(Affirmation and Reassurance), 提供建议(Providing Suggestions),信息(Information)和其他(Others)。
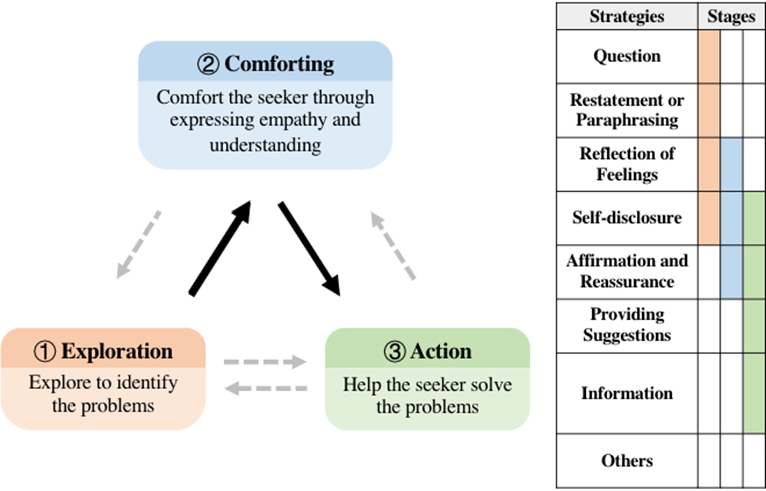
图3 情绪支持对话的三个阶段和各个阶段支持者使用的策略[25]
数据集介绍
数据集:ESConv[25]包含1,053段对话和31,410个句子。为了构建这个数据集,数据集作者招募了已经学会了提供情感支持的常用步骤和策略的支持者,通过一个在线平台与需要情感支持的志愿者进行交流。支持者被要求在每个回合中标注所采取的策略,而寻求支持的人则被要求每两个回合在Likert量表上给出反馈,该量表有五个等级,表明其消极情绪的缓解程度。数据集链接:https://github.com/thu-coai/Emotional-Support-Conversation评价指标介绍自动评价指标:○Bleu-n (B-1, B-2, B-3, B-4),Rouge-L (R-L):评估生成回复与参考回复的相似程度。○Distinct-n (D-1, D-2, D-3):评估生成回复的多样性。○ACC:预测策略的准确率。人工评价指标:我们招募了一名熟悉情绪支持对话的志愿者与模型进行交互,以进行人工评估。具体而言,我们从测试集中随机抽取了89段对话。然后,我们要求志愿者在这些对话场景下扮演求助者的角色,并与模型展开交流。对于MISC和ChatGPT,志愿者需要在以下五个方面进行评判(或判断两者表现相当),这些方面涵盖了情绪支持对话的三个阶段:○流畅度:哪个模型能产生更连贯和流畅的回应;○探索能力:哪个模型能更有效地探讨求助者的问题;○共情能力:哪个模型在理解求助者的感受和情况方面表现出更强的同理心;○建议能力:哪个模型能提供更有价值的建议;○总体表现:哪个模型能提供更有效的情感支持。主实验结果
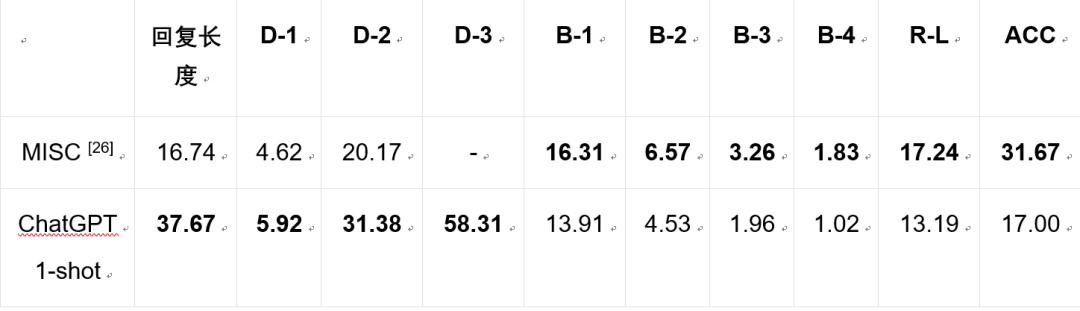
人工评价结果
WinLossTieMISC v.s ChatGPT流畅度63152探索能力63845共情能力****401633建议能力37313总体表现126512分析与讨论ChatGPT的生成内容仍保持着长而多样的特点,使其在自动评价指标Distinct-n上远超过SOTA方法。但多样性也带来了与真实回复的偏离。从人工评价结果来看,情绪支持对话的特点之一是为用户提供建议和有效信息以走出困境。这恰好符合ChatGPT的生成偏好,故在此任务上展示出优秀的效果。然而,在共情能力方面,SOTA方法优于ChatGPT的原因在于,ChatGPT太过“急于求成”,一旦确认用户所面临的困境,便立刻给出相应的建议和应对措施,忽略了对用户情绪的抚慰和关照。但这并不能说明ChatGPT不具有共情能力。其在共情回复生成任务中展现出的优秀表现能够证明,其能够设身处地安慰用户。通过适当的提示词工程,我们相信可以使ChatGPT“放慢节奏”,在给出用户建议前进行充分的情绪疏导。相比MISC,ChatGPT能展现出更多样化且更有效的建议,从而在建议能力方面远远超过现有模型。但这一点MISC无法通过现有数据集学习,因为语料中真实的建议本身就具有局限性。对于未来关于情绪支持对话的研究,如何使得模型自适应地控制情绪支持的节奏(不宜“操之过急”提出建议解决问题,也不宜“停滞不前”重复无效的安慰)是一个值得关注的研究点。此外,研究更合理的自动评价指标,以对齐与人工评价的差异,仍需要进一步探索。结论与展望经过对ChatGPT情感对话能力的初步探索,我们发现ChatGPT在情感对话理解和生成方面表现出色。需要注意的是,我们的实验结果可能无法完全反映ChatGPT在相应任务上的最佳表现。通过更加精细化的提示词工程和上下文示例选择,我们相信ChatGPT的性能可以进一步提高。未来的情感对话理解工作方向之一是探索ChatGPT与标签标注规范的对齐,而在情感对话生成方面,重要的是研究合理的自动评价指标以衡量模型能力,因为目前所广泛采用的自动评价和人工评价得到的性能表现可能会有所不同。
