CLUE社区最新神器!PromptCLUE:大规模多任务Prompt预训练中文开源模型
![]()
新智元报道

新智元报道
【新智元导读】CLUE社区又发布了一个新神器PromptCLUE,中文NLP也实现了Train Once,Run Everywhere!


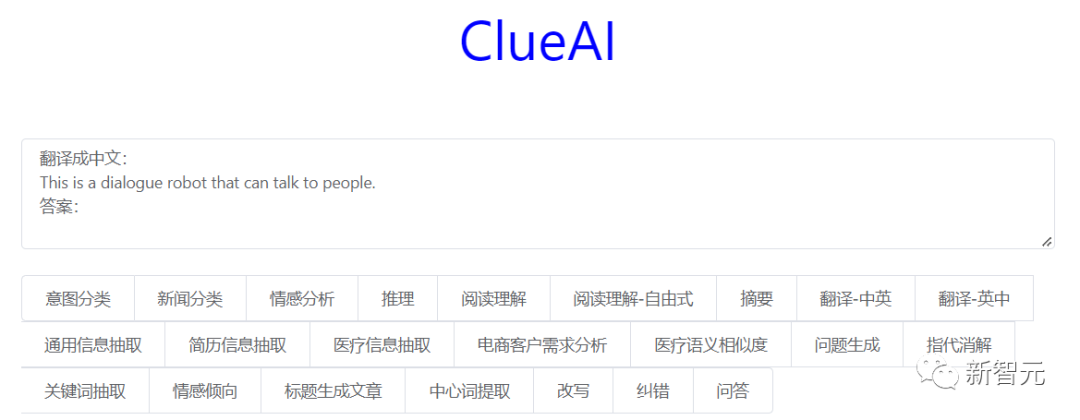

效果对比:16类中文任务
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
相关技术与训练过程
-
三大统一:统一模型框架(text-to-text),统一任务形式(prompt),统一应用方式(zero-shot/few-shot)。(T0)
-
大规模预训练:在t5-large版基础上,使用数百G中文语料,训练了100万步,累计训练了1.5万亿个中文字词级别token
-
大规模任务数据:使用了16种任务类型,数百种任务,累积亿级别任务数据
-
混合预训练:一方面将下游任务作为预训练语料,另一方面将下游任务和预训练语料一起训练,减少任务灾难遗忘以及缩短预训练和下游任务的距离,更好的适应下游任务(ExT5)
-
混合采样:针对众多数据量差异极大的任务,采用在每个训练batch内对所有的任务进行按照比例采样,根据任务的数据量进行平滑采样,并且同时限制任务数据量采样池的上限。平滑采样可以减少任务训练有偏危害,在每一batch内训练可以减少异质任务之间训练负迁移的情况(T5)
-
分阶段训练:一方面指在预训练分阶段,涉及训练序列长度的分阶段(128和512),加快预训练速度(Bert);另一方面,在下游训练分阶段, 涉及学习率和序列长度的变化以及递减式对下游任务的数据量限制,更好的适应下游的不同任务
-
增加语言模型的训练:参考t5.1.1, 除了使用Span Corrpution构建的方式进行无监督训练,同时在使用prefix LM的方式训练,增强生成任务的能力(LM adapted)
-
增加对模型的encoder以及decoder的训练:根据下游任务数据分别构建Data_text,Data_target预训练数据语料,是加入到预训练中,分别增强模型的encoder理解能力和 decoder的生成能力(见UIE)
-
重新构建模型中文字典:使用sentencepiece上在千亿token上学习并构建模型字典,更加符合中文语言习惯
License(许可证)
License(许可证)
使用方法
使用方法
git clone https://github.com/huggingface/transformers.gitpip install ./transformerspip install sentencepiece
from transformers import AutoTokenizer, AutoModelForSeq2SeqLMtokenizer = AutoTokenizer.from_pretrained("ClueAI/PromptCLUE-base")model = AutoModelForSeq2SeqLM.from_pretrained("ClueAI/PromptCLUE-base")
import torchfrom transformers import AutoTokenizer# 修改colab笔记本设置为gpu,推理更快device = torch.device('cuda')model.to(device)def preprocess(text):return text.replace("\n", "_")def postprocess(text):return text.replace("_", "\n")def answer(text, sample=False, top_p=0.6):'''sample:是否抽样。生成任务,可以设置为True;top_p:0-1之间,生成的内容越多样、'''text = preprocess(text)encoding = tokenizer(text=[text], truncation=True, padding=True, max_length=768, return_tensors="pt").to(device)if not sample: # 不进行采样out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_length=128, num_beams=4, length_penalty=0.6)else: # 采样(生成)out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_length=128, do_sample=True, top_p=top_p)out_text = tokenizer.batch_decode(out["sequences"], skip_special_tokens=True)return postprocess(out_text[0])
支持的任务(部分)
意图分类, 新闻分类, 情感分析, 自然语言推理, 阅读理解, 阅读理解-自由式, 摘要, 翻译-中英, 翻译-英中, 通用信息抽取, 简历信息抽取, 医疗信息抽取电商客户需求分析, 医疗语义相似度, 问题生成, 指代消解, 关键词抽取, 情感倾向, 根据标题文章生成, 知识图谱问答, 相似句子生成/改写, 纠错, 中心词提取.....
使用自定义数据集进行训练-PyTorch实现
使用pCLUE数据集进行训练、预测和效果验证。
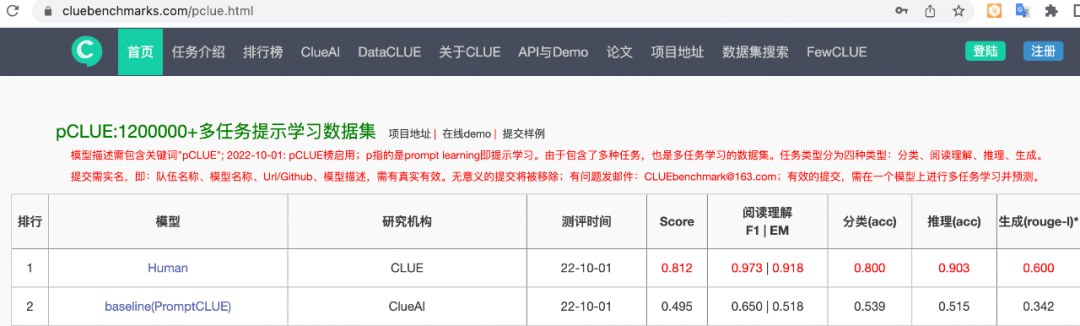
pCLUE基准上的效果
示例输入
示例输入
新闻分类(classify)
Input:分类任务:折价率过低遭抛售基金泰和跌7.15%,证券时报记者 朱景锋本报讯 由于折价率在大盘封基中处于最低水平,基金泰和昨日遭到投资者大举抛售,跌幅达到7.15%,远超大盘。盘面显示,基金泰和随大盘高开,之后开始震荡走低,午后开始加速下行,几乎没有像样反弹。截至收盘时,在沪深300指数仅下跌2.56%的情况下,基金泰和收盘跌幅高达7.15%,在所有封基中跌幅最大,而昨日多数封基跌幅在2%左右。选项:财经,娱乐,时政,股票答案:Model output:财经
意图分类(classify)
Input:意图分类:帮我定一个周日上海浦东的房间选项:闹钟,文学,酒店,艺术,体育,健康,天气,其他答案:Model output:酒店
情感分析(classify)
Input:情感分析:这个看上去还可以,但其实我不喜欢选项:积极,消极答案:Model output:消极
推理(generate)
Input:请推理出上下文的关系:前提:对不起事情就是这样。假设:事情就是这样,不需要道歉。选项:中立,蕴涵,矛盾答案:Model output:矛盾
阅读理解(generate)
Input:阅读文章,给出答案:段落:港汇指数,全称港元实际汇兑指数(Effective Exchange Rate Index for the Hong Kong Dollar)是由香港政府统计处编制的一项指数,以反映港元与香港主要贸易伙伴之货币的名义有效汇率加权平均数的变动情况。加权比重是按1999年至2000年平均贸易模式所制定,但政府并未有公布详细的计算公式。旧港汇指数基准日为2000年1月1日,基数为100点。由2012年1月3日起,新系列港汇指数 (包括15种货币及以2010年1月 = 100) 已取代旧港汇指数系列。港汇指数的作用,主要是用于反映香港的货品及服务的价格相对于其主要贸易伙伴的变动,并通常被视作反映香港价格竞争力的指标。问题:港汇指数的加权比重如何制定?答案:Model output:按1999年至2000年平均贸易模式所制定
阅读理解-自由式(generate)
Input:阅读以下对话并回答问题。男:今天怎么这么晚才来上班啊?女:昨天工作到很晚,而且我还感冒了。男:那你回去休息吧,我帮你请假。女:谢谢你。问题:女的怎么样?选项:正在工作,感冒了,在打电话,要出差。答案:Model output:感冒了
摘要(generate)
Input:为下面的文章生成摘要:北京时间9月5日12时52分,四川甘孜藏族自治州泸定县发生6.8级地震。地震发生后,领导高度重视并作出重要指示,要求把抢救生命作为首要任务,全力救援受灾群众,最大限度减少人员伤亡答案:Model output:四川甘孜发生6.8级地震
翻译-中英(generate)
Input:翻译成英文:议长去了台湾,中国人民很愤怒。答案:Model output:The secretary went to Taiwan and the Chinese people were angry.
翻译-英中(generate)
Input:翻译成中文:This is a dialogue robot that can talk to people.答案:Model output:这是一台可以与人交谈的对话机器人。
通用信息抽取(generate)
Input:信息抽取:据新华社电广东省清远市清城区政府昨日对外发布信息称,日前被实名举报涉嫌勒索企业、说“分分钟可以搞垮一间厂”的清城区环保局局长陈柏,已被免去清城区区委委员问题:机构名,人名,职位答案:Model output:机构名:新华社,清城区政府,清城区环保局,清城区区委人名:陈柏职位:局长,区委委员
简历信息抽取(generate)
Input:阅读文本抽取关键信息:张玄武2000年出生中国国籍无境外居留权博士学历现任杭州线锁科技技术总监。问题:机构,人名,职位,籍贯,专业,国籍,学历,种族答案:Model output:人名:张玄武职位:杭州线锁科技技术总监国籍:中国国籍学历:博士学历
医疗信息抽取(generate)
Input:从文本中抽取信息:我胃部不舒服,前几天去医院做B超,医生说我有胃炎问题:症状,检查,身体,疾病答案:Model output:检查:B超身体:胃部
电商客户需求分析(classify)
Input:电商客户诉求分类:收到但不太合身,可以退换吗选项:买家咨询商品是否支持花呗付款,买家表示收藏关注店铺,买家咨询退换货规则,买家需要商品推荐答案:Model output:买家咨询退换货规则
医疗语义相似度(classify)
Input:下面句子是否表示了相同的语义:文本1:糖尿病腿麻木怎么办?文本2:糖尿病怎样控制生活方式选项:相似,不相似答案:Model output:不相似
问题生成(generate)
Input:问题生成:中新网2022年9月22日电 22日,商务部召开例行新闻发布会,商务部新闻发言人束珏婷表示,今年1-8月,中国实际使用外资1384亿美元,增长20.2%;其中,欧盟对华投资增长123.7%(含通过自由港投资数据)。这充分表明,包括欧盟在内的外国投资者持续看好中国市场,希望继续深化对华投资合作。答案:Model output:1、商务部发言人束珏婷表示,中国去年1-8月实际使用外资1384亿美元,增长20.2%,其中欧盟对华投资增长多少?2、欧盟对华投资的增长是否达到预期?3、欧盟在对华投资合作方面取得什么样的成果?
指代消解(generate)
Input:指代消解:段落:少平跟润叶进了她二爸家的院子,润生走过来对他(代词)说:“我到宿舍找了你两回,你到哪里去了?”问题:代词“他”指代的是?答案:Model output:少平
关键词抽取(generate)
Input:抽取关键词:当地时间21日,美国联邦储备委员会宣布加息75个基点,将联邦基金利率目标区间上调到3.00%至3.25%之间,符合市场预期。这是美联储今年以来第五次加息,也是连续第三次加息,创自1981年以来的最大密集加息幅度。关键词:Model output:美联储,利率目标区间,加息,基点
情感倾向(classify)
文字中包含了怎样的情感:超可爱的帅哥,爱了。。。选项:厌恶,喜欢,开心,悲伤,惊讶,生气,害怕答案:Model output:喜欢
技术交流和问题反馈




登录查看更多
相关内容
专知会员服务
21+阅读 · 2019年12月12日
Arxiv
0+阅读 · 2022年12月21日
Arxiv
0+阅读 · 2022年12月21日
Arxiv
0+阅读 · 2022年12月21日
Arxiv
15+阅读 · 2018年10月11日


相关VIP内容
专知会员服务
21+阅读 · 2019年12月12日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年12月21日
Arxiv
0+阅读 · 2022年12月21日
Arxiv
0+阅读 · 2022年12月21日
Arxiv
15+阅读 · 2018年10月11日