

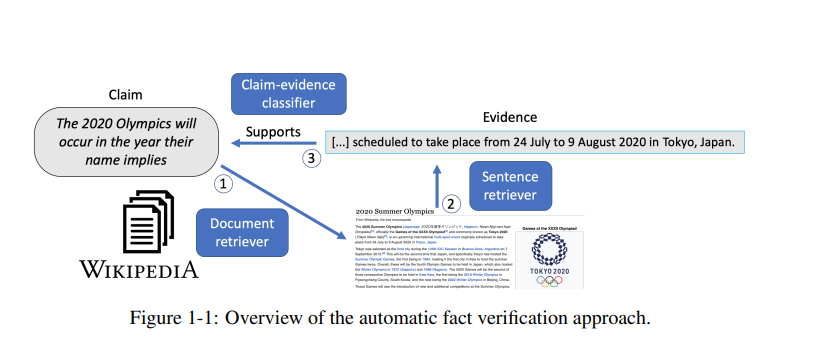
深度学习模型最近彻底改变了在线环境,为改善用户体验打开了许多令人兴奋的机会。然而,这些模型也可能通过故意或恶意用户制造或推广虚假信息来引入新的威胁。在这篇论文中,我们提出了新的方法来对抗网上虚假信息的扩散。我们专注于自动事实验证的任务,即根据外部可靠来源检查给定索赔的准确性。我们分析了事实验证系统所需的规范,并描述了对大量全面的免费文本信息资源进行操作时对效率的需求,同时确保对具有挑战性的输入的鲁棒性和对参考证据修改的敏感性。我们的方法是通用的,正如我们所证明的,提高了事实验证之外的许多其他模型的稳健性、效率和可解释性。
在本文的第一部分,我们重点研究了句子对分类器的鲁棒性、敏感性和可解释性。我们提出了在大型策划数据集中识别和量化特性的方法,这些方法不希望导致模型依赖于不可普遍化的统计线索。我们演示了对比证据对如何通过强制模型执行句子对推理来缓解这一问题。为了自动获得这些例子,我们开发了一种新的基于原理的去噪管道,用于修改反驳证据以同意给定的主张。此外,我们提出了一个半自动的解决方案,从维基百科修订中创建对比对,并共享一个新的大型数据集。
在第二部分中,我们转向提高证据检索和声明分类模块的推理效率,同时可靠地控制它们的准确性。我们引入了新的置信度测度,并对共形预测框架进行了新的扩展。我们的方法可以为每个输入动态分配所需的计算资源,以满足任意用户指定的容忍水平。我们在多个数据集上演示了我们经过良好校准的决策规则可靠地提供了显著的效率提高。
https://dspace.mit.edu/handle/1721.1/140022




成为VIP会员查看完整内容
相关内容

麻省理工学院(Massachusetts Institute of Technology,MIT)是美国一所研究型私立大学,位于马萨诸塞州(麻省)的剑桥市。麻省理工学院的自然及工程科学在世界上享有极佳的盛誉,该校的工程系曾连续七届获得美国工科研究生课程冠军,其中以电子工程专业名气最响,紧跟其后的是机械工程。其管理学、经济学、哲学、政治学、语言学也同样优秀。
Arxiv
0+阅读 · 2022年9月7日
Arxiv
0+阅读 · 2022年9月2日
相关主题


相关VIP内容
相关资讯