AI系统如何可信?CMU-Nicholas博士论文《以模型为中心的人工智能验证》200页阐述增强AI系统信任度以确保安全部署运行

来源:专知
本文约3242字,建议阅读6分钟
本文介绍
了《以模型为中心的人工智能验证》。
人工智能系统落地应用不仅需要考虑准确性,还需考虑其他维度,如鲁棒性、可解释性等,即要构建负责任的人工智能。CMU的Nicholas Gisolfi的博士论文《Model-Centric Verification of Artificial Intelligence》探究训练模型的正式验证是否可以回答关于真实世界系统的广泛现实问题。提出方法适用于那些在特定环境中最终负责确保人工智能安全运行的人。值得关注!

摘要:
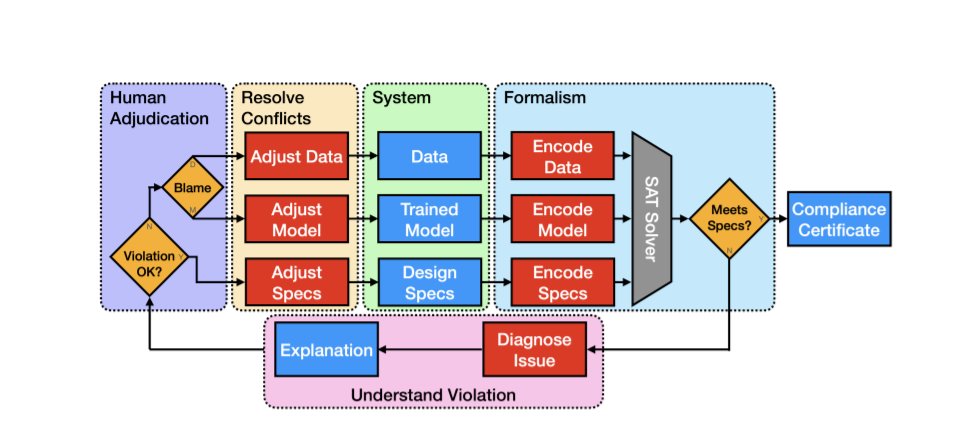
这项工作展示了如何在人工智能(AI)系统的背景下使用可证明的保证来补充概率估计。统计技术测量模型的预期性能,但低错误率并不能说明错误表现的方式。对模型是否符合设计规范的正式验证可以生成证书,该证书明确地详细说明了违规发生时的操作条件。这些证书使人工智能系统的开发人员和用户能够按照合同条款对其训练的模型进行推理,消除了由于不可预见的故障导致模型失效而造成本可以很容易预防的伤害的机会。为了说明这个概念,我们展示了名为Tree Ensemble itor (TEA)的验证流程。TEA利用我们的新布尔可满足性(SAT)形式,为分类任务的投票树集成模型提供支持。与相关的树集合验证技术相比,我们的形式化产生了显著性的速度增益。TEA的效率允许我们在比文献中报道的更大规模的模型上验证更难的规范。
在安全背景下,我们展示了如何在验证数据点上训练模型的局部对抗鲁棒性(LAR)可以纳入模型选择过程。我们探索了预测结果和模型鲁棒性之间的关系,允许我们给出最能满足工程需求的LAR定义,即只有当模型做出正确的预测时,它才应该是鲁棒的。在算法公平的背景下,我们展示了如何测试全局个体公平(GIF),包括数据支持内和数据支持外。当模型违反GIF规范时,我们列举了该公式的所有反例,以便揭示模型在训练过程中所吸收的不公平结构。在临床环境中,我们展示了如何简单地通过调整树集合的预测阈值来满足安全优先工程约束(SPEC)。这促进了预测阈值的帕累托最优选择,这样就不能在不损害系统安全性的情况下进一步减少误报。
本论文的目标是探究训练模型的正式验证是否可以回答关于真实世界系统的广泛的现有问题。我们的方法适用于那些在特定环境中最终负责确保人工智能安全运行的人。通过对训练过的树集合进行验证(V&V),我们希望促进AI系统在现实世界的落地应用。
https://www.ri.cmu.edu/publications/model-centric-verification-of-artificial-intelligence/
动机