结合符号主义和深度学习,DeepMind提出新型端到端神经网络架构 PrediNet
机器之心报道
参与:路、张倩
DeepMind 最近的一项研究将符号人工智能和深度学习结合起来,提出了一种新型端到端神经网络架构 PrediNet。

符号主义和连接主义是人工智能领域中的两大流派。符号主义(Symbolism)是一种基于逻辑推理的智能模拟方法,又称为逻辑主义 (Logicism)、心理学派 (Psychlogism) 或计算机学派 (Computerism),其原理主要为物理符号系统(即符号操作系统)假设和有限合理性原理。符号主义认为人工智能起源于数理逻辑,人类认知(智能)的基本元素是符号(symbol),认知过程是符号表示上的一种运算。连接主义 (connectionism),又称为仿生学派 (bionicsism) 或生理学派 (physiologism),其主要原理为神经网络及神经网络间的连接机制与学习算法。
人工智能发展早期,符号主义占据主要地位。而 20 世纪 90 年代后连接主义发展迅猛,其代表方法是神经网络,利用多层神经网络的深度学习当然属于连接主义。
符号主义和连接主义的关系很微妙,关于二者的争论也很多。然而 DeepMind 最近的一项研究将符号人工智能和深度学习结合起来,取二者之长,提出了一种新型端到端神经网络架构 PrediNet。
PrediNet 可以通过学习形成命题表征(propositional representation),该表征具备来自原始像素数据的显式关系结构。为了评估和分析该架构,DeepMind 研究者使用了一组简单的视觉关系推理任务,这些任务复杂度各不相同。实验结果表明,新架构在此类任务上进行预训练时,能够学习生成可重用的表征,从而在新任务上取得了比基线模型更好的后续学习效果。
通用、可重用表征的重要性
人类在面对新问题时,能够有效地利用之前的经验来做参考,而那些经验虽然与现在的问题看似大相径庭,但在更抽象、结构化的层级上是有相似之处的。人类的这一能力对于终生持续学习是必要的,并且它使人类具备数据有效性(data efficiency)、迁移学习能力和目前机器学习无法匹敌的泛化能力。而设计能够学习构建通用、可重用表征的系统这一挑战集聚了以上所有问题。这类表征是通用且可重用的,因此其所包含信息的应用领域超出其来源语境。
此类表征能够提升数据有效性,因为已经了解如何构建新任务相关表征的系统无需再从头学习新任务。理想情况下,高效利用此类通用、可重用表征的系统应该与构建此类表征的系统相同。此外,在使用此类表征学习解决新任务的过程中,我们应该期望该系统能够进一步学习本身即通用且可重用的表征。因此,除了系统学习的第一批表征以外,系统的其他所有学习实际上都是迁移学习,学习的过程是累积、持续的,而且是终身学习的过程。
如何创建能够学习构建此类表征的系统?
构建此类系统的一个方法是从经典的符号人工智能 [9] 吸取灵感。经典符号人工智能系统基于一阶谓词演算(first-order predicate calculus)的数学基础而构建,它将逻辑推论规则应用到语言命题表征中,后者的元素是对象和关系。由于命题表征是陈述式的,且结构是组合式的,因此它们自然而然地具备泛化性和可重用性。但是,与目前的深度学习系统不同,用于经典符号人工智能的表征通常不是从数据中学习得到的,而是手动获取的。
DeepMind 的这项研究旨在将经典符号人工智能和深度学习结合起来,它使用的是一个端到端可微神经网络架构 PrediNet,该架构基于命题关系先验而构建,这与卷积网络基于空间和位置先验而构建类似。
PrediNet 架构借鉴了近期的多项研究,如学习发现和利用关系信息的 non-local 网络架构 [25]、关系网络 [22, 18],以及基于多头注意力的架构 [24, 26]。但是,这些架构生成的表征不具备显式结构。通常,从表征的部分到符号方法(如谓词演算)的常见元素(如命题、关系和对象)之间是没有直接映射的。这些元素散落在嵌入向量中,很难解释,从而使得下游处理很难利用语义合成性(compositionality)。而 DeepMind 提出的新架构 PrediNet 学习到的表征部分可以直接映射到命题、关系和对象。
模型架构
PrediNet(图 1)可以看做一个三阶段的流程:注意力、绑定(binding)和评估。注意力阶段选择感兴趣的对象对;绑定阶段利用所选的对象对,实例化一组三位谓词(关系)的前两个参数;评估阶段计算每个谓词的剩余(标量)参数的值,以使得出的命题为真。
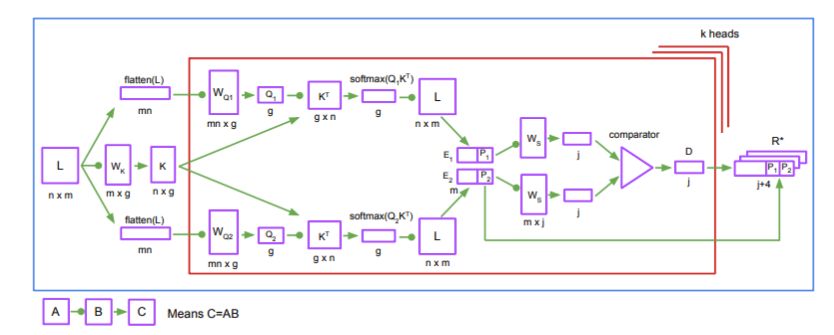
图 1:PrediNet 架构。注意力头共享权重 W_K 和 W_S,而 W_Q1 和 W_Q2 对每个注意力头是局部的。
实验
实验设置
该研究的实验目标包括:1)验证 PrediNet 架构可以学习通用、可重用表征的假设;2)如果假设成立,探索假设成立的原因。为了达成这些目标,研究者设计了一系列可配置的简单分类任务,统称为 Relations Game。

图 2:Relations Game 对象集和任务。(a)来自训练集和留出测试集的示例对象。(b)共有五种可能的行/列模式。在多任务设置中,识别每一种列模式是一个单独的任务。(c)用于单任务设置的三个示例任务。(d)用于多任务设置的示例目标任务(左)和课程(curriculum,右)。
为了评估 PrediNet 生成表征的通用性和可重用性,研究者将实验分为四个阶段,其中,1)该网络在一个或多个任务的课程上进行预训练;2)输入 CNN 和 PrediNet 中的权重都是固定的,但输出 MLP 中的权重根据随机值进行重新初始化;3)该网络在一个新的目标任务或一组任务中进行重新训练(如图 3 所示)。
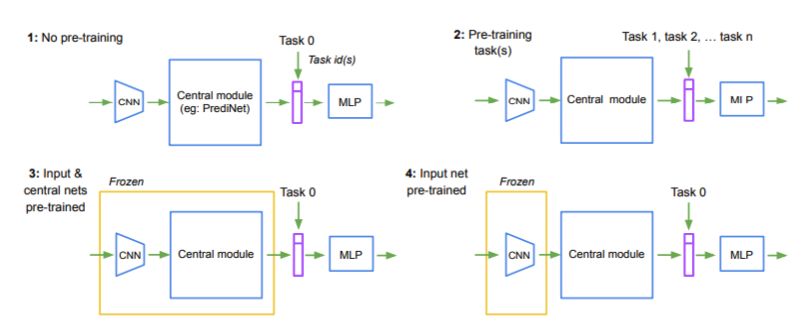
图 3:用于多任务课程训练的四个实验步骤。
实验结果
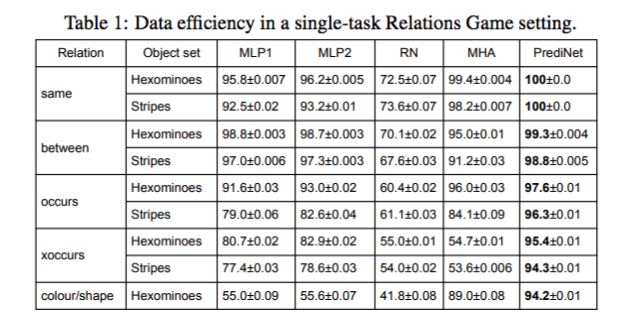
在研究通用性和可重用性之前,研究者先探索了 PrediNet 架构在单任务 Relation Game 设置中的数据有效性。结果取自 5 项任务:「same」、「between」、「occurs」、「xoccurs」和「colour / shape」,如表 1 所示。
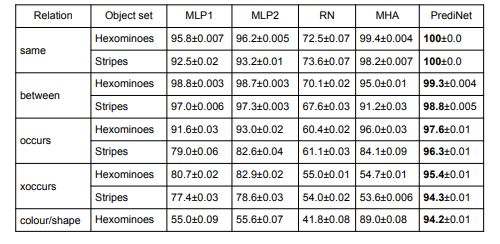
表 1:在单任务 Relation Game 设置中的数据有效性。
接下来,遵循图 3 所示的实验步骤,研究人员将 PrediNet 学习可重用表征的能力与每个基线进行了对比。他们研究了一系列目标任务和预训练课程任务的组合。图 4 展示了在这些组合中的发现。
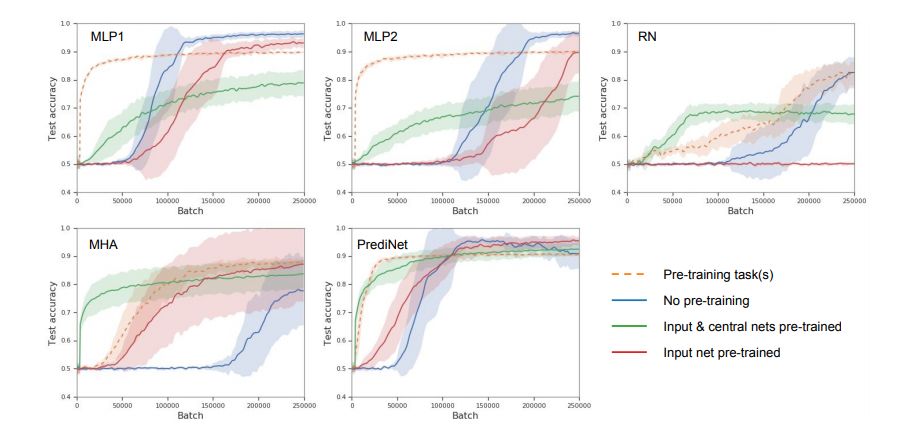
图 4:多任务课程训练。目标任务是一个三列模式(AAB、ABA 和 ABB),唯一的课程任务是「between」。
图 5 展示了更大范围的目标任务/课程任务组合,主要关注步骤 3 中的学习曲线。
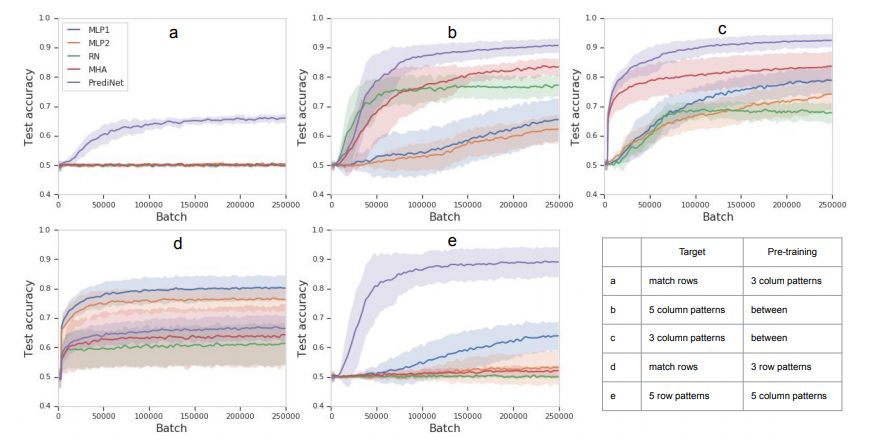
图 5:通过一系列目标和预训练任务学得表征的可重用性。
为了更好地理解 PrediNet 的操作,研究者还给出了一些可视化图(图 6a)。为了研究 PrediNet 如何编码关系,研究者再次在单任务设置中,对多个已训练网络中心模块输出向量的每个头进行主成分分析(PCA)(图 6b)。
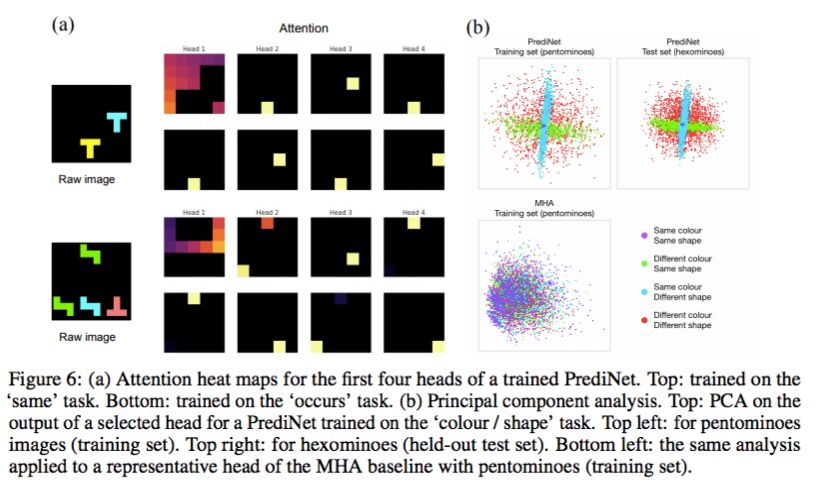
图 6:(a)PrediNet 前四个头的注意力热图。(b)主成分分析(PCA)。

论文链接:https://arxiv.org/pdf/1905.10307.pdf
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


