【ACL2020】多模态信息抽取,365页ppt全面阐述各种形式文本信息抽取

多模态信息抽取,Multi-modal Information Extraction from Text, Semi-structured, and Tabular Data on the Web
Organizers: Xin Luna Dong, Hannaneh Hajishirzi, Colin Lockard and Prashant Shiralkar

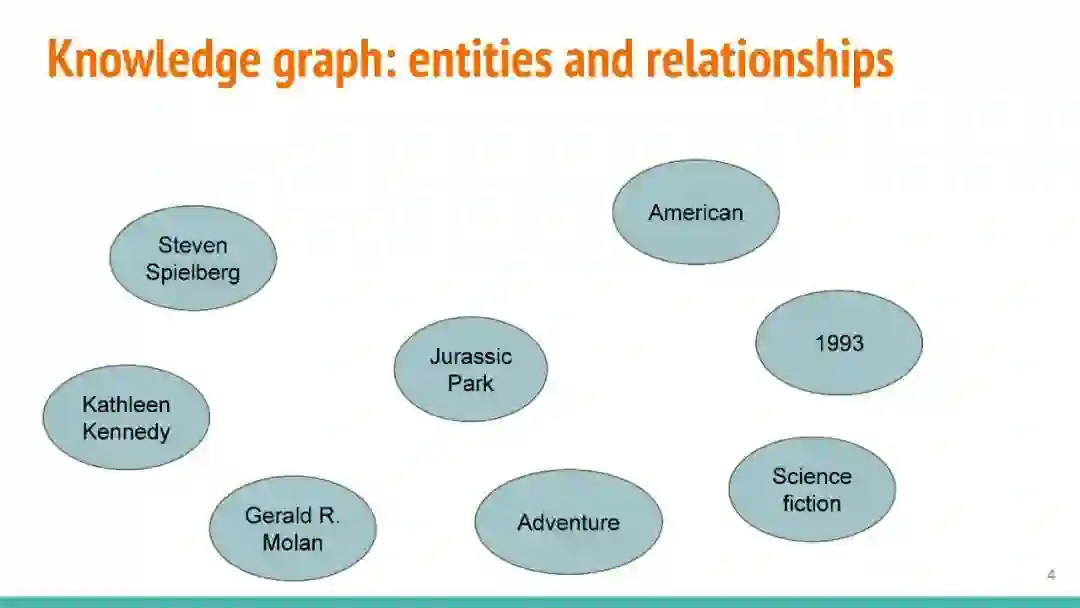
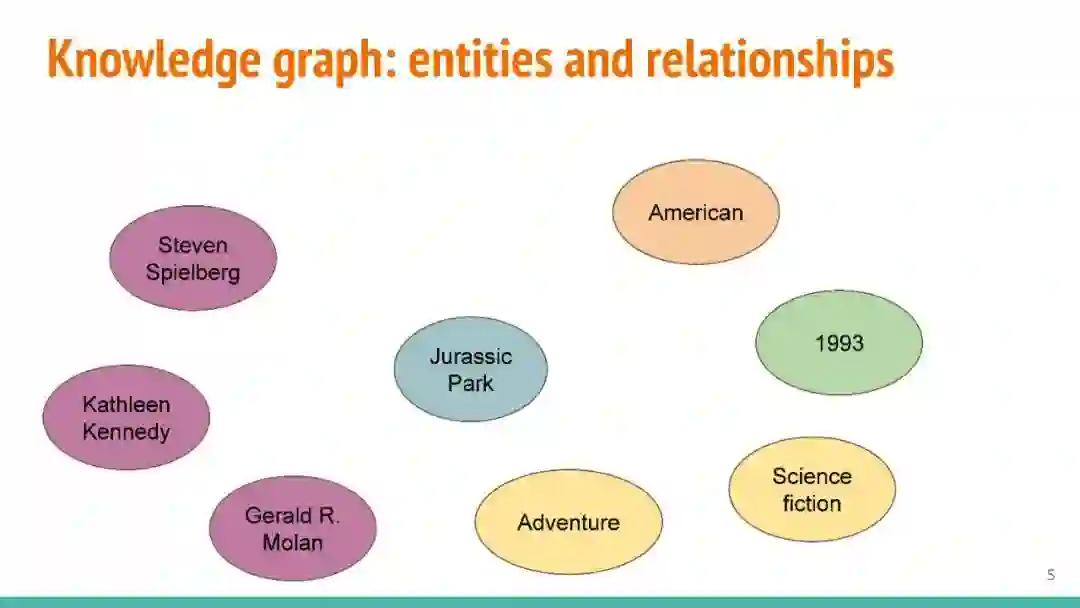
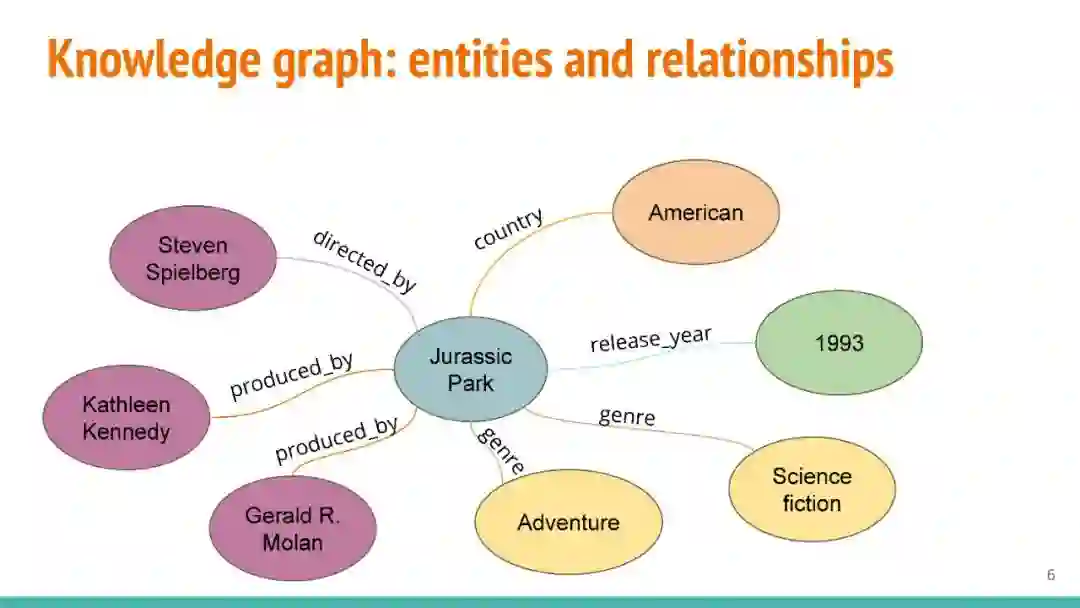
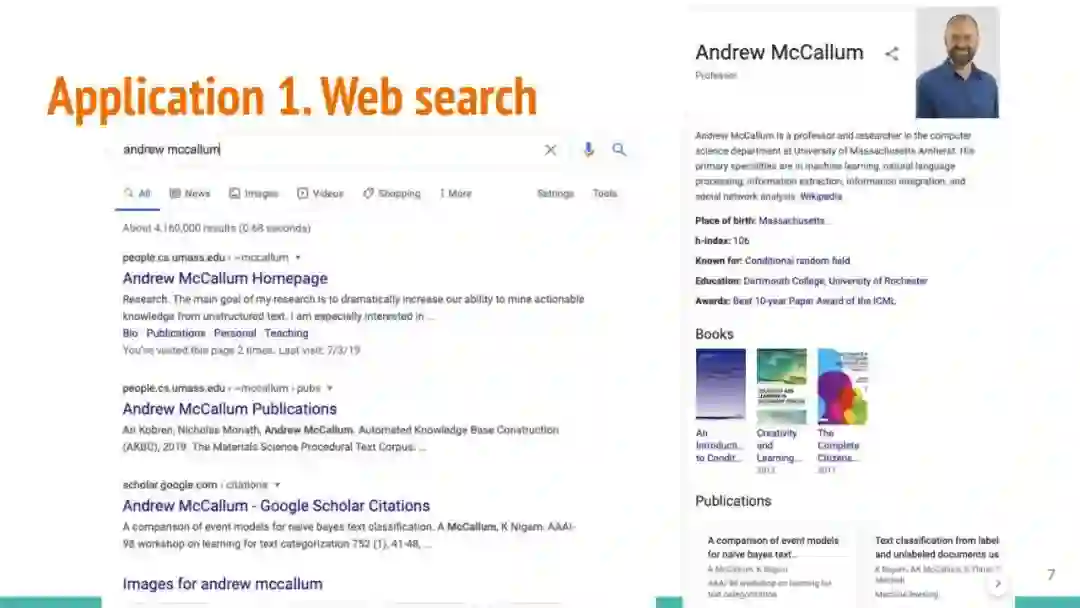
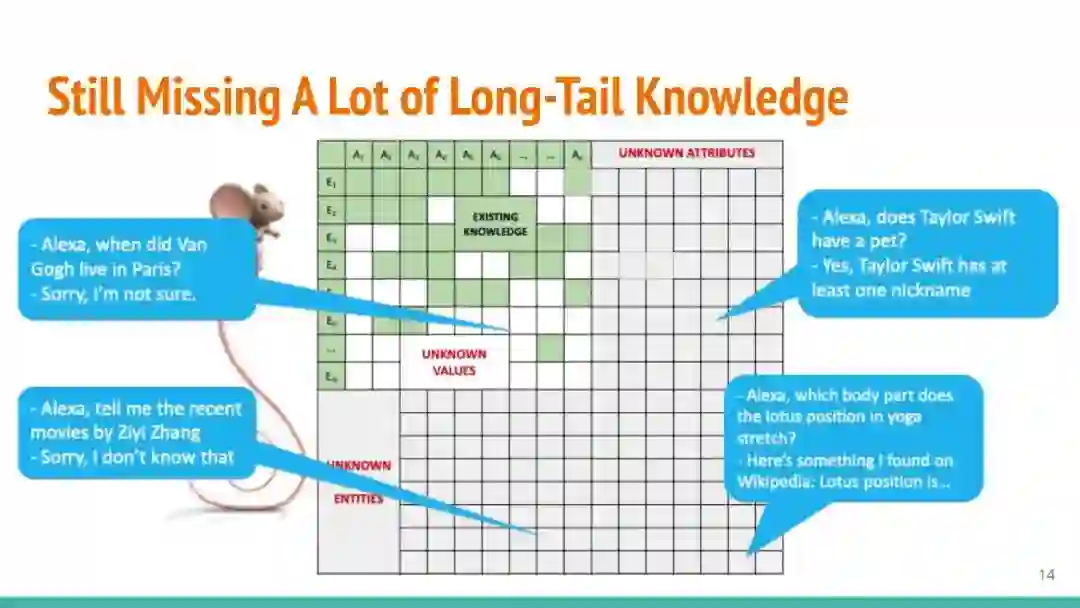
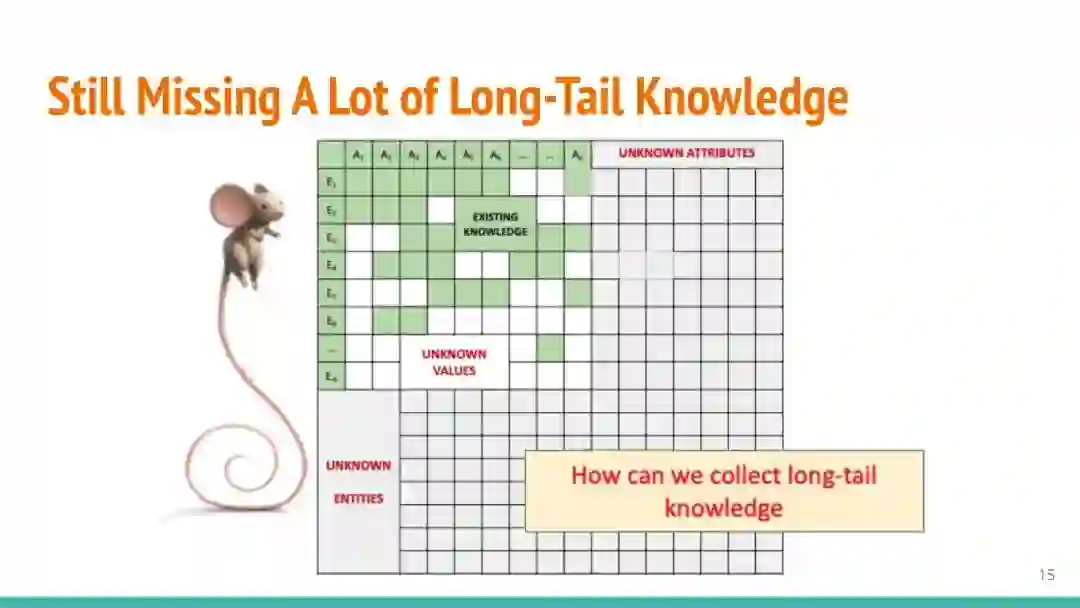
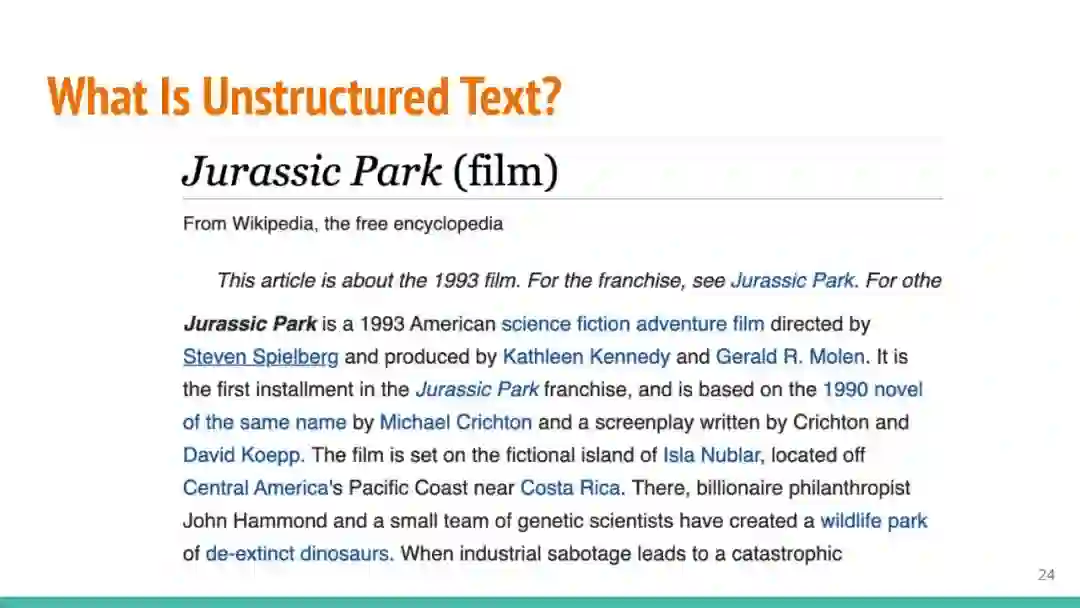
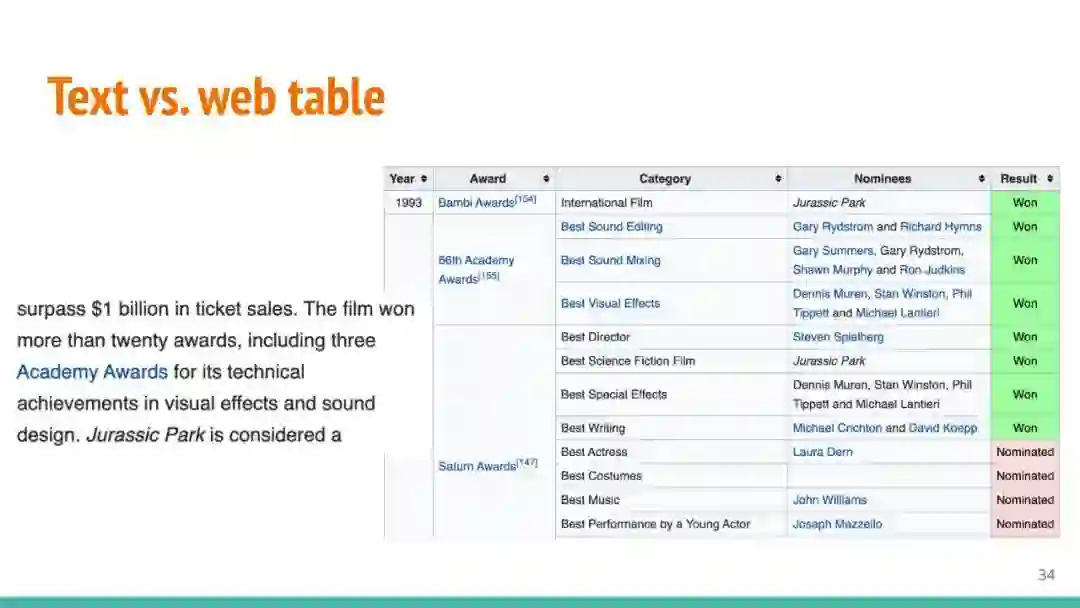
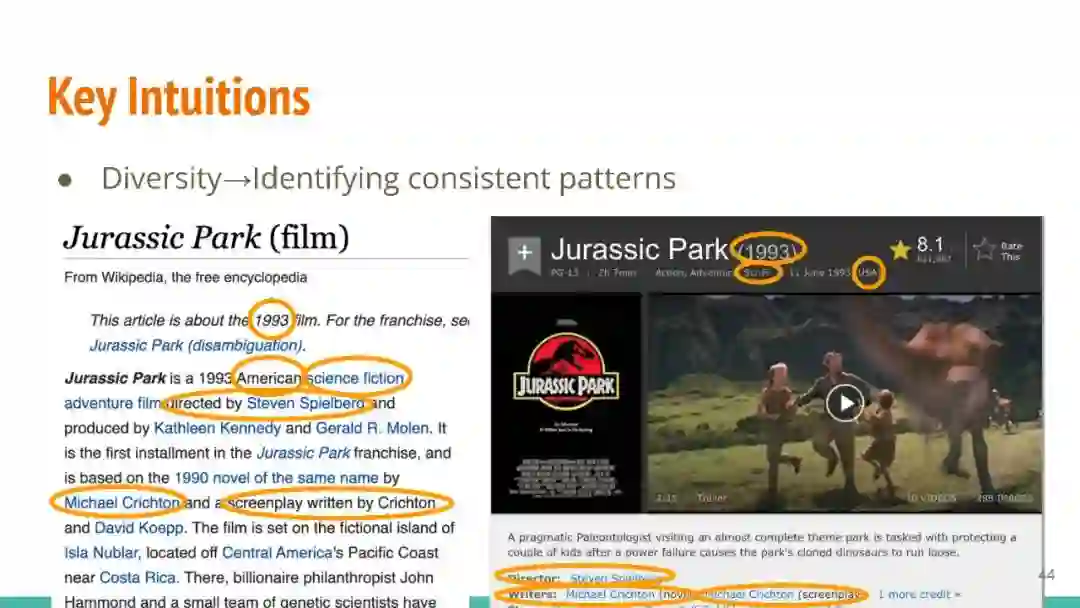
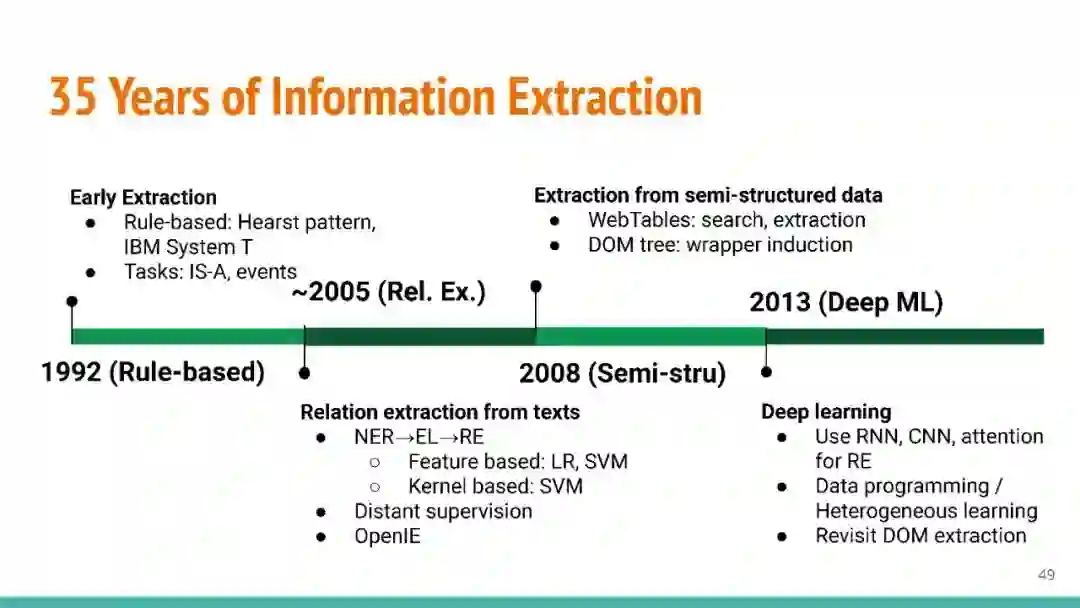
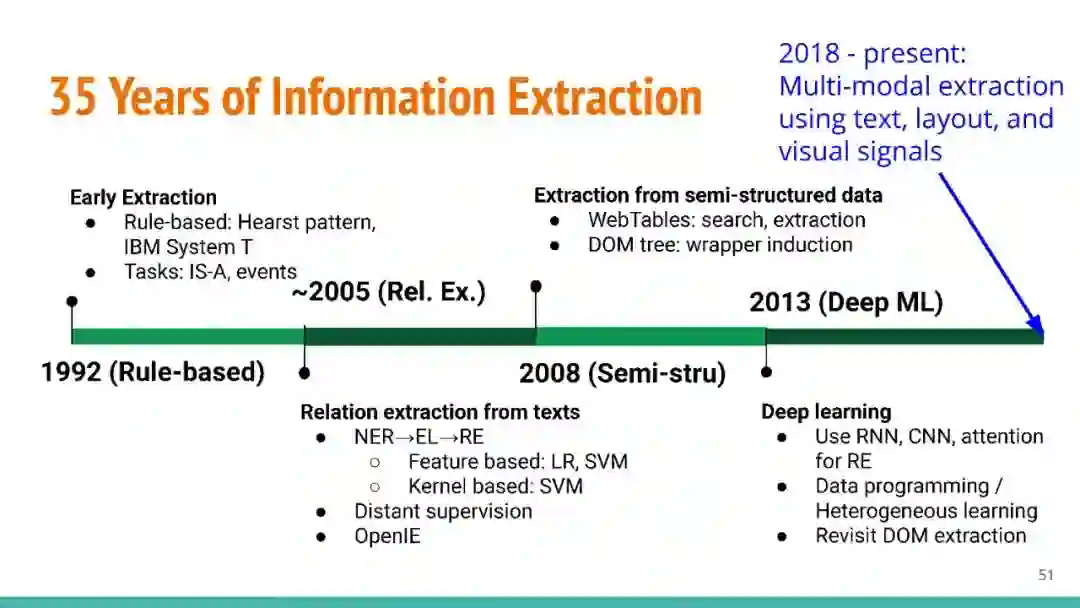
万维网以多种形式包含大量的文本信息:非结构化文本、基于模板的半结构化网页(以键-值对和列表的形式呈现数据)和表格。从这些资源中提取信息并将其转换为结构化形式的方法一直是自然语言处理(NLP)、数据挖掘和数据库社区研究的目标。虽然这些研究人员已经很大程度上根据数据的模态将web数据的提取分离到不同的问题中,但他们也面临着类似的问题,比如使用有限的标记数据进行学习,定义(或避免定义)本体,利用先验知识,以及针对web规模的可扩展解决方案。在本教程中,我们将从整体的角度来看待信息抽取,探索挑战中的共性,以及为解决这些不同形式的文本而开发的解决方案。
地址:
https://sites.google.com/view/acl-2020-multi-modal-ie






































专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MMIE” 可以获取《ACL2020-多模态信息抽取,365页ppt全面阐述各种形式文本信息抽取》专知下载链接索引



登录查看更多
相关内容
Arxiv
3+阅读 · 2018年4月18日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年4月18日