

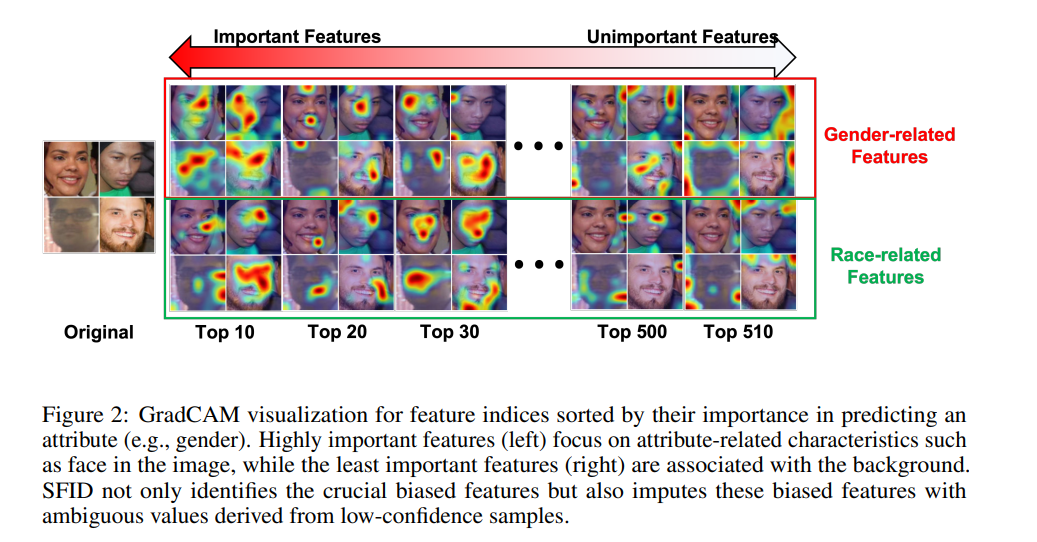
近年来,视觉-语言模型(Vision-Language Models, VLMs)的进展使得文本与图像数据的同时处理成为可能,极大地推动了人工智能领域的发展。然而,这些模型往往会表现出某些偏见,导致输出结果倾向于社会刻板印象,因此去偏策略是必不可少的。现有的去偏方法通常仅聚焦于特定的模态或任务,并且需要大量的重新训练。为了解决这些局限性,本文提出了一种新的方法,称为选择性特征插补去偏方法(Selective Feature Imputation for Debiasing, SFID)。该方法整合了特征剪枝和低置信度插补(Low Confidence Imputation, LCI),可以有效减少VLMs中的偏见。SFID方法灵活且具成本效益,因为它不需要重新训练,同时能够保持输出的语义完整性。实验结果表明,SFID在各种VLM任务(包括零样本分类、文本-图像检索、图像描述生成和文本-图像生成)中显著减少了性别偏见,并且不影响模型性能。该方法不仅提高了VLMs在应用中的公平性,还保留了其在各种场景中的效率和实用性。代码已在GitHub上发布。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日