零样本图像识别综述论文

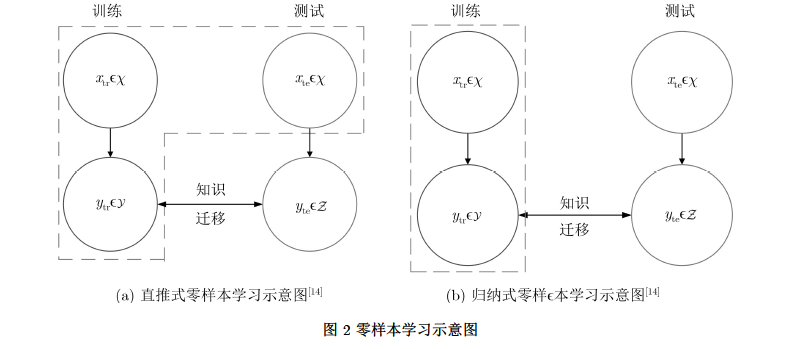
深度学习在人工智能领域已经取得了非常优秀的成就,在有监督识别任务中,使用深度学习算法训练海量的带标签数据,可以达到前所未有的识别精确度。但是,由于对海量数据的标注工作成本昂贵,对罕见类别获取海量数据难度较大,所以如何识别在训练过程中少见或从未见过的未知类仍然是一个严峻的问题。针对这个问题,该文回顾近年来的零样本图像识别技术研究,从研究背景、模型分析、数据集介绍、实验分析等方面全面阐释零样本图像识别技术。此外,该文还分析了当前研究存在的技术难题,并针对主流问题提出一些解决方案以及对未来研究的展望,为零样本学习的初学者或研究者提供一些参考。
http://jeit.ie.ac.cn/article/doi/10.11999/JEIT190485
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ZSIR” 就可以获取《零样本图像识别综述论文》论文专知下载链接



登录查看更多
相关内容
Arxiv
10+阅读 · 2019年10月3日
Arxiv
46+阅读 · 2019年9月22日
Arxiv
7+阅读 · 2019年8月28日
Arxiv
8+阅读 · 2018年5月12日




相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2019年10月3日
Arxiv
46+阅读 · 2019年9月22日
Arxiv
7+阅读 · 2019年8月28日
Arxiv
8+阅读 · 2018年5月12日