摘要
OpenAI的O1及其后续竞争者(如DeepSeek R1)的发布显著推动了大语言模型(Large Language Models,LLMs)在复杂推理方面的研究,引发学术界与工业界的双重关注。此项进展激发了相关技术成果的复现和在此基础上的创新。为系统构建该领域的研究框架,本文从自我进化(self-evolution)的角度系统地分类了现有技术。我们的调查发现分为三个相互关联的部分:数据进化(data evolution)、模型进化(model evolution)和自我进化(self-evolution)。
数据进化部分改进推理训练数据,这包括任务进化和增强思维链(Chain-of-Thought,CoT)推理的推理时间计算。
模型进化部分通过在训练过程中优化模型模块,以增强复杂推理能力。
自我进化部分则探讨其进化策略和模式。包括自我进化的规模法则(scaling law)与对 O1 类研究工作的分析。
通过系统梳理相关研究,我们总结了前沿方法,并提供了对未来研究方向的前瞻性展望。本文旨在激励LLM复杂推理社区进一步研究,并促进对LLM推理能力提升的深入探索。
关键词:大语言模型、复杂推理、自我进化、数据进化、模型进化、专家迭代、推理计算、强化学习
Tao He, Hao Li, Jingchang Chen等丨作者
Azure丨译者
论文题目:A Survey on Complex Reasoning of Large Language Models through the Lens of Self-Evolution
作者 | Tao He, Hao Li, Jingchang Chen, Runxuan Liu, Yixin Cao, Lizi Liao, Zihao Zheng, Zheng Chu, Jiafeng Liang, Ming Liu, Bing Qin
目录
-
引言
-
预备知识
-
数据演化
-
模型演化
-
自我进化
-
在自我进化框架内重新解读代表性O1类研究
-
未来挑战和方向
-
结论
摘要
OpenAI的O1及其后续竞争者(如DeepSeek R1)的发布显著推动了大语言模型(Large Language Models,LLMs)在复杂推理方面的研究,引发学术界与工业界的双重关注。此项进展激发了相关技术成果的复现和在此基础上的创新。为系统构建该领域的研究框架,本文从自我进化(self-evolution)的角度系统地分类了现有技术。我们的调查发现分为三个相互关联的部分:数据进化(data evolution)、模型进化(model evolution)和自我进化(self-evolution)。
数据进化部分改进推理训练数据,这包括任务进化和增强思维链(Chain-of-Thought,CoT)推理的推理时间计算。
模型进化部分通过在训练过程中优化模型模块,以增强复杂推理能力。
自我进化部分则探讨其进化策略和模式。包括自我进化的规模法则(scaling law)与对 O1 类研究工作的分析。
通过系统梳理相关研究,我们总结了前沿方法,并提供了对未来研究方向的前瞻性展望。本文旨在激励LLM复杂推理社区进一步研究,并促进对LLM推理能力提升的深入探索。
- 引言
近年来,大语言模型(LLMs)的发展令人瞩目。它们不仅在阅读理解、故事生成和对话能力等领域超出了预期,还在需要复杂逻辑推理的任务中表现出色,包括代码生成和数学问题解决。2024年下半年,LLM研究迎来了一个关键时刻,OpenAI发布了O1 [OpenAI, 2024a],这标志着复杂推理研究的一个重要里程碑。O1系列模型能够生成衍生的推理过程,灵活地分解问题,并在面临挑战时自主澄清、反思和纠正潜在错误,以及探索替代解决方案——模拟了人类思维特有的细致、反思性推理过程 [OpenAI, 2024b]。
工业界和学术界都致力于复现O1,掀起了一股技术报告的热潮。
在工业界,一系列类似的产品涌现,例如DeepSeek R1 [DeepSeek-AI et al.,2025](简称R1)、Kimi k1.5 [Team et al., 2025]和QwQ [Team, 2024b],它们都发布了自己的模型或技术报告。这些产品不仅达到甚至超越了O1,而且其开源贡献也值得称赞。此外,这些技术报告中强调的扩展强化学习(Scaling Reinforcement Learning)等技术,进一步拓展了研究类O1工作的方向。
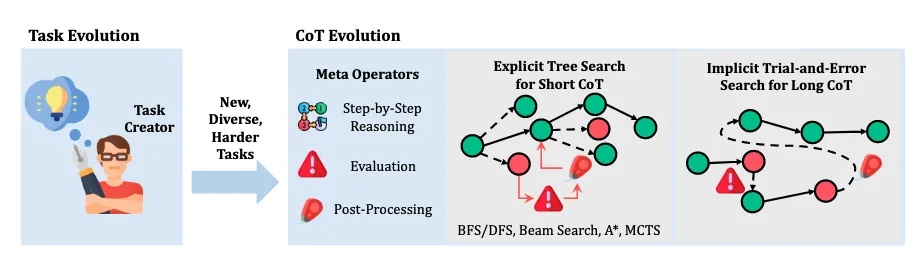
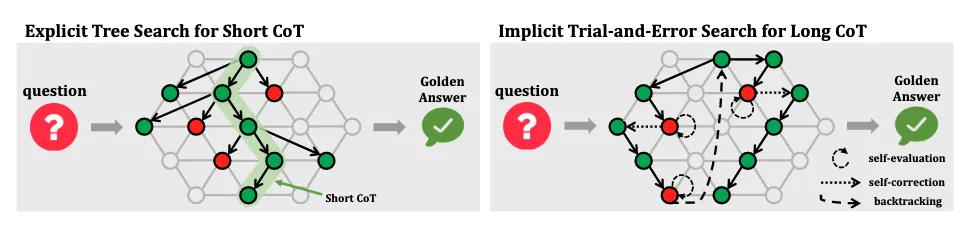
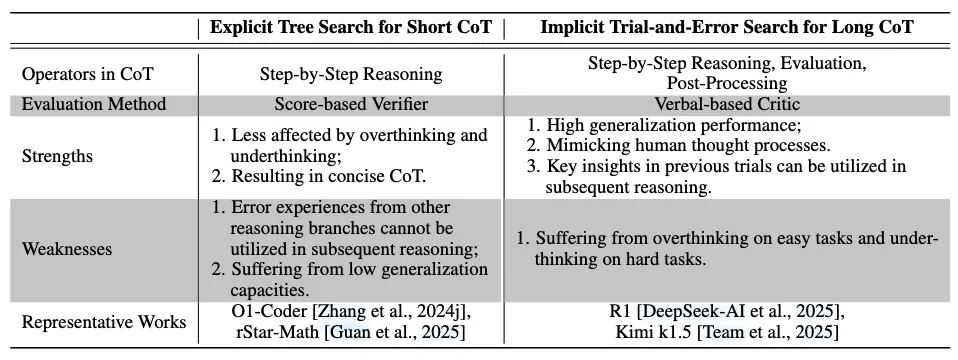
在学术界,研究者从不同角度进行了多项复现研究。例如,O1 Journey [Qin等,2024; Huang等,2024] 广泛讨论了思维链格式化和蒸馏,但对持续优化方法的见解有限。与此同时,OpenR [Wang等,2024e]、O1-Coder [Zhang等,2024j]等工作主要通过强化学习的视角研究O1,但忽略了对反思和纠正推理操作的讨论。另一方面,Slow Thinking系列工作[Jiang等,2024a; Min等,2024]专注于推理时计算,尝试通过树搜索技术提升推理性能。此外,rStar-Math [Guan等,2025] 通过使用自我进化框架联合训练推理器和过程奖励模型(Process Reward Model, PRM),实现了接近O1的性能,突显了迭代优化在提升推理能力方面的潜力。
尽管这些技术报告提供了宝贵的见解,但它们往往仅聚焦于特定技术领域,缺乏整体性的技术架构和统一的分类标准。因此,我们需要对这些方法进行系统性的高层次综述。O1博客 [OpenAI, 2024a] 和系统卡片 [OpenAI, 2024b] 提示O1采用了强化学习(RL)和推理时计算。这使我们联想到另一个杰出的人工智能——AlphaGo Zero [Silver等,2017]。AlphaGo Zero通过自我对弈、蒙特卡洛树搜索(MCTS)和策略模型的迭代学习实现了自我进化 [Silver et al., 2017] 。这一过程在无人干预的情况下提升了其性能,启发我们采用类似技术或许能将复杂推理能力提升至超越人类的水平。在这个类比中,训练策略模型对应于推理优化,而MCTS搜索则对应于推理时计算。自我进化通过循环这两个阶段,实现推理能力的自主提升。此外,高质量数据的匮乏凸显了自动化数据合成框架的迫切需求 [Sutskever, 2024; Wang et al., 2024f],由于推理任务对逻辑严谨性要求更高,这一挑战尤为突出。因为推理任务对逻辑严谨性有更高要求。在无人干预的情况下,自我进化不仅能利用合成数据来增强系统能力,还可以利用改进的系统合成更高质量的数据,创造一个良性循环推进过程。
鉴于这些考虑,本文希望从自我进化的视角对大语言模型的复杂推理提供全面综述。大语言模型复杂推理的自我进化,亦称自我改进(self-improvement),其需要在闭环推理系统中自主合成训练数据并持续提升推理能力 [Tao等,2024; Hu等,2024]。专家迭代(Expert iteration)[Polu等,2022; Zhao等,2024b] 被视为典型的自我进化范式。其核心思想是:模型首先生成推理轨迹,再基于标准答案筛选出正确解决方案,最后利用这些解决方案对模型进行微调,以提升其推理能力。这一过程进行迭代,直至模型收敛。此外,在线强化学习框架同样体现了自我进化的理念。智能体首先进行探索并生成轨迹,然后利用这些轨迹进行自我优化,从而在后续的学习周期中发现更高质量的轨迹。
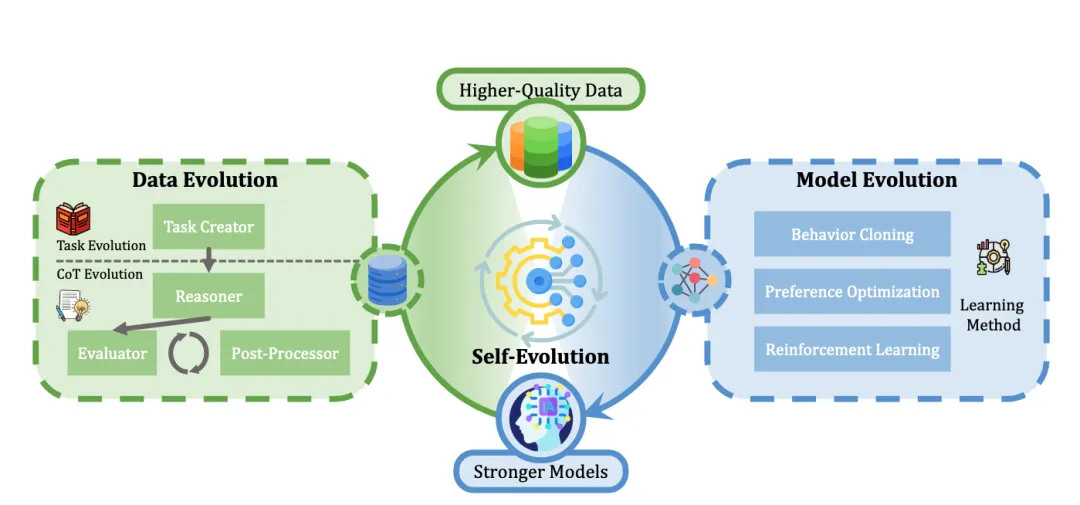
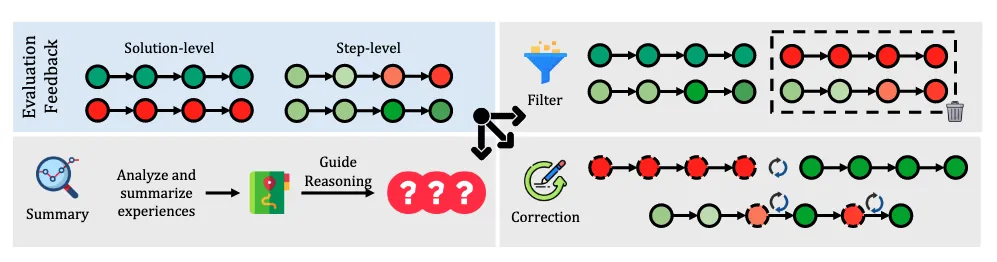
如图 1 所示,本综述的结构由三个部分组成:数据进化、模型进化和自我进化。数据进化探索合成高质量数据,包含两个阶段:(1)任务进化生成推理系统尚未能有效处理的任务,(2)思维链(CoT)进化通过扩展推理时计算 [Snell等,2024] 扩展大语言模型的性能边界,并通过思维链(Chain-of-Thought, CoT)[Wei等,2022] 推理生成更好的解决方案。然而,性能的提升可能源于启发式搜索算法而非模型的固有能力,这从模型无法持续生成高质量思维链的证据可见一斑。模型进化通过提升系统模块来解决这些问题。一方面,模型专门针对它们曾经困难的任务进行训练;另一方面,它们从收集的数据中有选择地学习,以真正扩展其能力边界。前两种进化代表了探索性和发散性努力,旨在研究实现数据和模型进化的有前景技术和挑战。这为自我进化奠定了数据合成策略和优化方法的技术基础。在第三部分,我们专注于推理系统的自我进化框架。通过迭代进行数据进化和模型进化,推理系统实现自我进化:数据进化基于当前模型生成更有针对性、更高质量的数据,而模型进化则利用收集的数据进一步强化模型,为下一轮数据进化提供更坚实的基础。
我们的贡献可总结如下:(1)全面综述:这是首个聚焦于推理自我进化的大语言模型综述;(2)分类体系:我们在图2中构建了一个详细的分类体系;(3)理论基础:我们整理了相关的基础理论,并探讨了自我进化的规模法则;(4)前沿与未来:我们分析了自我进化框架内的最新开源研究,并为未来研究指明方向。
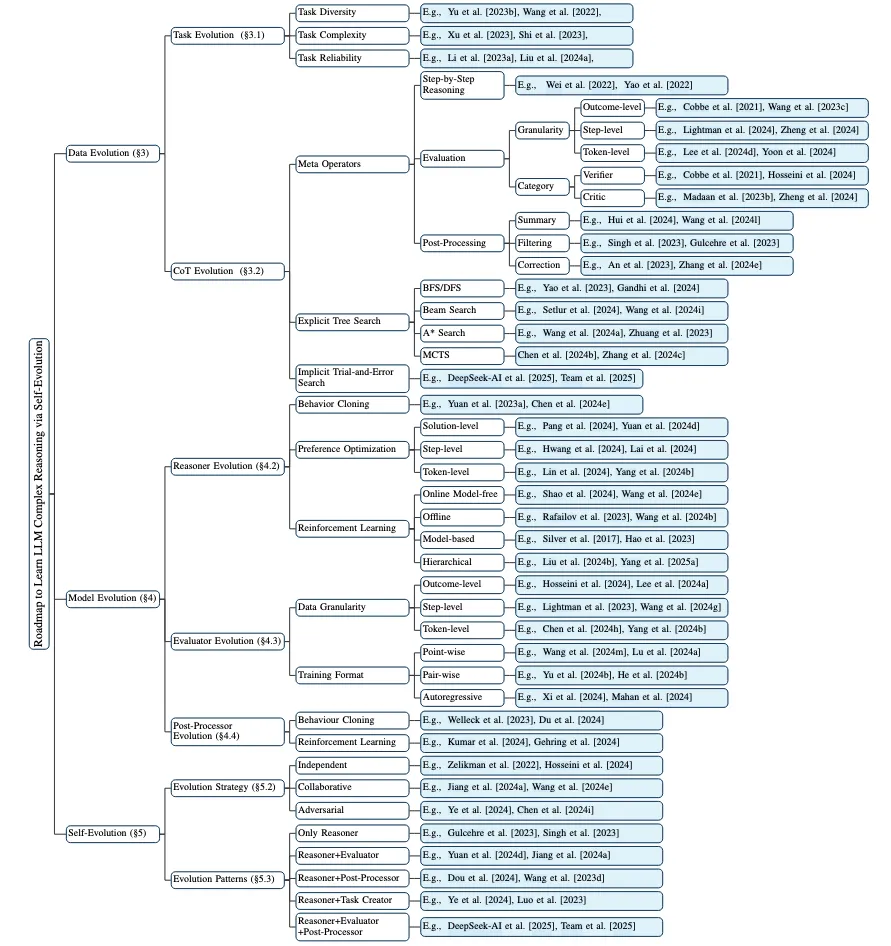
图2:先进方法的分类,包括数据进化、模型进化和自我进化。