

尽管大型语言模型(LLMs)的表现令人印象深刻,但由于在推理过程中需要大量的计算和内存资源,它们的广泛应用面临挑战。最近在模型压缩和系统级优化方法方面的进展旨在增强LLM的推理能力。本综述提供了这些方法的概览,强调了近期的发展。通过对LLaMA(/2)-7B的实验,我们评估了各种压缩技术,为高效部署LLM提供了实用的见解。在LLaMA(/2)-7B上的实证分析突出了这些方法的有效性。借鉴综述洞察,我们识别了当前的局限性,并讨论了提高LLM推理效率的潜在未来方向。我们在https://github.com/nyunAI/Faster-LLM-Survey上发布了代码库,以复现本文中呈现的结果。
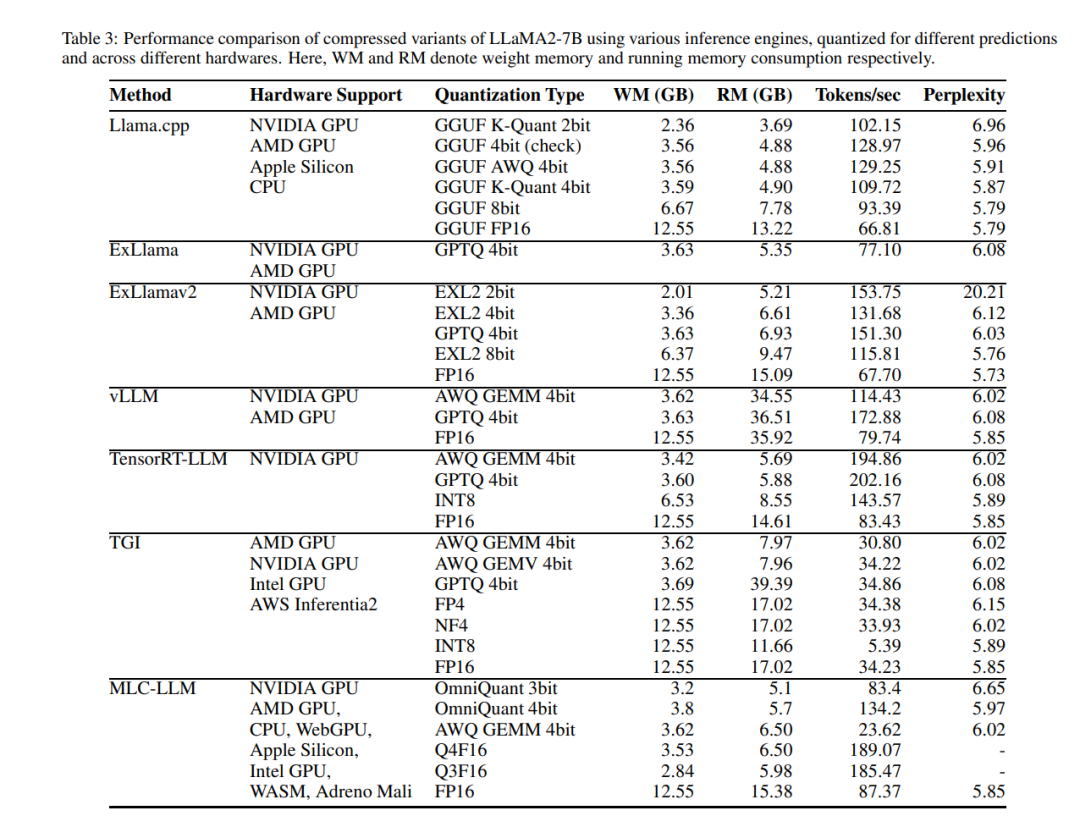
大型语言模型(LLMs)的出现,特别是通过如GPT [Brown et al., 2020]和LLaMa [Touvron et al., 2023a; Touvron et al., 2023b]系列等模型的显著标志,为与语言相关的任务开启了新的革命,这些任务范围从文本理解和总结到语言翻译和生成。这些通常由数十亿参数组成的模型,在捕捉复杂模式、细节丰富的上下文和自然语言的语义表达方面展现出了卓越的性能。因此,它们已成为各种应用中不可或缺的工具,推动了人工智能、信息检索和人机交互等多个领域的发展。 尽管LLMs的性能无与伦比,但它们广泛应用受到了巨大的计算和内存需求的阻碍,这在资源受限的环境中部署它们时构成了挑战。例如,加载一个LLaMa-70B模型需要140GB的VRAM,这还不包括模型推理所需的内存。对高效部署的需求促使近期研究开始关注模型压缩以及特别为LLMs量身定制的系统级修改技术。这些早期工作已经识别出改进LLMs推理效率的潜在方法。然而,当前的改进往往伴随着模型性能的显著下降,需要确定新的研究方向来找到解决这一问题的理想解决方案。 最近的一项综述研究提供了最新提出的LLM压缩方法的简明概览,以及用于基准测试它们的评估指标和数据[Zhu et al., 2023]。然而,为了进一步推动研究前沿,朝着LLMs的实际推理改进方向努力,还缺少一项全面的研究。在本综述论文中,我们探索旨在通过模型压缩以及系统级优化使LLMs高效的现有方法。为了公平比较各种方法,我们提供了使用不同压缩技术对LLaMa(/2)-7B应用的经验观察。我们的评估包括了提供实际优势的方法,包括现有文献中不同推理引擎提供的结构化剪枝、量化和系统级优化。我们分享从这些实验中获得的宝贵见解,以呈现高效LLMs的有用和实际理解。此外,我们还将与实验相关的代码和基准测试公开。我们还检查了当前压缩方法在通用深度学习以及特别为LLMs提出的方法中的困难,并讨论了克服这些问题的潜在研究方向。 总的来说,本文的贡献如下。
我们提供了模型压缩领域的简要概述,强调了对轻量化和加速LLMs领域作出显著贡献的基本方法。
作为模型压缩的补充,系统级修改在加速LLM推理中发挥了重要作用,我们也讨论了这些方法。
为了提供一个实践视角,我们对在标准化设置下的LLMs的知名压缩方法进行了实证分析。从中得到的洞察可以帮助根据部署环境做出有关选择LLM压缩方法的明智决定。
基于我们的综述和实证分析得出的见解,我们系统地指出了现有的局限性,并提出了实现LLM推理最佳效率的可行途径