

摘 要
本文回顾跨媒体智能的发展历程,分析跨媒体智能的新趋势与现实瓶颈,展望跨媒体智能的未来前景。跨媒体智 能旨在融合多来源、多模态数据,并试图利用不同媒体数据间的关系进行高层次语义理解与逻辑推理。现有跨媒体算法主要 遵循了“单媒体表达”到“多媒体融合”的范式,其中特征学习与逻辑推理两个过程相对割裂,无法综合多源多层次的语义 信息以获得统一特征,阻碍了推理和学习过程的相互促进和修正。这类范式缺乏显式知识积累与多级结构理解的过程,同时 限制了模型可信度与鲁棒性。在这样的背景下,本文转向一种新的智能表达方式——视觉知识。以视觉知识驱动的跨媒体智 能,具有多层次建模和知识推理的特点、并易于进行视觉操作与重建。本文介绍了视觉知识的三个基本要素,即视觉概念、 视觉关系、视觉推理,并对每个要素展开详细讨论与分析。视觉知识有助于实现数据与知识驱动的统一框架,学习可归因可 溯源的结构化表达,推动跨媒体知识关联与智能推理。视觉知识具有强大的知识抽象表达能力和多重知识互补能力,为跨媒 体智能进化提供了新的有力支点。
引 言
跨媒体智能是人工智能的一个重要研究领域。人类善于综合视觉、听觉、语言文字等多种信号进 行认知和推理。当人类融合多种感知途径形成对某 个事物的综合理解后,这些多方面感知信号之间能 够互相触发、彼此增强。在人工智能的研究中,通过 多种媒体方式进行信息感知、融合、表达、推理是跨 媒体智能的典型特征。跨媒体智能不仅单独处理不 同来源、不同模态的数据,还对它们进行多来源、多 模态融合与增强;不仅要求完成简单的识别、检测、 定位,还能够进行更复杂的理解与推理等高阶智力 活动。跨媒体智能展现出与人类认知和思考的高度 相似性,正逐渐成为新一代人工智能研究中备受关 注的一个重要方向。
本文首先调研跨媒体表达的研究现状,并分析 现有相关研究的局限性。作为跨媒体智能的重要研 究方向之一,跨媒体表达经历了手工设计和深度学 习两个阶段。这一发展轨迹与人工智能其他领域相 似。无论是手工设计还是深度学习方法,绝大部分 跨媒体表达研究以单一媒体数据下的知识表达为基 础、分别获取多个模态的特征,然后将这些多模特 征并行映射到模态共享的特征空间,进行特征关联 与融合。这种自底而上融合的特征表达方式给跨媒 体知识表达带来了很大的局限性,缺乏系统性的可 解释与高阶推理能力。
本文随后分析一种跨媒体智能研究的新途径— —视觉知识(Pan,2019)。视觉知识不仅关注图像 或视频等视觉信号,以及基于这些信号提取或学习 得到的特征,而且以视觉概念(通常由典型和范畴 构成)(Pan,2019)为研究要素,联合符号化知识 与逻辑推理、深度学习技术、知识图谱、手工构造的 知识(如结构化信息)等多种知识表达手段,将与视 觉主体相关的音频、语言等信号进行联合建模与推 理。这种性质与人类在理解和推理多媒体信号时的 处理流程是相似的——以信息量最高的视觉为主导、 并在其基础上关联语音、文字等感知与理解。这些 声音、文字等其他形式的信息又能适时地促进、增 强对环境和目标的视觉理解。这种多模态知识表达 互相增强的性质,也正是视觉知识所具有的多重知 识表达能力(Pan,2020;Yang 等,2021)。
考虑到现有跨媒体智能算法鲁棒性弱、泛化性 与可解释性不足等基础性问题,构建视觉知识驱动 的新型视觉表达理论,提升视觉知识挖掘与提取的 自动性和可解释性是势在必行的。我们相信,视觉 知识作为一项重要的新兴研究方向,对跨媒体智能 进一步发展至关重要。视觉知识和多重知识表达的 结合,有望成为跨媒体智能研究的新支点。
1 跨媒体表达现状与局限
常见的多媒体数据包括图像、视频、音频、自然 语言等。跨媒体特征表达的基础是对单一媒体数据 进行表达。对于单一媒体表达,手工设计特征和深 度学习特征都已有大量研究,并在各自发展阶段均 取得较大进展。尤其是深度学习技术的出现,促进 了跨媒体研究成果在很多领域得到广泛应用。尽管取得了长足的进步,现有跨媒体研究依然 有其局限性。其原因在于现有跨媒体表达主要遵循 了“单媒体表达”到“多媒体融合”的范式,其特征 学习与逻辑推理两个过程相对割裂,无法综合多源 多层次的语义信息以获得统一特征,阻碍了推理和 学习过程的相互促进和修正。这类范式缺乏显式知 识积累与多级结构理解的过程,同时限制了模型可 信度与鲁棒性。具体来讲,本文认为目前跨媒体表 达的局限性主要体现在以下三个方面。
1.1 模型可信与可解释能力弱
现有跨媒体表达通常先独立提取不同媒体各自 模态的特征,然后再进行跨媒体特征融合。这类方 式易于模型训练,但由于缺乏统一表达,造成模型 过拟合且难归因。
对于图像或视频数据,传统手工特征抽取技术 (如 Scale-Invariant Feature Transform, SIFT(Lowe, 2004)、Histogram of Oriented Gradients, HoG(Dalal 和 Triggs,2005)、Improved Dense Trajectories, IDT (Wang 和 Schmid,2013))利用关键点或边缘信息 获取局部特征描述符。这类特征描述符具有一定的 可解释性,但其不具备可学习能力且拟合能力弱。随着深度学习技术的突破,主流方法大多使用深度 学习技术提取单一模态特征。其中图像的特征抽取 通常使用卷积神经网络(Krizhevsky 等,2012)。
语言特征通常使用词向量(Mikolov 等,2013) 模型、长短时记忆模型(Hochreiter 和 Schmidhuber, 1997)、或者 Transformer 模型(Vaswani 等,2017)。获得单一媒体的特征后,跨媒体学习的典型思路是 将多种不同模态特征映射到跨媒体共享的特征空间。这一过程需要将多模态特征的学习融入到统一的学 习框架中,并在模型优化过程中,挖掘跨媒体数据 间的内在关联。例如,图像和自然语言之间的跨媒体表达通常把图像特征和语言特征映射到同一特征 空间,并使用特定的损失函数约束图像和语言在这 个特征空间的相似性(Frome 等,2013;Zheng 等, 2020)。
虽然深度神经网络具有强大的表征学习能力, 但在一些情况下特征过拟合现象严重。深度神经网 络模型较难可视化且参数庞大,其可解释性不足。另一方面,跨媒体深度学习方法涉及多个模态的建 模,往往需要利用神经网络提取每个模态的特征, 其整体模型参数量相比于单模态模型往往更多,训 练过程中更易出现过拟合现象(Wang 等,2020a), 从而导致其模型预测更难系统性解释。经过跨媒体 融合后的特征更为抽象,为数据归因、模型解释带 来了更多的困难。
1.2 层次建模与结构理解不足
以图像为例,常见的跨媒体表达技术为了获取 更加丰富的图像特征,会采用多尺度图像特征,或 者对图像语义的关系建模(Li 等,2019)。除了图 像和语言分别抽取特征外,一些方法(Wang 等,2019;Wu 等,2018)在抽取图像和语言特征过程中引入图 像和语言信息的互相流动机制,提升图像和语言的 跨媒体表达能力。这些研究在近年取得了较大进展,但忽略了识 别过程中显式建模层级化信息。现有跨媒体表达在 分别完成各个模态特征提取后,继而进行信息融合, 并不具备由浅及深、分层次融合多媒体知识的能力。相比之下,人类认知更倾向于一个抽象程度由浅及 深的过程,在信息处理时逐渐移除琐碎细节并保留 重要元素。例如,当人类识别一个特定动物种类时, 人类首先倾向于观察它的外貌、聆听它的声音,形 成直观的感知,从而获得诸如颜色、尺寸、纹理等较 为细节的感官信息。这些可感知的信息处于一个相 对较低的抽象层次。基于这些感官信息,人类可以 融入一些抽象层次更高的知识,例如生活习性、生 物分类学信息等。在这个例子中,视觉、听觉信息是 抽象层次较低的知识,而符号化的语言、文字蕴含 抽象层次较高的知识。人类这种基于多重知识表达 的认知过程,先依靠视觉、听觉获取低抽象的感官 信息,再依靠符号化表达的语言文字获取高抽象的 生活习性、分类学信息,对于人类充分利用多媒体 信息,从而形成对环境和事物全面认知至关重要。
1.3 推理认知与迁移效果欠佳
无论是手工设计还是深度学习方法,当前跨媒 体表达方法大都遵循“自底而上融合”的范式——先分别在各个不同的数据模态下、学习相应的单模 态特征,然后再将这些特征映射到同一个模态共享 的特征空间中进行跨媒体融合。一个代表性的思路 是通过探索数据之间的关联和子空间学习获取更加 准确的统一表达。比如 Hardoon 等人(2004)提出 的基于线性变换的典型相关性分析方法(Canonical Correlation Analysis,CCA)。该工作通过成对跨媒 体数据的相关性,学习映射矩阵,将处于异构空间 中的多媒体特征映射到同构空间中,从而获取可以 进行相似性对比的跨媒体表示。除了 CCA,还有一 些研究则采用图的形式进行跨媒体建模(Yang 等, 2011)。另有一些工作还将跨媒体图建模和子空间 方法相结合(如 Yang 等,2008)。尽管这些工作在 利用手工特征进行跨媒体表达上进行了积极尝试且 取得了很多进展,这一类方法在某些特定的领域(如 跨媒体推理)性能还相对较弱。
当前跨媒体表达技术在一个模态共享的特征空 间对所有模态进行了融合,提升了综合表达能力, 但鲜能利用一种模态信息对另一种模态信息进行特 征增强和推理。这种范式虽然在一些应用场景中能 够满足特定的跨媒体信息融合、交互需求,但与人 类处理跨媒体数据相比,其推理能力薄弱,对媒体 之间的信息增强和关联能力不强,且无法有效进行 跨场景迁移。相比之下,人类并不是简单地对多媒 体信息进行融合,而是在融合中利用不同模态信息 相互促进。例如,通过融合“汽车可以喷涂为各种颜 色”的高层语义信息和“一辆红色汽车”的图像信 息,一个从未见过其它汽车的儿童也能识别出黑色 汽车。在这个例子中,自然语言所表达的符号化知 识促进了视觉信息的泛化。相比之下,当前跨媒体 知识表达尚不能在不同媒体信息之间形成有效的相 互增强。
上述不足限制了当前跨媒体知识表达能力的进 一步提升,成为跨媒体智能的发展的主要障碍。我 们亟需更合理、更灵活、更复杂的跨模态知识表达, 来推动跨媒体智能的进步。
2 视觉知识理论
视觉知识 (Pan,2019)是一种有望提高跨媒体 知识表达能力、进一步推动人工智能发展(特别是 跨媒体智能)的新框架。本章接下来将讨论视觉知 识对跨媒体表达的支撑和促进作用。需要指出的是, 视觉知识理论不仅仅可以促进跨媒体表达的研究, 它也可以支撑和提升诸如智能创作、逻辑推理等更为广泛人工智能领域的研究和应用。图 1 展示了视觉知识的基本要素及其优势。
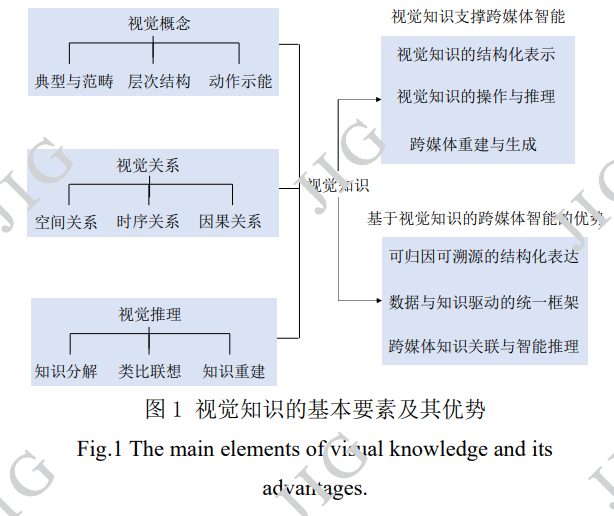
2.1 视觉知识的要素
本文接下来简要从三个方面介绍目前和视觉知 识基本要素相关的跨媒体智能研究,即视觉概念、 视觉关系、视觉推理。
2.1.1 视觉概念
视觉知识以视觉概念作为基本单元。视觉概念 应具备结构化、可解释的特性,从而保证知识建模 可外推,为跨媒体分析提供可归因的推断结果。 1)典型与范畴。视觉概念具有典型与范畴结构。 典型(prototype)是某类样本中最常见的一种模 式。典型作为视觉概念的核心表示,描述了事物的 典型特征。范畴为典型中各种参数的变化域,也可 作为典型和若干非典型形状、色彩所构成的综合场 (Pan,2019;Pan,1996)。针对视觉概念进行典型 与范畴的分解,有助于更准确的视觉概念分布估计, 并有效实现典型归纳与范畴迁移。例如,文献(Snell 等,2017)中可将类内样本的特征平均理解为类别 典型。在小样本条件下,该典型特征相比于样本特 征更为鲁棒。Wang 等人(2021)引入了一组动词典 型用于描述具身动作的主要运动模式,并利用该典 型辅助场景内物体特征的分解,最终选择出准确的 交互物体。Zheng 等人(2019)分离了行人图像中的 两种表征,即典型特征(外观特征)和结构特征(人 物体态),通过交换不同行人的特征,生成行人范畴 内的新图像,扩充训练样本。解耦外观特征和结构 特征,有助于提升合成行人图像的鲁棒性与可靠性, 实现高质量新图像合成。Zhu 和 Yang(2021)为少 样本学习设计了标签独立存储器,用于缓存特定类的知识,其中每个类特征的聚合可以理解为该类视 频的典型。这种典型特征对嘈杂的视频具有更强的 鲁棒性。范例(exemplar)学习也可以理解为视觉概 念典型/范畴建模的研究。例如 Yang 等人(2013) 自适应的选取范畴之外的训练数据来提升少样本条 件下的复杂事件检测性能。
2)层次结构。目前视觉概念的层次结构(Pan, 2019)相关的研究,包含多尺度样本理解、多层次类 别抽象、多模态主次分析等。 多尺度理解在视觉分析领域已广泛使用。例如, Lazebnik 等人(2006)引入金字塔结构用于多尺度 图像特征学习,该方法对物体形变具有较强鲁棒性。 在视频分析领域,长视频内容的层次化表达可有效 减少输入信息流的长度,从而有效挖掘更长范围内 的视频时序结构(Pan 等,2016)。Yang 等人(2012) 利用数据的层级流形结构提供更为鲁棒的多媒体语 义理解。Zhu 等人(2021)提出一种跨层的注意力机 制以实现相邻帧间多层级信息的探索,该跨层注意 力模块决定了不同卷积层的权重。获得多尺度权重 后,融合来自多尺度的上下文知识为动作识别提供 了高效的特征。Zhu 等人(2021)考虑了从多个视频 间获取共享的多尺度信息,这类多尺度信息具有全 局一致性,降低了单个样本可能带来的数据偏差, 从而获得更稳定且易识别的多尺度特征。 多层次类别抽象用于建立简单概念到复杂概念 的层级关系。复杂视觉概念的多层次结构表示有助 于概念分解与重组、快速概念拓展与新视觉概念理 解。复杂概念往往由简单概念经过非线性组合构成。 有效利用视觉概念间的层次先验、考虑多尺度多任 务关系,可有效降低模型训练难度,提升视觉概念 表达的丰富度。 多模态主次分析利用人类感知过程中以视觉信 息为主导的特点,采用视觉信号主导,并以其它信 息如声音、语言进行辅助。一般认为,人类接收的信 息大部分来自于视觉信号(图像或视频),其承载了 更丰富、更细致的感官信息。然而,传统方法建模各 个媒体信息时仅考虑其并列关系,并未考虑模态主 次信息。本文认为,人工智能尽管与人类智慧有很 大的差异,但在发展跨媒体智能时,以视觉信息主 导、其它信息辅助的特点,依然是值得借鉴的。
3)动作示能。视觉概念除了描述事物的形状、 色彩、语义等,还需表达人类与物体间的交互关系。 Gibson(1998)在《示能理论》中指出,示能是环境 或物体的可供性,即环境或物体可以提供的功能或用途。物体的示能表征了物体与人类间潜在的可交 互行为。例如,杯子具有“可握”的示能,椅子具有 “可坐”的示能。视觉概念包含动作示能的理解,其 主要涉及物体形状、语义与人类动作的关联。例如, Nagarajan 等人(2020)提出了描述了环境示能的拓 扑图结构,以有效预测未来可能发生的动作。在具 身视觉问题上,Fan 等人(2021)在人类操纵物体时 不仅考虑手和物体,同时引入人类意图作为参考, 对视觉动态和对象位置变化进行建模,从而有效识 别交互动作。Wang 等人(2020b)将动作与物体间 通过共生注意力机制,进行联合时空关系推理,实 现更准确的具身交互理解。
具备典型与范畴结构、层次结构、动作示能的 视觉概念,将大幅度提升模型鲁棒性,实现人机交 互、增强现实等场景下的高效应用。
2.1.2 视觉关系
在视觉概念的表达上,视觉关系表示了视觉概 念间的关联情况,为更为复杂的跨媒体视觉推理提 供有效基础。本文指出视觉关系包含空间关系、时 序关系与因果关系,但视觉关系并不仅限于这几类。 传统视觉关系旨在捕获图像中成对物体间的各种交 互。本文指出研究人员应着重将成对视觉关系拓宽 至多物体级联关系,并有效统一跨媒体时空与因果 表达。
1)空间关系。视觉内容中最常见的空间关系包 含显式的位置关系或隐式的动作关系。 常见的位置 关系包括“在...之上”、“在...旁边”等。隐式动 作关系描述了物体间或物体与人类间的动作相关的 位置信息,如“骑”描述了物体甲在物体乙之上,并 且表现出“骑”的动作(“骑在马上”或“骑在自行 车上”)。Krishna 等人(2017)引入了一个大规模 的空间关系数据集用于视觉关系建模。视觉关系的 识别往往需考虑配对物体间的相关性。例如,Chang 等人(2018)使用关系网络进行场景中人物关系建 模。Zheng 等人(2020)统一了地面视角,无人机 视角,卫星视角的视角表达。这些研究主要关注图 像中的静态关系。
**2)时序关系。**时序变化为视觉关系在时间维度 上带来了多样性。时空联合关系建模带来了诸多挑 战。其中涉及到单个物体在时序上的变化,以及物 体间空间关系在时序上的变化,这种动态变化的集 合构成了物体间复杂且细微的时序关系。动态时序 关系包含人类社交、物体运动等动态关系。例如,物 体逐渐靠近墙面,随后,物体碰撞墙面后,开始远离 墙面。这类关系的表达需有效理解运动信息并捕捉 运动情况的变化。Ji 等人(2020)引入了一个大规模 时空关系数据集用于时空语义关系建模。Fan 等人 (2020)基于动态点云、并对时间与空间进行解耦, 从而对三维空间中的运动进行建模与理解。
3)因果关系。因果关系是事件原因与结果的联 系。跨媒体数据往往存在视觉偏差。数据偏差指的 是在数据集中,某些成分比其它成分出现的比例、 权重更大。数据偏差不仅降低了训练模型的预测精 度,有时甚至会导致公平性方面的问题。例如,当人 脸识别训练数据中白种人比例偏多时,会导致模型 对有色人种的识别不够友好。这种数据偏差问题在 跨媒体智能中尤为严重,因为跨媒体数据的主要获 取渠道之一是互联网,而互联网上的数据是非规范 化的,存在严重的数据分布不均衡,甚至存在局部 数据重复与错误标注等问题。因果关系的建模有助 于消除嵌入在跨媒体数据中的偏差,并量化事物间 的因果影响。干预和反事实推理是提供无偏预测的 常用工具。
2.1.3 视觉推理
视觉知识建立在视觉概念与视觉关系的基础上, 可赋能更具解释性与泛化性的抽象跨媒体视觉推理。 视觉知识提供了结构化知识表达,为视觉推理提供 多方面的解释基础,对神经网络决策背后的推理逻 辑提供有效解释。本文所指的视觉推理广义上包含 各种视觉操作,如预测、重建、联系、分解等。
1)视觉知识分解。视觉概念包含层次与结构, 具有分解性与合成性。通过简单概念的组合,人类 可以构造复杂概念并创建多功能系统。另一方面, 人类可以快速将复杂事物进行分解,并将陌生的事 物分解为熟悉的组件。视觉知识分解旨在捕获视觉 内容中显著或具有解释性的因素,将抽象知识解藕 成独立、易解释的概念。研究视觉知识分解的机理 有助于深刻理解数据生成过程及其潜在的因果关系, 帮助提炼重要的视觉信息,并创建更泛化的知识表 达。基于自监督的视觉分解研究或是大规模自动提 取视觉知识的有效途径。
2)知识类比联想。人类具有识别概念之间关系, 并类比推断至超越已有概念的能力。知识类比是推 理的重要步骤。比如,玫瑰之于花,相当于猫之于什 么?人类可以推理出答案应是“动物”,并理解玫瑰 之于花为“从属”关系。类比联想涉及到对视觉知识 的操作,但并不仅限于本文 2.1.2 章节中提到的空 间、时序与因果关系。基于类比联想的推理方式通过实例组合的形式,将隐式关系包含在推理过程中。 类比联想的研究将视觉知识中的关系建模推广到逻 辑关系、从属关系等更为抽象的关系中。
3)视觉知识重建。视觉知识的重建是指根据视 觉知识表达重构出原始视觉内容。视觉重建的过程 是视觉知识表达的逆过程。视觉知识重建不仅需要 重建视觉概念的形状、结构等典型信息,且需根据 视觉概念的范畴进行可控的多样性内容生成。视觉 知识的重建不仅包含静态二维图像、三维几何生成, 也包含连续动作变化的模拟。视觉知识重建亦可用 于视觉知识表达质量的评估,并为可解释视觉概念 提供有效工具。

2.2 视觉知识应用于跨媒体智能的研究思路
视觉知识理论旨在建立统一的知识表达方式。 本文调研发现,在现有的一些研究中,尽管尚未正 式引入“视觉知识”的概念,但视觉知识的概念、优 势和特点,已经被初步运用到跨媒体智能中,并取 得了良好的效果。同时,本文设想了将视觉知识应 用在一些新的跨媒体智能任务上能够带来的潜力。 本文选取“视觉知识的结构化表示”、“视觉知识的操作与推理”和“跨媒体重建与生成”三个任务展开 样例研究,讨论视觉知识的应用,并进行分析与展 望。值得指出的是,这三个具体任务仅仅是视觉知 识在跨媒体智能中的部分例子,还存在其它更多的 相关任务。随着基于视觉知识的跨媒体智能的发展, 将会不断出现更多全新、更具挑战性的跨媒体智能 应用和任务。
2.2.1 视觉知识的结构化表示
结构化特征具备可解释属性。虽然手工构造特 征针对多媒体数据进行抽象和刻画的能力相比基于 深度学习的特征而言较弱,但这些描述子往往具有 更强的可解释性。有效的结合手工构造特征和深度 学习特征进行跨媒体表达建模,是视觉知识表达在 跨媒体智能领域的一个典型应用。视觉知识的结构 化表示有助于模型可信性与可解释性的提升。
2.2.2 视觉知识的操作与推理
除了视觉知识表示方式的研究,视觉知识的操 作及视觉知识推理也是研究重点之一。视觉知识的 操作包括重建、关联等,具体指的是基于视觉概念 与视觉关系的运算与推理过程。
2.2.3 跨媒体重建与生成
视觉生成是用计算机图形学和计算机视觉技术 来生成单个或多个物体的图像、视频的技术,在数 据可视化(Klawonn 等,2003;Rehm 等,2006), 计算机动画(Parent,2012),虚拟现实(Kim,2005), 增强现实(Hainich,2006)等领域得到了广泛的应 用。在视觉生成中,解析生成对象的部件结构,有助 于获得外观、形态逼真的生成效果。而视觉知识正 提供了这种支持。这是因为,每一个视觉概念包含 部件空间结构关系,有关动物的视觉概念则还应该 有其对应常见动作的动作结构,这种视觉结构在视 觉生成中能够发挥重要的作用。
3 视觉知识研究的展望
3.1 联合判别式与生成式学习的表达范式
判别式模型一般用于物体识别、检测等任务, 而生成式模型一般用于内容生成、预测、合成等,现 阶段两种模型并未有效统一与整合。视觉知识旨在 进一步利用生成式模型的输出,辅助判别式模型进 行联合表达学习,完成判别式模型与生成式模型的 高效协同训练。整合判别式与生成式模型有助于提 升其可解释能力,渐进式地增强模型鲁棒性。 在视觉知识的联合训练框架下,未来将建立视 觉知识的分解、变换、重建与合成理论。视觉知识的 分解旨在获得视觉概念的组成部分。视觉知识的变 换可实现视觉实体的操作与模拟,进而探索视觉知 识重建与新知识的合成。另一方面,大规模跨媒体 视觉知识数据集的收集和整理是未来的重点工作之 一,这类数据库应整合专家知识、人类先验与丰富 原始数据。对于如何构建这类数据库,未来仍有广 阔探索空间。
3.2 模拟仿真技术的突破
视觉知识将极大程度上改善生成模型的效果、 提升仿真技术的逼真度。未来可利用视觉知识与场 景特性作为先验来提升场景的表达和渲染、实现交 互式的视觉编辑工具与可控的场景物体语义理解。 结合数据驱动与视觉知识的图形学系统将融合数据 与规则的长处,抽取视觉数据典型的语义特征、降 低模型复杂度、提升仿真效率、有效产生新视角与 新场景下的逼真、连续的内容。生成与仿真技术的 突破将在娱乐、工业、医疗等各个行业做出重要贡献。
3.3 可信跨媒体智能
视觉知识理论是提升跨媒体智能鲁棒性、泛化 性、可解释性的研究基础。视觉知识理论的建立是 迈向可信跨媒体智能的重要一步,将有效缓解数据 歧视和偏见,减轻决策偏差,提升模型的公平性。同 时,视觉知识应具备稳定的进化机制,为新知识归 纳、新场景理解提供终身学习能力。在一些关键领 域,如司法、医疗等,利用视觉知识结构化、多粒度 的表征解析能力与整合多源、跨领域数据的优势, 起到决策辅助过程可信可靠、推理过程可复查可解 释,系统性的提升模型泛化能力,为可信跨媒体智 能提供重要保障。
4 总结
本文回顾了跨媒体智能的已有表达方式(手工 设计与深度学习),并分析了当前跨媒体发展的瓶颈。 我们认为,具有多重知识表达能力及层次化、动作 结构化的视觉知识提供了当前跨媒体智能发展所亟 需的重要元素。本文以视觉生成、场景图和跨媒体 知识图谱三个问题为例,分析了视觉知识在跨媒体智能中的应用与优势。我们相信,视觉知识将成为 跨媒体智能进化的新支点。