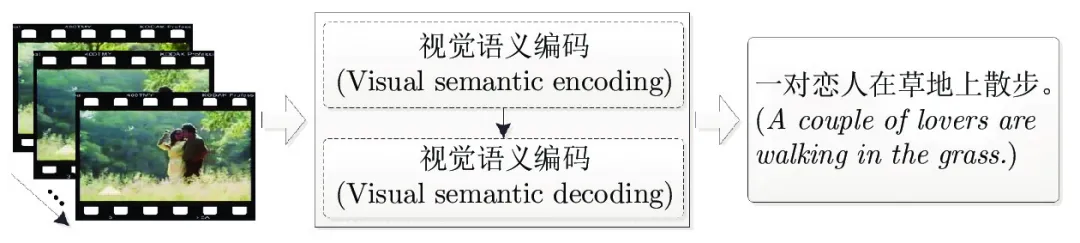
视频标题生成与描述是使用自然语言对视频进行总结与重新表达. 由于视频与语言之间存在异构特性, 其数据处理过程较为复杂. 本文主要对基于“编码−解码” 架构的模型做了详细阐述, 以视频特征编码与使用方式为依据, 将其分为基于视觉特征均值/最大值的方法、基于视频序列记忆建模的方法、基于三维卷积特征的方法及混合方法, 并对各类模型进行了归纳与总结. 最后, 对当前存在的问题及可能趋势进行了总结与展望, 指出需要生成融合情感、逻辑等信息的结构化语段, 并在模型优化、数据集构建、评价指标等方面进行更为深入的研究.
视频标题生成与描述任务是对给定的视频进行特征抽象, 并将其转换为自然语言, 对视觉内容进行结构化总结与重新表达. 它与目前流行的图像描述任务一样, 同属于计算机视觉高层语义理解范畴, 但鉴于视频数据的时空特性与语义的多样性、复杂性, 其比图像描述更具挑战性.
如图1所示, 它不仅需要检测出空间域中的物体、场景、人物等静态要素, 还要能够识别时间域上的动作及事件, 反映各视觉语义对象的时空变化, 最后选择合适的词汇及句式结构将其组合在一起, 形成符合人们表达习惯的描述语句. 该任务对于自动解说、导航辅助、智能人机环境开发等领域应用前景广阔, 在推动旅游、教育及计算机学科本身发展等方面意义巨大. 但由于该任务涉及计算机视觉、自然语言处理, 甚至社会心理学等学科, 数据处理过程较为复杂, 具有很大的挑战性.
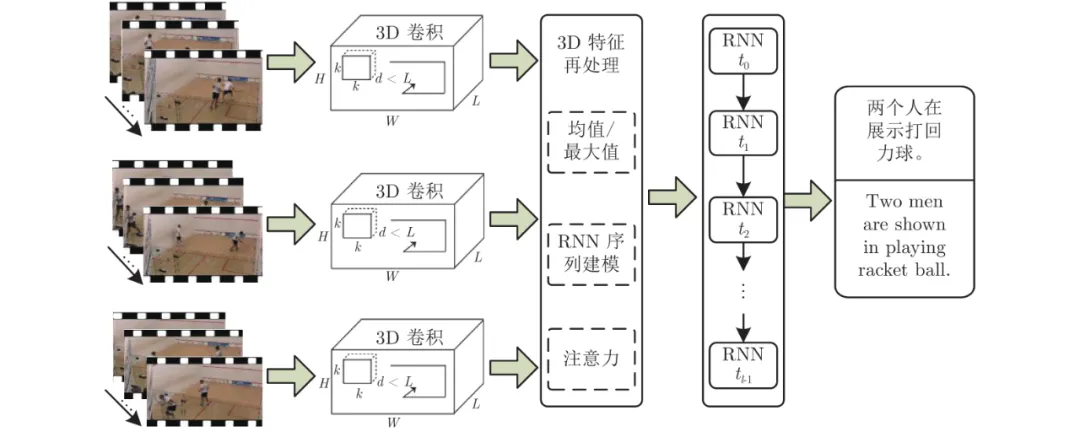
视频标题生成与描述研究历史较为悠久. 在其发展早期, 人们主要借助于SIFT特征(Scale-invariant feature transform, SIFT)[1]、方向梯度直方图特征(Histogram of oriented gradient, HOG)[2]等手工特征, 采用统计的方式对视频内容进行抽象, 提取视频中的语义特征, 然后运用机器学习、分类/识别、检索、检测等技术获取视觉语义对象, 并将其按照预定模板或规则填入相应位置, 组成可读的描述句子[3-6]. 后来, 人们借鉴机器翻译的流程, 设计出能够生成句式更为灵活、用词更为丰富的“编码−解码” 框架结构, 提升了生成句子质量[7]. 但受限于手工特征的表达能力, 其生成的句子在准确性和语义丰富程度等方面与人工表达仍有较大差距, 难以满足人们的需求. 随着深度学习技术的发展, 研究人员使用大规模训练数据对深度卷积神经网络(Deep convolutional neural networks, DCNN)进行优化[8-11], 并将其应用于视频特征提取[12-14]. 深度特征更加抽象, 表达能力更强, 将其与循环神经网络(Recurrent neural networks, RNN)进行结合, 使得生成的句子中词汇更加准确、语义更为丰富. 目前, CNN-RNN框架已成为视觉描述任务的基础架构. 在此基础上, 研究人员结合三维卷积神经网络(3D CNN)[15-16]、门限循环单元(Gated recurrent unit, GRU)[17]、注意力机制[18]、视觉概念/属性机制[19]等, 设计了多种更为复杂的模型与算法, 进一步改善了视频标题与描述的生成质量.
除对简单视频进行高度总结与抽象, 为其生成简单描述之外, 人们也在寻求对更为复杂的视频进行精细化表达, 或以事件/场景变化为依据, 对其中的视觉语义片段进行更为细致的描述, 或者提取整个视频的逻辑语义, 将各片段描述组合为具有一定逻辑结构的描述语段等. 但由于视频数据的复杂性, 各视觉语义对象本身的变化、各对象之间的逻辑关联及其交互等仍存在建模困难、挖掘与利用不充分等弊端. 同时, 将其映射为更为抽象的词汇表达与逻辑语段也在准确性、连贯性及语义性等方面存在较大挑战, 生成的描述难以应用在实际场景中. 此外, 在复杂视频的情感挖掘与个性化表达方面, 目前尚无较为有效的方法与模型, 生成的描述缺乏生动性与吸引力, 且难以对隐含在视频内部的潜在语义及可能的外延信息进行推理显化与表述, 视觉信息与语言之间的语义鸿沟仍然较为明显.
目前已有部分工作对视频描述任务进行梳理与总结, 如Aafaq等总结了当前视频描述的主流方法、数据集和评价指标, 但他们侧重于从学习策略(如序列学习、强化学习等)上对各模型进行归类分析[20]. Li等则从更大的视角出发, 系统总结了视觉(包括图像和视频)到语言的建模范式, 并从视觉特征编码方式的层面上对各视频描述主流工作进行了介绍[21]. 本文参考了他们的思路, 但为了更加详细而清晰地呈现视频标题与描述生成的研究脉络, 首先回顾了视频描述研究的发展历史, 对其中典型的算法和模型进行了分析和总结. 然后对目前流行的方法进行了梳理, 尤其是基于深度网络的模型框架, 以视频特征编码方式为依据, 按照不同的视觉特征提取与输入方式, 将各类模型分别归类到基于视觉均值/最大值特征的方法、基于RNN网络序列建模的方法、基于3D卷积网络的方法, 以及基于混合特征编码的方法. 在每类方法中, 首先对视频简单描述模型进行了举例与概括, 然后对视频密集描述、段落描述等精细化表达模型做了分析与总结. 此外, 还介绍了视频描述任务的各类常用验证数据集及其评价指标体系, 列举了部分典型模型的性能表现, 并对结果进行了对比分析. 最后对视频描述任务面临的问题及可能研究方向进行了阐述与说明.
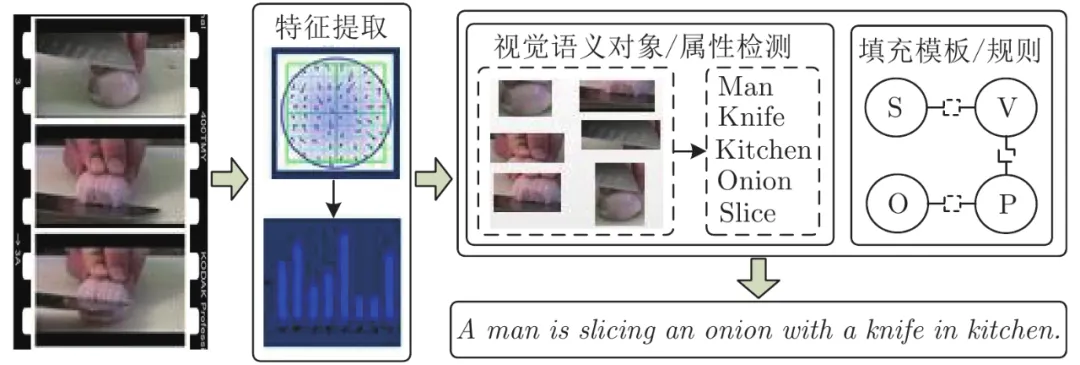
- 基于模板/规则的视频描述 不同于静态图像, 视频中的视觉内容是动态可变的, 在静态的二维数据基础上, 增加了时间维度, 蕴含的视觉信息更为丰富, 但数据结构也更为复杂. 在为视频生成标题与描述时, 不仅需要考虑每帧上的视觉语义对象, 还需要兼顾对象随着时间的变化及其与环境、其他语义对象的交互. 同时还要考虑多尺度时空上的上下文信息, 对视觉信息进行高度抽象, 并将其表现在生成的描述语句中. 正是由于视频携带了更为丰富的视觉信息, 人们一般认为视频标题生成与描述更具有现实意义, 在自动解说、监控理解等方面具有巨大的应用价值, 因此其发展历史也更为悠久. 在具体方法方面, 早期研究者主要是结合基于模板或固定规则的框架, 设计手工特征从视频中获取视觉语义表达, 或使用识别检测技术检测出人物、动作、场景等, 将其填入预设的语句模板中, 或按照固定规则组合成描述语句. 其基本框架如图2所示.
- 基于神经网络的视频描述 基于模板或规则的视频描述方法其弊端较为明显, 生成的描述句子在语法结构、语义表达等方面都不够灵活. 目前, 随着深度学习技术的广泛应用, 人们也将其应用在视频描述领域中, 从视频特征编码, 到描述语句生成, 设计了多种有效的模型与方法, 大幅提升了模型性能, 有效改善了生成语句的质量. 具体表现在, 人们参考机器翻译与图像描述中流行的做法, 使用深度卷积神经网络及三维卷积神经网络等对视频进行特征编码, 然后使用RNN网络对视觉特征进行解码, 逐个生成词汇并组成句子. 其通用框架与图像描述类似, 是将视频作为“源语言”, 将待生成句子作为“目标语言”. 在整个过程中, 其语句的语法、句型结构等不再通过人为设定模板或规则进行干预, 而是直接从训练数据中进行自主学习并记忆. 目前, 基于神经网络的流程与框架, 研究者已开发出多种效果显著的模型与算法. 但不同方法之间差异巨大, 所结合的相关技术涵盖了时序特征编码、检索与定位、注意力机制、视觉属性、对抗学习、强化学习等. 本文主要从视觉特征编码的角度对相关工作进行归纳与梳理, 对各模型与方法的设计动机、原理及所使用的技术进行详细分析.
3 相关数据集与评价方法 视频标题生成与描述的验证与评价比其他传统的视觉任务(如分类识别[8-11]、目标检测[101-103]、图像/视频检索[104-105]等)更加复杂. 在对生成的标题与描述进行统计分析时, 其评价指标不仅需要对词汇预测的精度、句子长度、连贯性进行评价, 还需要对句子的语义丰富程度进行衡量. 在验证数据集的构建方面, 不仅需要考虑视频的类型、复杂程度, 在标注时, 还需要兼顾用词的准确性、与视频内容的关联度, 以及整条句子的连贯性与语义性, 构建过程较为耗时、费力. 而对于更高层次的视频理解与描述任务, 如融合情感、个性化及隐含语义挖掘的视频描述, 其评价指标的设计与数据集构建更为困难. 目前, 针对视频简单描述、密集描述与结构化描述, 已出现多个公开的数据集; 同时, 人们也借鉴机器翻译中的BLEU (Bilingual evaluation understudy)[106]、METEOR (Metric for evaluation of translation with explicit ordering)[107]、ROUGE-L (Recall-oriented understudy for gisting evaluation)[108]等评价方法, 并将其引入到视觉描述任务中, 对生成的描述进行多方面的考量. 本节对目前常用的视频描述数据集、相关评价方法, 以及部分模型性能进行了梳理与总结。
- 总结与展望 视频描述任务与图像描述类似, 都是将非结构化的视觉数据转换为结构化的自然语言, 其间使用中间语言(视觉特征)进行桥接, 以机器学习技术(尤其是深度学习技术)为支撑, 运用多种计算机视觉和自然语言处理技术, 为视频生成准确、连贯且语义丰富的描述句子. 目前, 针对图像标题生成与描述, 人们已开发出多种效果显著的模型与方法, 在图像简单描述[18-19, 63-64, 121-124]、图像密集描述[50, 125-127]、结构化段落描述[128-129], 以及情感及个性化描述[69, 95-99]等方面均开展了卓有成效的研究工作. 但由于视频在静态图像的基础上增加了时间维度, 其数据更为复杂, 信息更为丰富, 视觉语义提取与挖掘更加困难, 为其生成可靠且质量较高的描述语句的挑战性也更大. 目前人们已借鉴机器翻译任务的流程与框架, 结合图像标题与生成中的多种技术, 使用3D卷积网络、RNN序列建模机制、注意力机制、视觉属性、视觉概念、层次化序列记忆网络、强化学习技术等, 设计出一系列效果显著的方法与模型, 已能为视频生成简单描述语句, 或为部分视频生成密集描述/结构化描述语句, 推进了视频标题生成与描述任务的进展.
本文系统回顾了视频标题与描述生成的研究历史, 分析了其研究现状与前沿动态, 对当前的主流模型进行了梳理、归纳, 并指出了部分模型的优越性及可能的局限性. 在未来的工作中, 以下几个方面值得进一步研究与探索:
-
在含有多个场景、人物及事件的复杂视频中, 对其逻辑语义的发现、表征及嵌入的研究尚存在大量空白. 在具体研究中, 不仅要分析视觉信息中各物体、人物、事件之间的关系, 还需要将其映射为自然语言的具体成分, 合理地嵌入到生成的句子中, 实现视频的精细化、结构化表达与描述. 为解决该问题, 一方面可借助于视觉推理技术, 以目标识别与检测等方法完成视觉对象的感知与发现, 以关系检测、图网络等方法发现并构建相应的视觉关系及其演化拓扑, 完成视觉关系的知识图构建与关联推理; 另一方面, 研究视觉关系与语言逻辑之间的映射与转换, 合理使用视觉属性、视觉概念等先验知识, 设计更为鲁棒的层次化序列模型, 实现视觉关联语义到语言逻辑语义的自然嵌入.
-
视频描述模型的学习代价比一般的分类、识别等任务更为高昂, 其训练数据的收集与标注常耗费大量的人力与物力, 且质量也难以管控. 针对这一问题, 可借鉴零样本与小样本学习技术, 通过样本中的概念与属性推理, 以较少的训练数据实现模型较为充分的优化, 生成较为流畅、语义较为丰富、质量较为可靠的描述句子. 同时也可结合迁移学习及强化学习策略, 引入域外知识, 对模型参数进行快速优化, 或通过不断试错, 增强模型对于正确解的敏感程度, 实现模型在样本受限情况下的自主学习. 除研究模型的优化策略外, 同样也需要构建更为完备的相关数据集, 对其构建方法、标注规则及其质量管控等方面作出更为有益的尝试, 以质量更优的训练数据推进视频描述任务走向实际应用.
-
在各种复杂视频中, 尤其是包含人物的视频, 其内容常包含丰富的情感变化及隐含语义, 同时不同的视频内容对人们也会产生相应的情感影响或个人理解. 而目前人们在研究视频描述时, 往往只关注其中的事实表达, 对情感、个性化及隐含信息关注较少, 造成生成的句子趣味性、可读性不强. 为此, 需要结合人类的情感心理及视觉情感发现技术, 在表情、动作及上下文语义环境上建立其与情感的映射关系, 并通过视觉属性/概念、注意力机制等技术将情感及个性化信息有机嵌入到生成的句子中. 同时加强对视频描述可解释性的研究, 构建相应的知识图谱, 并结合零样本学习策略, 通过对现有知识的学习, 对视觉信息之外的隐含语义进行预测和推理, 进一步增强生成句子的可用性.
-
视觉描述任务的评价内容及过程比其他视觉任务更加复杂, 不仅需要判断生成句子对于视频中物体、人物、动作及关系描述的准确性, 还需要对句子的连贯性、语义性及逻辑性进行衡量. 目前的策略多是借鉴机器翻译的评价指标, 评价内容较为单一. 当前虽然也有如CIDEr、SPICE等面向视觉描述任务的评价方法, 但在一些更具针对性的评价任务中, 如对于情感、个性化及逻辑语义的判断与评价, 这些方法都难以对其进行有效的衡量. 因此, 需要结合现有的评价方法设计思路, 开发更为合理的具有针对性及综合性的指标体系, 为模型及其描述提供更为客观、公平的评价机制, 尤其是为强化学习的模型优化方法, 提供更为贴近人们描述与评价习惯的学习与反馈策略.