基于文档的对话技术研究

基于文档的对话是目前对话领域一个新兴的热点任务.与以往的任务不同,其需要将对话信息和文档信息综合进行考虑.然而,先前的工作着重考虑二者之间的关系,却忽略了对话信息中的句子对回复生成的作用具有差异性.针对这一问题,提出了一种新的辩证看待对话历史的方法,在编码阶段讨论利用历史和忽略历史2种情况进行语义信息的建模,并采用辩证整合的方式进行分支信息的汇总.由此避免了在历史信息与当前对话不相关时,其作为噪声被引入进而损害模型性能,同时也强化了当前对话对信息筛选的指导作用.实验结果表明,该模型与现有基线相比,能够生成更为符合当前语境且信息量更加丰富的回复,从而说明其能够更好地理解对话信息并进行知识筛选.并且通过进行消融实验,也验证了各模块在建模过程中的有效性.
https://crad.ict.ac.cn/CN/abstract/abstract4370.shtml
近年来,随着大数据的发展以及深度学习技术的兴起,对话系统这一研究领域已经取得了长足的进步.由于Seq2Seq(sequence-to-sequence)模型[1]的出现,许多模型采用了端到端的方式并基于大规模的人类对话语料进行训练,已经收到了一定的效果.然而,上述方法的问题在于其总是倾向于生成较为通用的回复[2],这也是目前该领域面临的一大挑战.
事实上,通过引入外部知识使得模型生成信息更加丰富的回复,正逐渐成为这一问题可能且可行的方法之一.并且到目前为止,已经出现了一些富有建设性的成果.Ghazvininejad等人[3]是对一组候选事实进行检索,然后将其结果与对话信息相结合.Zhang等人[4]借助说话人的个人资料,使得模型可以生成一致性更好且更吸引人的对话.而Mem2Seq[5]则通过引入外部知识库的方式,以提升回复内容的丰富度.但是,这些工作大多是将现有的事实类知识整合到对话系统中,而此类知识的构建过程费时费力,且具有较大的局限性.从而在一定程度上制约了大规模数据的使用,以及现有系统的应用和落地.
基于文档的对话是一项在讨论特定文档的内容时,生成较自然对话回复的任务.与以往基于知识的对话不同,该任务采用文档作为知识源,因此能够使用较为广泛的知识,且无需对其预先进行构建.并且其与基于文档的问答也有所不同,相较于后者此时不仅需要考虑对话与文档之间的关系,同时还应考虑对话内部的联系以对其充分理解.针对这一任务,我们应主要从3个方面进行考虑:1)理解对话中各句之间的关系;2)理解对话与文档之间的关系;3)根据对话上下文,从文档中筛选有关信息以生成相应回复.
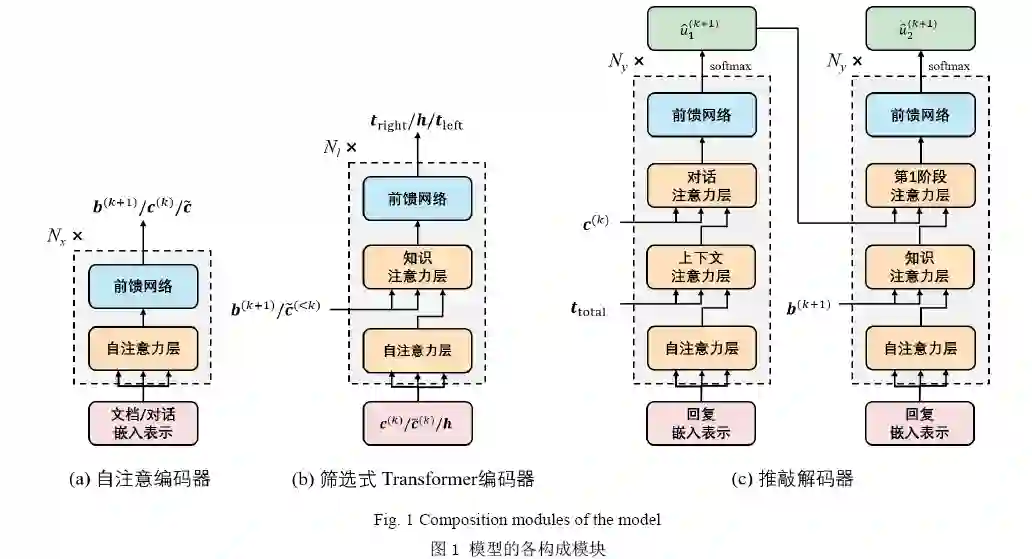
在本文中,我们提出了一种新颖的基于Transformer[6]的模型,用于更好地构建对话上下文,并利用其进行信息筛选从而生成更有意义的回复.主要思想是将信息筛选分为利用历史和忽略历史两种情况进行讨论:当忽略历史时,只需以当前对话为依据,对文档信息进行相应筛选;而当考虑历史时,应先利用其对上下文进行重新建模,然后以所得结果为依据,进行文档信息的筛选.注意到对话历史事实上并不总是与语境相关,因此在完成上述过程后我们需要对其与当前对话的相关程度进行度量,并以此为依据进行语义向量的整合,以避免引入不相关的信息作为噪声.实验结果表明,与现有的基线模型相比,我们的模型能生成语义更加连贯、知识更为丰富的回复.
本文的主要贡献可总结为以下3点:
1)提出了一种辩证看待对话历史的方法,用于文档信息的筛选以及上下文信息的构建.在编码过程
中,以分支的方式同时进行利用历史和忽略历史的信息筛选,并根据当前语境判断各分支的重要程度.
2)提出了一种新的信息汇总的方式,通过判断当前对话与历史之间的相关程度,来对各分支所得到的信息进行整合,以得到在解码过程中所使用的语义向量.
3)在CMU-DoG数据集[7]上进行了模型的验证,并取得了当前已知的最好效果.同时借助消融实验,也显示出模型各个部分在语义向量建模过程中的有效性.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DCTS” 就可以获取《基于文档的对话技术研究》专知下载链接



