
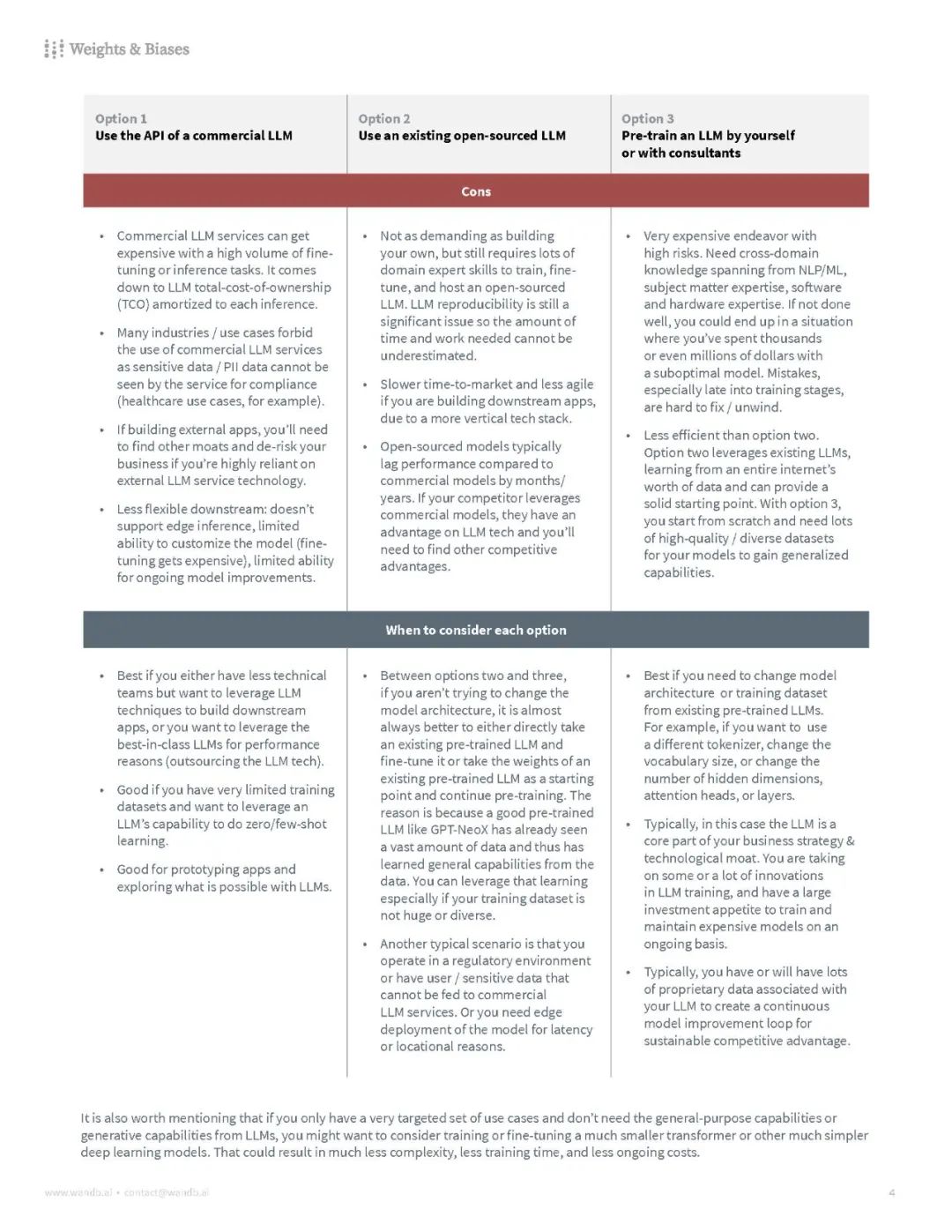
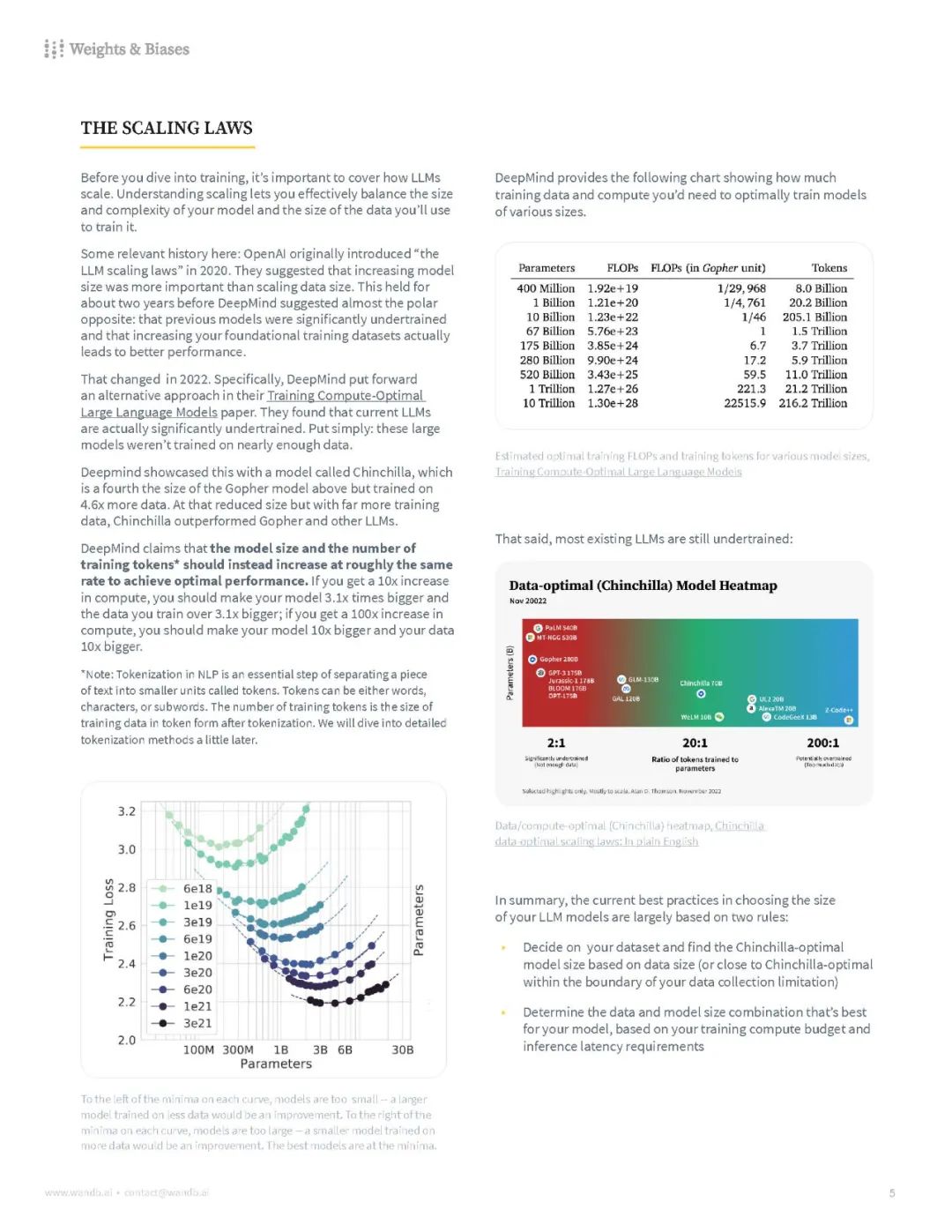
【白皮书《从头训练LLM最佳实践》,涵盖了数据集、硬件、分布式训练、RLHF 等方面的内容——需要多少数据才能训练出有竞争力的LLM、平衡内存和计算效率、并行化的不同技术、标记化策略及其权衡、模型评估、如何减少建模中的偏见和有害信息等等】《Current Best Practices for Training LLMs from Scratch | Weights & Biases 》 尽管我们离变换器(transformer)的突破只有短短几年的时间,但LLMs(大型语言模型)在性能、成本和潜力上已经大幅增长。在W&B,我们有幸看到比任何其他人都多的团队试图构建LLMs。但是,许多关键的细节和关键的决策点经常是口口相传的。这篇白皮书的目标是提炼从零开始训练自己的LLM的最佳实践。我们将涵盖从规模和硬件到数据集选择和模型训练的所有内容,让您知道应该考虑哪些权衡,并在途中标出一些可能的陷阱。这旨在是一个对从零开始训练LLM时您将做出的关键步骤和考虑因素的相当详尽的看法。您首先应该问自己的问题是,从零开始训练一个是否适合您的组织。



成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年10月9日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月9日