深度学习中最常见GAN模型应用与解读
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
生成对抗网络常见应用场景与各种扩展模型
生成对抗网络应用与基本原理
2014年Ian Goodfellow首次提出Generative adversarial networks (生成对抗网络)简称GANs,生成对抗网络就开始在计算机视觉领域得到广泛应用,成为对有用的视觉任务网络之一,也是如今计算机视觉热点研究领域之一,其已经出现的应用领域与方向如下:
图像数据集生成
生成人脸照片
生成真实化照片
生成卡通照片
图像翻译
文本到图像翻译(Text2Image Translation)
图像语义道照片翻译(Semantic-Image2Photo Translation)
人脸正面视图生成(Face Frontal View Generation)
新姿态生成(Generate New Human Poses)
照片到卡通漫画翻译
照片编辑
人脸年龄化
照片融合(Photo Blending)
超像素(Super Resolution)
照片修复(Photo Inpainting)
视频预测(Video Prediction)
三维对象生成(3D Object Generation)
GAN网络主要由生成网络与鉴别网络两个部分,生成网络负责生成新的数据实例、鉴别网络负责鉴别生成的数据实例与真实数据之间的差异,从而区别哪些是真实数据、哪些是假数据。
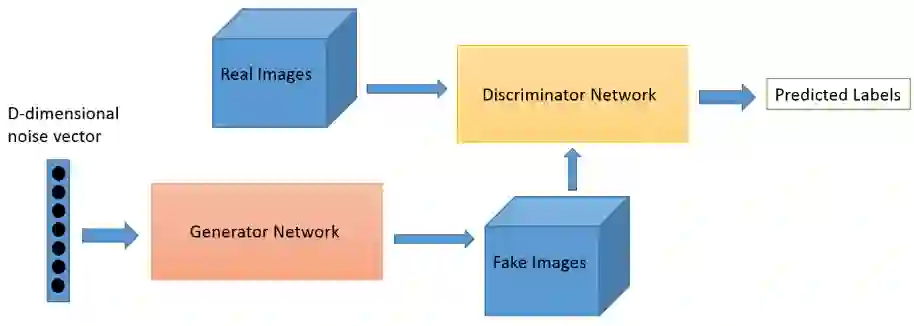
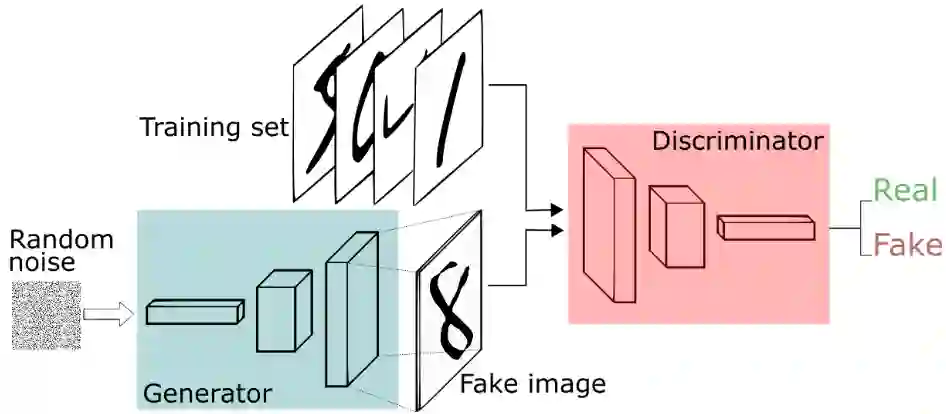
以mnist手写数据集为例、GAN网络工作的流程如下:
1.生成网络从随机数据开始,生成一张图像
2.生成的图像被输入到鉴别器中、鉴别器判断它与ground truth数据之间的差异
3.鉴别网络分别考虑他们真假的可能性
得到两个网络的反馈
1.鉴别网络循环反馈数据与ground truth之间的差异
2.生成网络持续接受鉴别网络的反馈,不断优化生成器网络
图示如下:
常见的生成对抗网络模型
Generative Adversarial Network (GAN)
2014年Ian Goodfellow首次提出GAN模型结构,可以生成各种图像数据集,论文地址
https://arxiv.org/pdf/1406.2661.pdf运行效果如下:

该模型的缺点是生成的图像细节不是很好,特别对彩色与细节较多的图像的,对它一个最简单的改进就是另外基础GAN模型。
Deep Convolutional Generative Adversarial Network简称DCGAN
论文地址如下:
https://arxiv.org/pdf/1511.06434.pdf简单的说DCGAN就是GAN的扩展版本,生成网络与鉴别网络都是基于深度神经网络构成,对细节生成更加的真实。

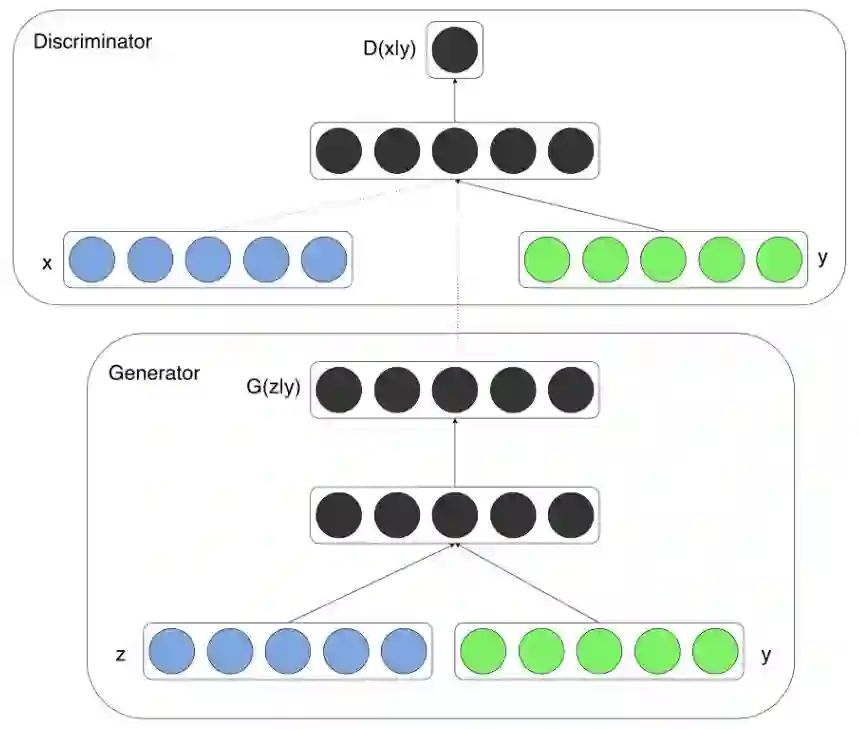
Conditional Generative Adversarial Network 简称cGAN
论文地址如下:
https://arxiv.org/pdf/1411.1784.pdfcGAN比GAN来说是多了两个条件输入,分别针对生成网络与鉴别网络,图示如下:
https://arxiv.org/pdf/1611.07004.pdf最典型就是pix2pix模型,相关的效果如下:

Information Maximizing Generative Adversarial Network (InfoGAN)
论文地址如下:
https://arxiv.org/pdf/1606.03657.pdf信息GAN是对GAN的改进,在输入生成模型阶段采用更多的信息输入,可以控制样本生成的各种隐式特征,以mnist数据集为例,通过输入隐式信息可以控制数字的旋转与字符的宽度,生成包含隐式信息的新数据集,运行效果如下:

Conditional Image Synthesis with Auxiliary Classifier GANs - ACGAN
论文地址
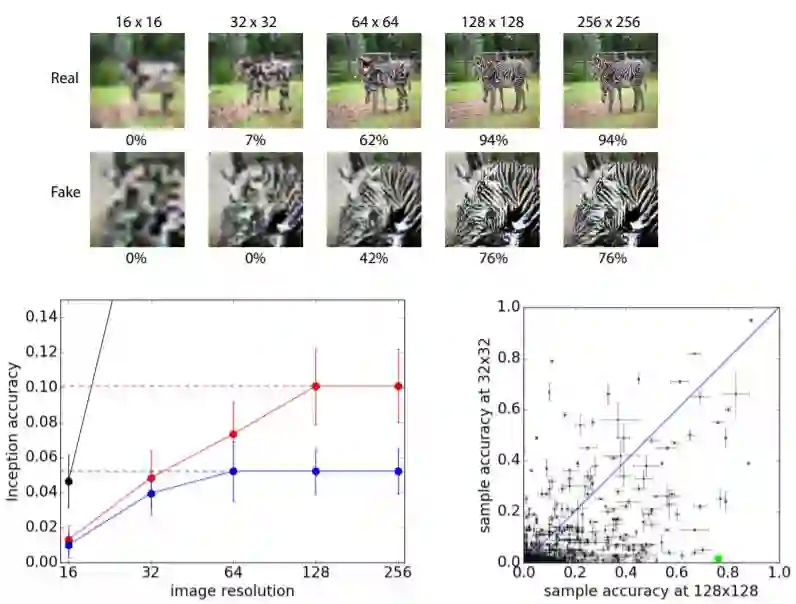
https://arxiv.org/pdf/1610.09585.pdf这个是在GAN的基础上提升图像生成的质量,通过对生成网络添加一个辅助的分类标签来提升生成图像的质量,通过对鉴别器分别对图像与标签分布做预测,从而提升最终生成图像多样性与可鉴别性。生成高分辨率图像提升可鉴别性:
CycleGAN(Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks)
论文地址
https://arxiv.org/pdf/1703.10593.pdf通过循环一致性GAN网络实现图像到图像的翻译问题,是条件GAN扩展与升级版本,关于这个模型最经典的视频就是把马变成斑马的那个视频,论文提供的部分效果如下:

Stacked Generative Adversarial Network (StackGAN)
论文地址如下:
https://arxiv.org/pdf/1612.03242.pdf实现了从文本到图像的翻译,根据文本描述自动生成图像内容,可以说是一个很科幻的GAN模型,它把文本描述到图像生成的翻译分为两个stage,实现了高质量的文本到图像的翻译。
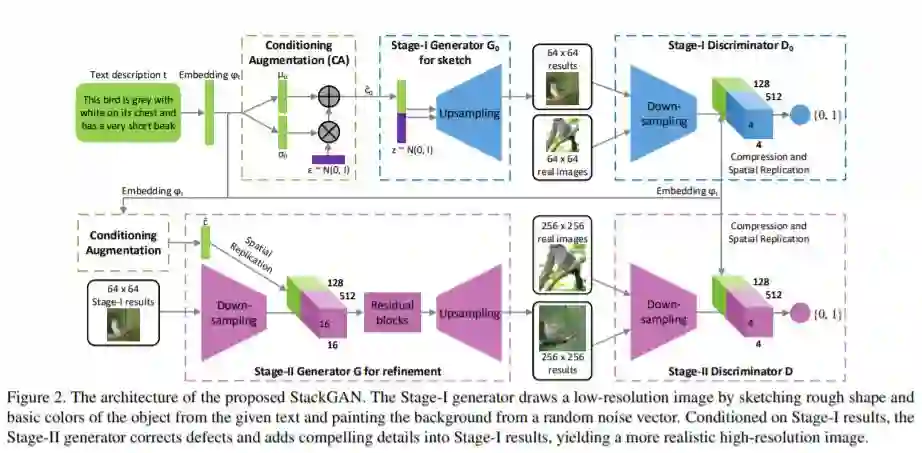
论文中演示的效果如下:

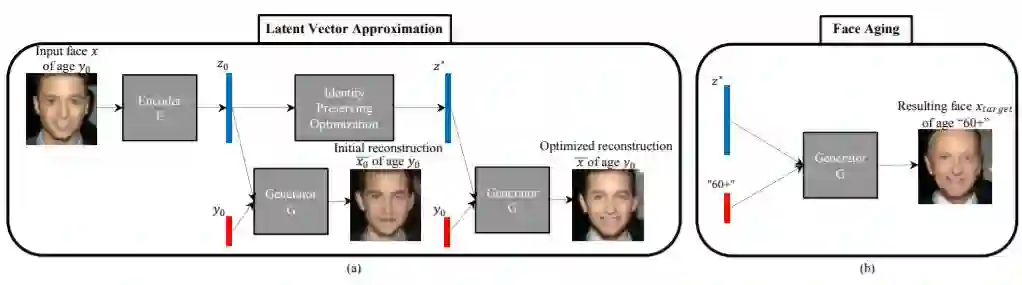
Face Aging With Conditional Generative Adversarial Network (Age-cGAN)
论文地址
https://arxiv.org/pdf/1702.01983.pdf人脸老化或者是年龄化人脸生成在跨年龄的人脸识别、寻找失散儿童、数字娱乐脸谱生成等方向都发挥了重要作用,基于cGAN的人脸生成很好的克服了传统人脸老年化不真实与人脸特征丢失的弊端。基于GAN提出了Age-cGAN模型,首先基于年龄条件生成指定年龄的人脸,通过隐式的向量优化保持输入人脸的结构特征,重建输入人脸。首先根据输入的人脸与年龄生成人脸,然后根据得到隐式向量优化重建得到特征跟输入原图一致的aging face,模型的结构如下:
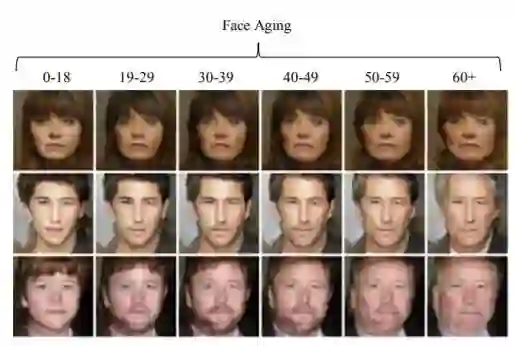
论文中生成的年龄化人脸分为六个级别,显示如下:
Pixel-Level Domain Transfer
论文地址
https://arxiv.org/pdf/1603.07442.pdf根据源域的对象实现目标域对象生成,完成语义级别的对象迁移,同时实现像素级别的图像生成。完整的网络架构如下:
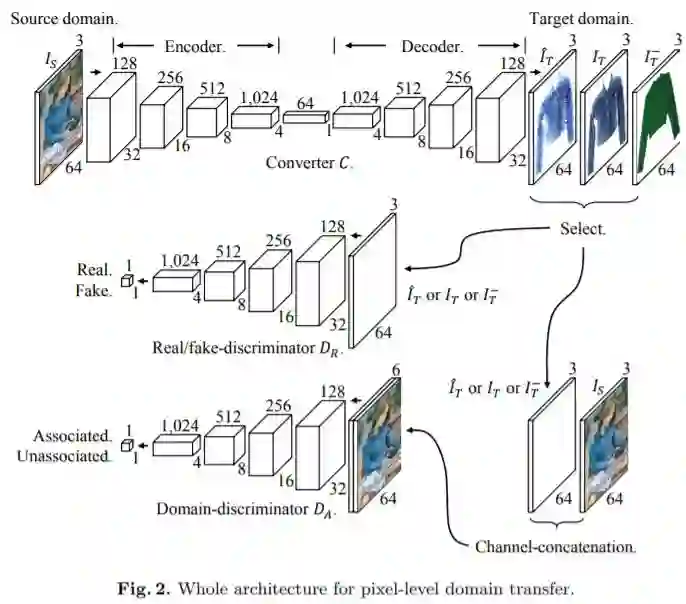
迁移效果如下:

Context Encoders: Feature Learning by Inpainting
论文地址
https://arxiv.org/pdf/1604.07379.pdf通过Encoder与Decoder网络+对抗生成网络实现图像修复功能,这里的Encoder与Decoder网络都是全卷积网络,在Encoder的最后一层通过全通道链接实现信息传递,然后通过五个反卷积层实现修复区域生成,网络结构如下:

运行结果如下:

Unsupervised Cross-Domain Image Generation
论文地址
https://arxiv.org/pdf/1611.02200.pdf
https://arxiv.org/pdf/1708.05509.pdf基于GAN实现跨域图像生成,生成各种表情图像/卡通图像,DTN网络的结构如下:
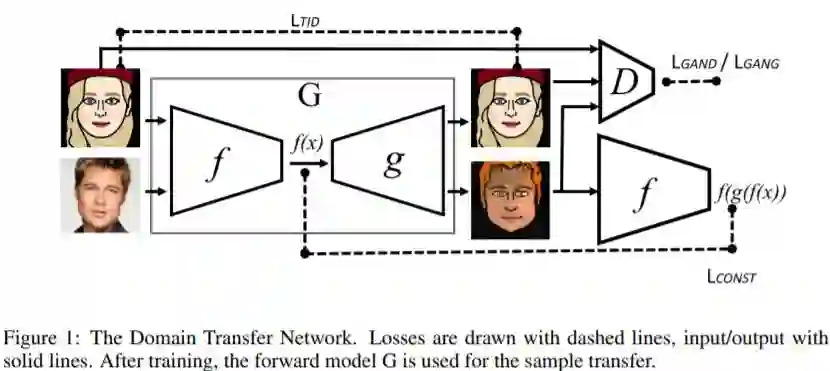
网络训练完成以后,运行效果如下:

可以说GAN相关的模型是深度学习所有模型中很神奇的存在、GAN的很多应用却都让人节操碎一地,换脸脱衣去马赛克的文章都曾火爆一时、引发广泛关注。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读
最新AI干货,我在看



