【导读】本文为大家带来了一份斯坦福大学的最新课程CS330——深度多任务和元学习,主讲人是斯坦福大学Chelsea Finn,她是斯坦福大学计算机科学与电气工程系的助理教授,元学习大牛。
她的博士论文——基于梯度的元学习(Learning to Learn with Gradients)很值得一读,该论文系统性地阐述了Meta Learning以及她提出的MAML的方法和相关改进。作者从Meta Learning问题出发,然后提出了MAML理论,再进行一系列基于该理论的应用尝试。
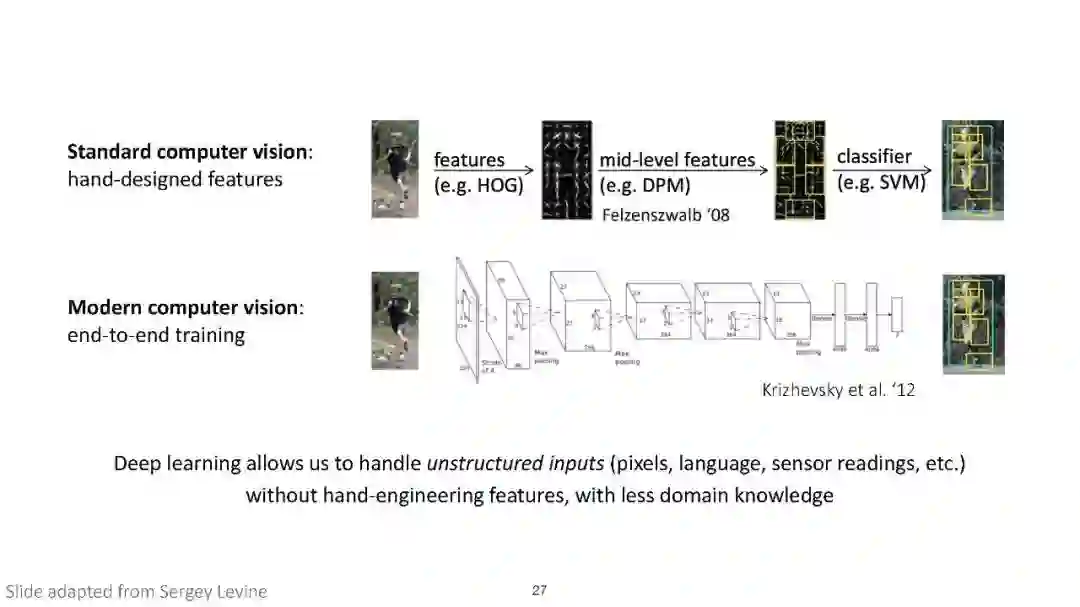
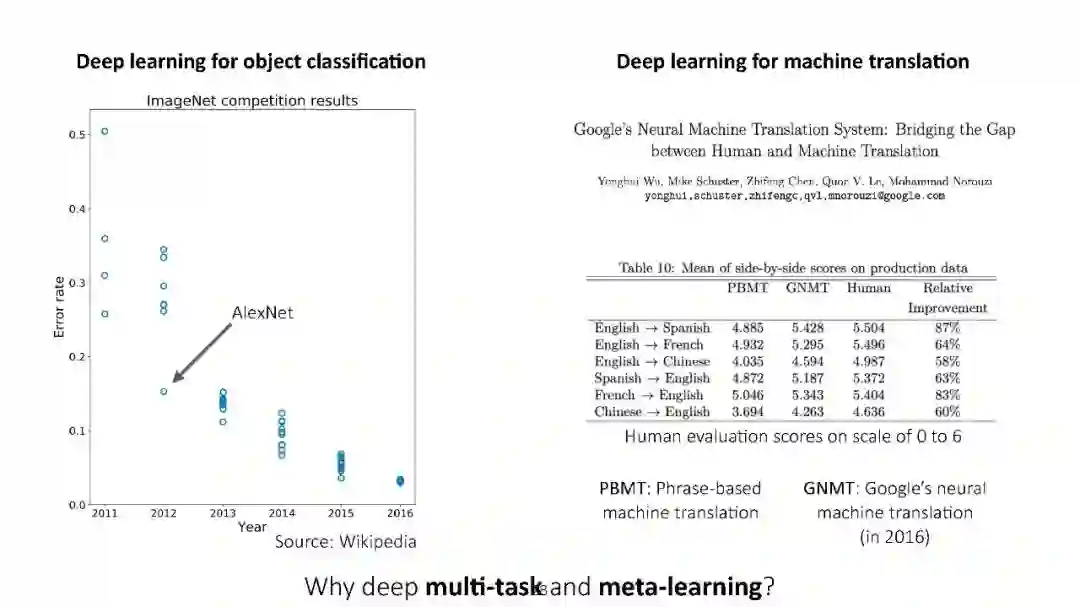
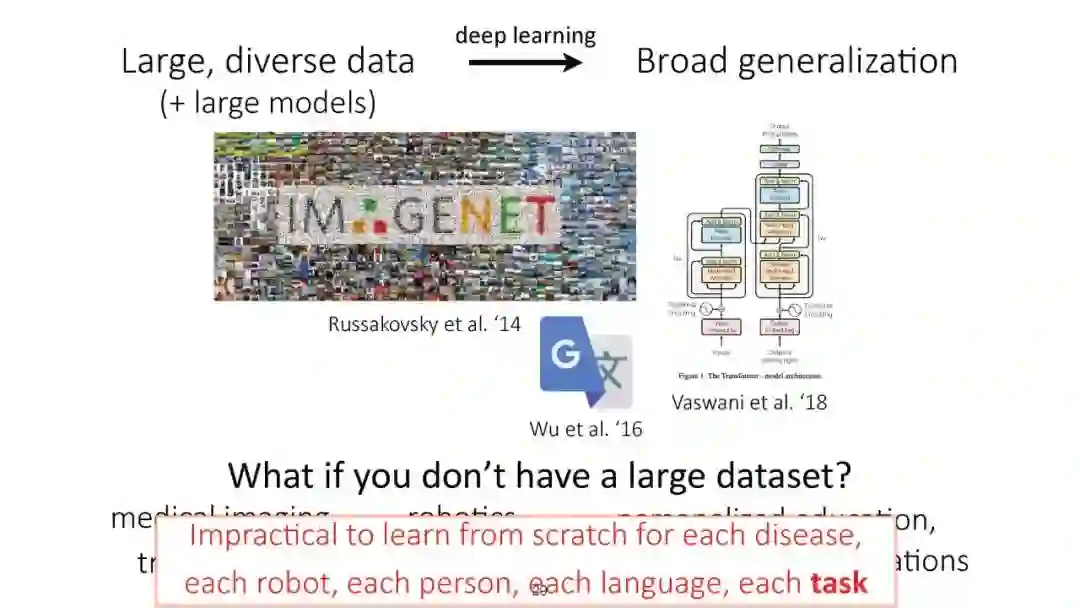
尽管深度学习在图像分类、语音识别和游戏等有监督和强化学习问题上取得了显著的成功,但这些模型在很大程度上是专门用于训练它们的单一任务的。本课程将涵盖需要解决多个任务的环境,并研究如何利用多个任务产生的结构来更有效地学习。
介绍
尽管深度学习在图像分类、语音识别和游戏等有监督和强化学习问题上取得了显著的成功,但这些模型在很大程度上是专门用于训练它们的单一任务的。本课程将涵盖需要解决多个任务的环境,并研究如何利用多个任务产生的结构来更有效地学习。
这包括: * 以目标为条件的强化学习技术,它利用所提供的目标空间的结构来快速地学习多个任务; * 元学习方法旨在学习可以快速学习新任务的高效学习算法; * 课程和终身学习,其中问题需要学习一系列任务,并利用它们的共享结构来实现知识转移。
这是一门研究生水平的课程。在课程结束时,学生将能够理解和实施最先进的多任务学习和元学习算法,并准备对这些主题进行研究。
课程链接: https://cs330.stanford.edu/
形式
这门课是演讲和阅读的结合。讲座将讨论理解和设计多任务和元学习算法所需的主题基础。在阅读课程中,学生将介绍并讨论最近在这一领域的贡献和应用。
预备知识(Prerequisites)
需要CS 229或同等的入门机器学习课程。推荐CS 221或类似的入门人工智能课程,但不是必需的。
** 注册登记(Enrollment)**
如果你对这门课程感兴趣,请填写这张报名表。有关注册的更多信息,请参见表格。
- 主讲:Prof. Chelsea Finn

Prof. Chelsea Finn是斯坦福大学计算机科学与电气工程系的助理教授。她的实验室IRIS通过大规模的机器人互动研究智能,并且隶属于SAIL和Statistics ML Group。她还作为Google Brain团队的一员在Google工作。
她对机器人和其他代理通过学习和交互发展广泛的智能行为的能力感兴趣。
在此之前,她在加州大学伯克利分校获得了计算机科学博士学位,在麻省理工学院获得了电气工程和计算机科学学士学位。
Chelsea Finn 年纪轻轻就已成为机器人学习领域最知名的专家之一。她开发了很多教机器人控制和操纵物体的高效方法。例如,她提出使用 MAML 方法教机器人抓取和放置物体技能,该过程中仅仅用了一个人类演示视频中的原始像素。
个人主页:http://ai.stanford.edu/~cbfinn/
**
课程安排
- 课程安排 01: 课程介绍,多任务学习开始(Course introduction & start of multi-task learning)
02:多任务学习(multi-task learning)
03: 迁移学习精调,Transfer learning & fine-tuning
04:元学习,问题陈述,黑盒元学习 (Meta-learning problem statement, black-box meta-learning (Chelsea Finn))
05:基于优化的元学习(Optimization-based meta-learning)
06:通过度量学习进行少量学习(Few-shot learning via metric learning)
07:用于少样本学习的无监督预训练(对比) Unsupervised pre-training for few-shot learning (contrastive)
08:用于少样本学习的无监督预训练(对比) Unsupervised pre-training for few-shot learning (generative)
09: 元学习主题进展 (Advanced meta-learning topics (Chelsea Finn))
10:贝叶斯元学习 Bayesian meta-learning (Chelsea Finn)****
11:强化学习入门,多任务RL,目标条件RL(Renforcement learning primer, multi-task RL, goal-conditioned RL)
12:Meta-RL,学习探索(Meta-RL, learning to explore)
13:用于多任务学习的基于模型的RL,基于元模型的RL(Model-based RL for multi-task learning, meta model-based RL)
14:终身学习:问题陈述,前后迁移(Lifelong learning: problem statement, forward & backward transfer)
15:前沿: 记忆,无监督元学习,开放性问题(Frontiers: Memorization, unsupervised meta-learning, open problems)