

通过使用像BERT这样的预训练语言模型(PLMs),自然语言处理(NLP)已经发生了革命性的变化。尽管几乎在每个NLP任务中都创造了新记录,但PLM仍然面临许多挑战,包括可解释性差、推理能力弱,以及在应用于下游任务时需要大量昂贵的注释数据。通过将外部知识集成到PLM中,知识增强的预训练语言模型(KEPLMs)有可能克服上述限制。本文通过一系列研究对KEPLMs进行了系统的考察。具体地,概述了可集成到KEPLMs中的知识的常见类型和不同格式,详细介绍了现有的构建和评估KEPLMs的方法,介绍了KEPLMs在下游任务中的应用,并讨论了未来的研究方向。研究人员将从这项调研中受益,通过获得该领域最新发展的快速和全面的概述。
https://www.zhuanzhi.ai/paper/08b18a51703942d4625d10b8f6cb8e4b
1. 引言
预训练语言模型(PLMs)首先在大型数据集上进行训练,然后直接迁移到下游任务,或在另一个小型数据集上进一步微调,以适应特定的NLP任务。早期的PLMs,如Skip-Gram[1]和GloVe[2],是浅层神经网络,其词嵌入(从窗口大小的上下文中学习)是静态语义向量,这使得它们无法处理动态环境下的一词多义问题。随着深度学习的发展,研究人员试图利用深度神经网络来通过动态语义嵌入来提高任务的性能。起初,人们仍然局限于监督学习的范式,认为没有足够的标记数据,很难释放深度学习的潜力。然而,随着自监督学习的出现,BERT[3]等大型语言模型可以通过预测事先被掩盖的标记,从大规模无标记文本数据中学习大量知识。因此,他们在许多下游NLP任务中取得了突破性进展。此后,许多大型模型开始采用Transformer[4]结构和自监督学习来解决NLP问题,plm逐渐进入快速发展阶段。PLMs最近的惊人成功是OpenAI的ChatGPT。随着研究的进展,人们发现PLMs仍然面临可解释性差、鲁棒性弱和缺乏推理能力的问题。具体来说,PLMs被广泛认为是黑盒,其决策过程是不透明的,因此很难解释。此外,PLMs可能不够鲁棒,因为深度神经模型容易受到对抗性样本的影响。此外,由于纯数据驱动,PLMs的推理能力也受到限制。PLMs的所有这些缺点都可以通过纳入外部知识来改善,这就产生了所谓的知识增强的预训练语言模型(KEPLMs)。图1用ChatGPT的话说就是KEPLMs的优势。

尽管目前对KEPLMs 中[5]、[6]、[7]、[8]的研究尚不多见,但随着许多新技术的出现,该研究领域正在迅速发展和扩展。本综述旨在从不同的角度为人工智能研究人员提供关于KEPLMs 最新进展的最全面和最新的图景。 本综述的其余部分组织如下。第2节解释了KEPLMs 的背景。第3节对keplm常用的知识类型和格式进行了分类。第4节介绍了构建keplm的不同方法。第5节描述了评估KEPLMs 可能的性能指标。第6节讨论了KEPLMs 在下游知识密集型NLP任务中的典型应用。第7节概述了KEPLMs 的未来研究方向。第8节总结了贡献。
构建 KEPLMS
隐性知识整合
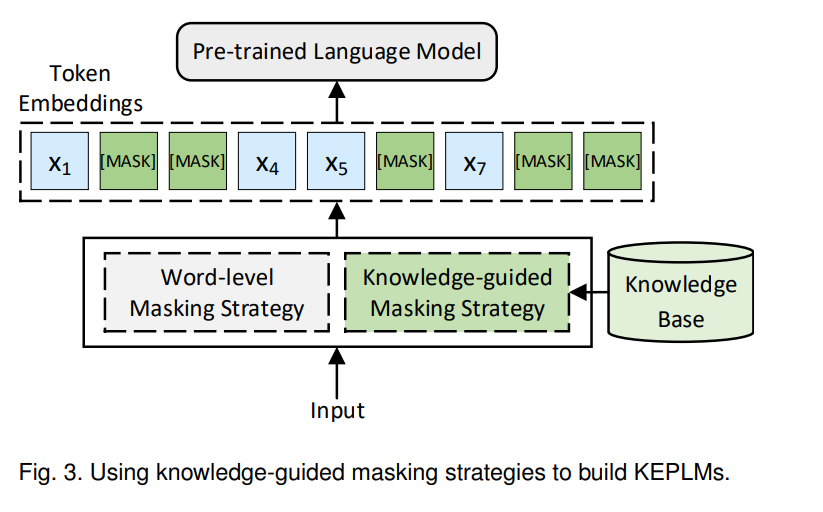
以BERT为代表的PLMs 通常使用维基百科等的非结构化文本文档作为预训练的语料库。非结构化文本数据包含丰富的上下文语义信息,BERT可以通过掩码语言模型(MLM)从中学习单词的上下文知识。然而,文本中同样包含有价值信息的实体和短语被忽略了。通过采用知识引导的超越单个单词层面的掩码策略,PLMs 能够融合实体、短语等知识,如图3所示。
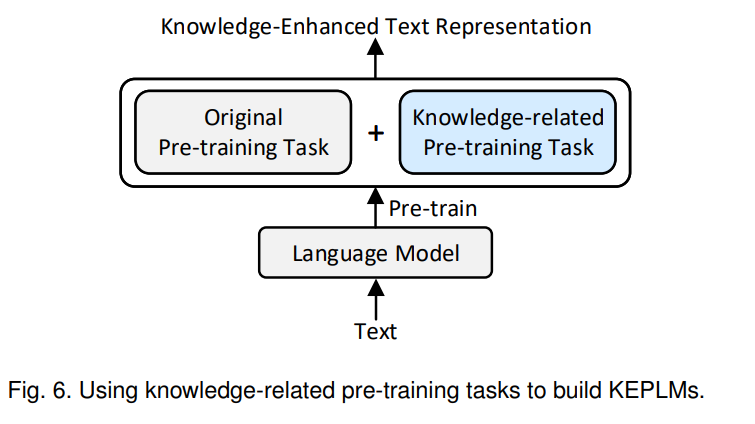
一些构建KEPLMs的方法通过添加知识相关的预训练任务隐式地纳入知识,如图6所示。
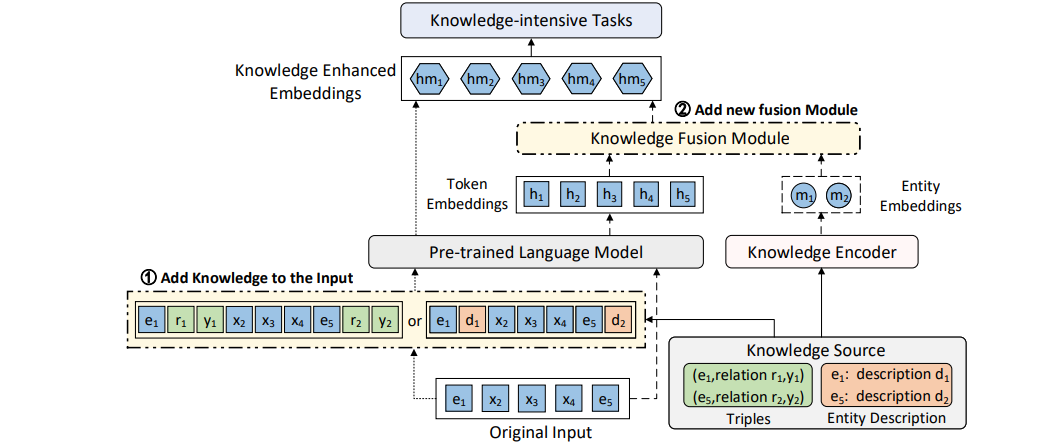
显性知识整合
PLMs 显式地合并外部知识主要有三种方式:修改模型输入、添加知识融合模块和利用外部内存。前两种方法将相关知识插入PLMs中,其形式为模型的额外输入或模型中的额外组件,如图7①和②所示。第三种方法使文本空间和知识空间保持独立,从而便于知识更新
参考文献
[1] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Proc. Int. Conf. Neural Inf. Process. Syst, vol. 26, 2013. [2] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proc. Conf. Empir. Methods Natural Lang. Process., 2014, pp. 1532–1543.


