
2025年国际计算机视觉与模式识别会议(CVPR2025)于6月11日至15日在美国田纳西州纳什维尔召开,CVPR是计算机视觉和人工智能领域最具学术影响力的顶级会议之一。据CVPR官网显示,CVPR 2025收到了创新高的13008份论文(比CVPR 2024增加了12.8%),共录用了2878篇论文,接收率为 22.1%。来自Apple、Meta、微软撰写《视觉基础模型》进展教程,值得关注!

我们在此介绍我们关于“视觉基础模型的最新进展”的 CVPR 教程提案。该主题近年来受到计算机视觉领域广泛关注。我们的教程将涵盖视觉基础模型设计与开发方面的最前沿方向,包括以下几个关键内容及其最新方法与原理: 1. 为多模态理解与生成而学习视觉基础模型; 1. 扩展测试时的计算能力,并推动基础模型的自我训练,使其在推理与感知任务中自我改进; 1. 基于视觉基础模型的物理与虚拟智能体,这些智能体能够在机器人系统与虚拟环境中自主执行动作。
地址:https://vlp-tutorial.github.io/
讲者:

一、多模态大模型的进展:从“看见”到“理解”与“行动”
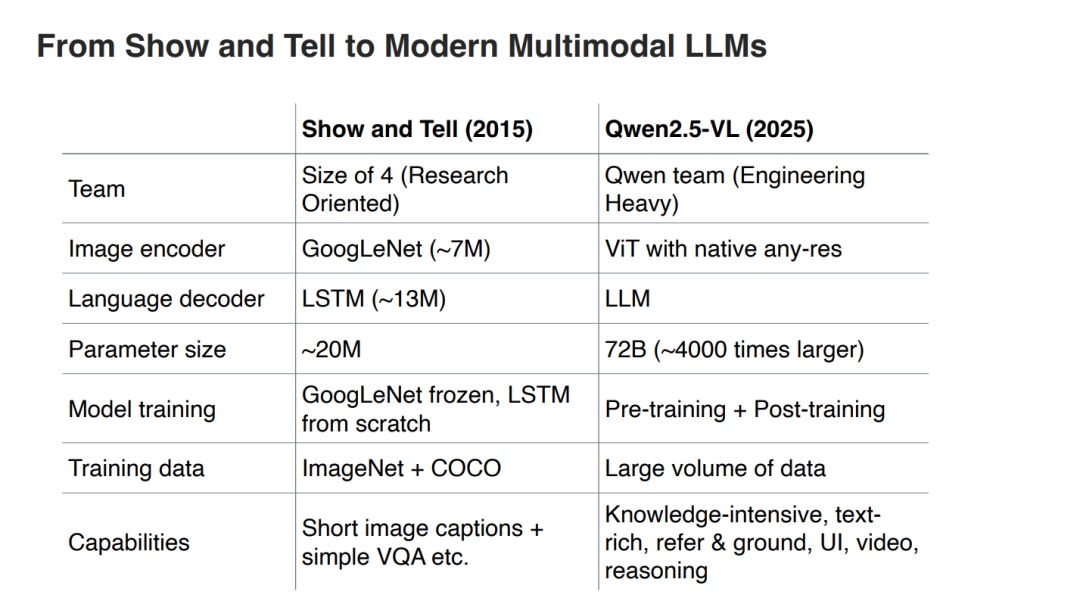
二、面向视觉中心的长时序任务的多模态推理
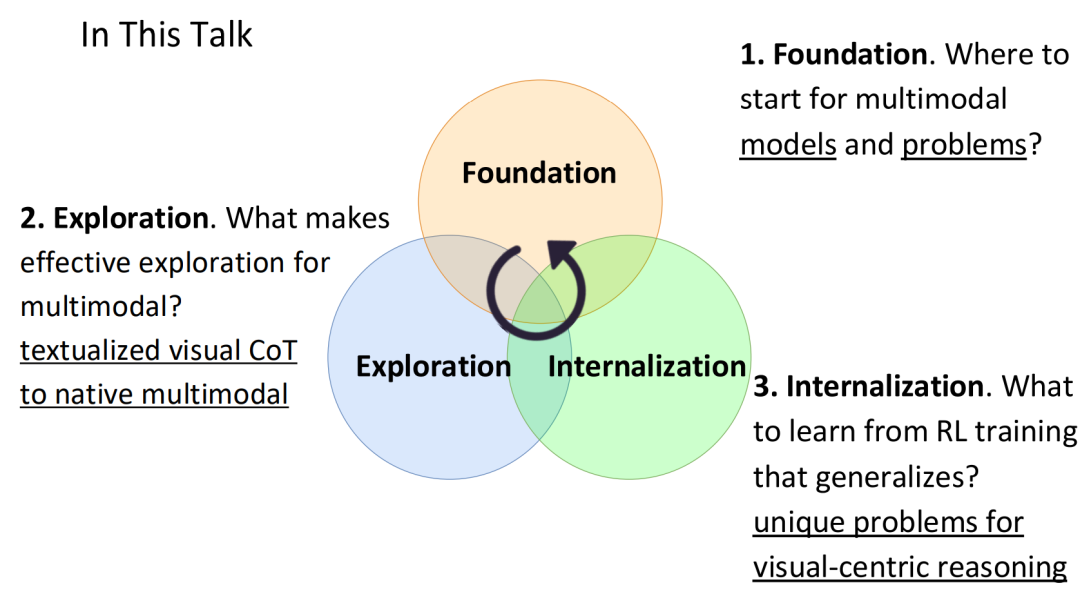
三、看、思考、行动:基于强化学习训练多模态智能体

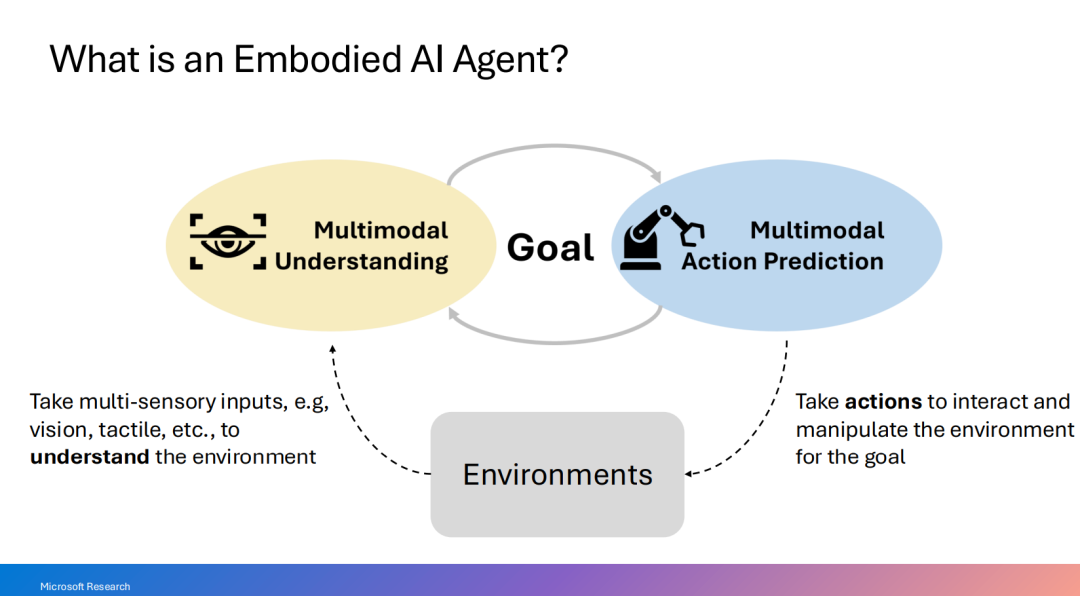
四、迈向具备“看、思考与行动”能力的多模态人工智能智能体
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文