AAAI 是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的 A 类国际学术会议,在人工智能领域享有较高的学术声誉。2024年,AAAI主办地为加拿大温哥华,录用文章2342篇,录用率为23.75%。

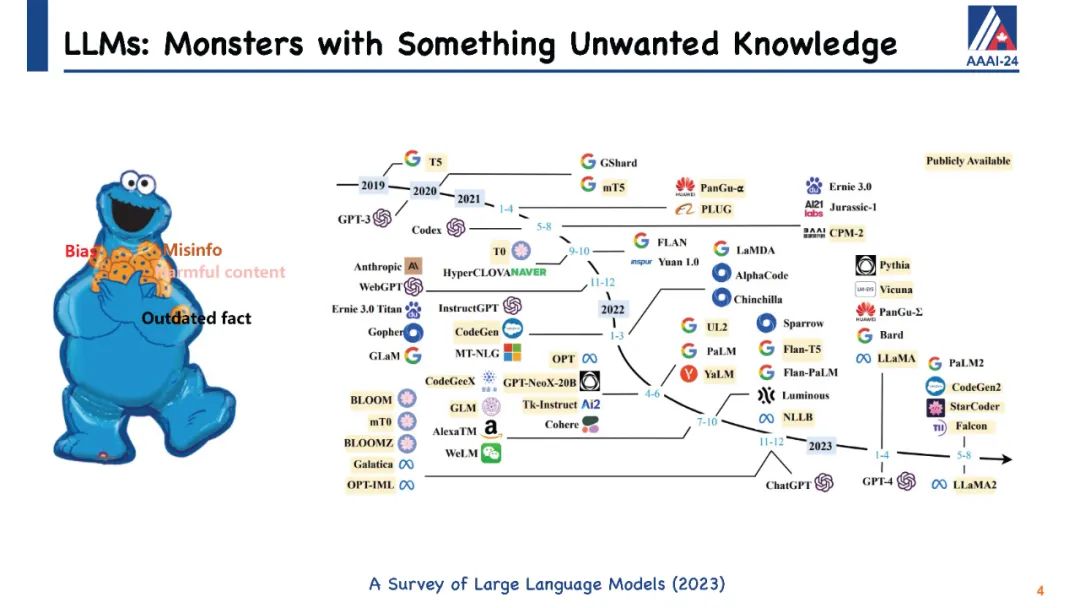
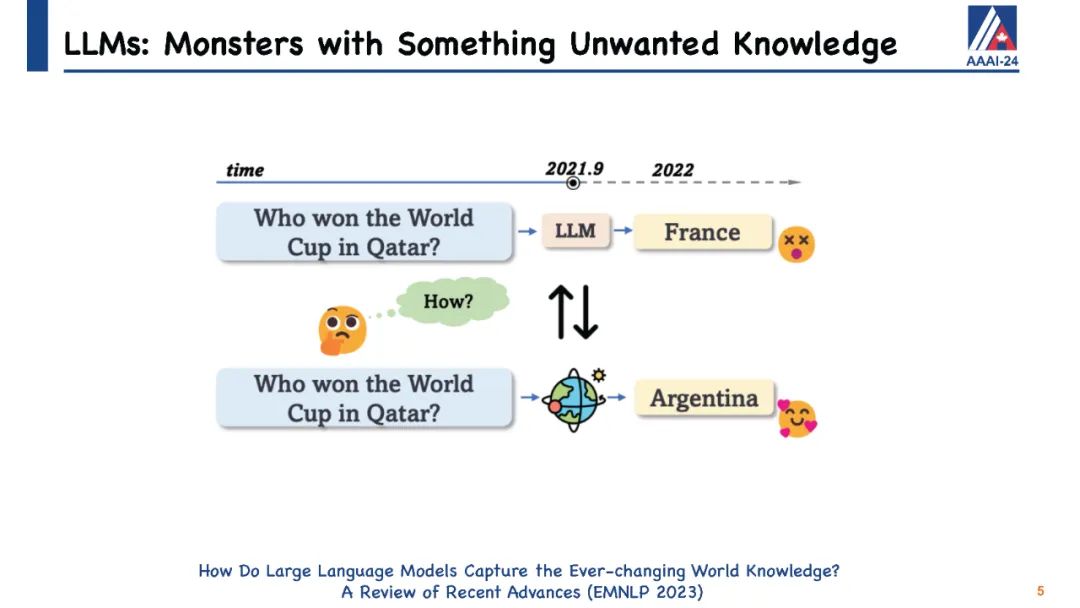
大型语言模型(LLMs)在生成类似人类的文本方面展现出巨大潜力,众多研究已经证明了这一点。尽管它们具有显著的能力,但像ChatGPT这样的LLMs有时会在保持事实准确性或逻辑一致性方面出错。它们可能会无意中生成有害或冒犯性的内容,并且对于它们训练阶段之后发生的事件一无所知。直观地说,手头上的挑战仍然是如何有效地更新这些LLMs或纠正它们的错误,而不需要进行完全的重新训练或持续的训练过程,这两者都可能非常耗费资源和时间。为此,已经提出了针对LLMs的知识编辑的概念,它提供了一种有效的方式来修改模型的行为,特别是在特定的兴趣领域内,而不会损害其对其他输入的性能。 我们将通过定义LLMs知识编辑中涉及的任务开始本教程,并介绍评估指标和基准数据集。随后,我们将提供各种知识编辑方法的概述。最初,我们的重点将放在保留LLMs参数的方法上。这些技术通过调整模型对某些实例的输出来实现,通过将辅助网络与原始未经触动的模型集成在一起。然后我们将转向修改LLMs参数的方法,这些方法旨在改变导致不希望输出的模型参数。在整个教程中,我们旨在分享从知识编辑研究的多元化社区中获得的洞见,并介绍开源工具EasyEdit。此外,我们将深入探讨与LLMs知识编辑相关的潜在问题以及机会,目标是向社区传授有价值的见解。所有教程幻灯片将在
https://github.com/zjunlp/KnowledgeEditingPapers上可用。
Ningyu Zhang是浙江大学的副教授主管,领导有关知识图谱和自然语言处理技术的团队。他指导构建了一个名为DeepKE(在Github上有2.3K+星)的信息提取工具包。他的研究兴趣包括知识图谱和自然语言处理。他在如Nature Machine Intelligence、Nature Communications、NeurIPS、ICLR、AAAI、IJCAI、ACL、ENNLP、NAACL等顶级国际学术会议上发表了许多论文。他曾担任ACL/EMNLP 2023的领域主席,ARR行动编辑,IJCAI 2023的高级程序委员会成员,以及NeurIPS、ICLR、ICML、AAAI的程序委员会成员。 Jiachen Gu将加入加州大学洛杉矶分校作为博士后研究员。他的研究兴趣在于对话系统和基于检索的LMs的机器学习。他于2022年6月从中国科学技术大学获得博士学位。他在如ACL、ENNLP、SIGIR、CIKM、IJCAI以及IEEE/ACM Transactions on Audio Speech and Language Processing等顶级国际学术会议和期刊上发表了许多论文。他曾担任ACL、EMNLP、NAACL、AAAI、IJCAI、TASLP、TOIS的PC或审稿人。他获得了ACL 2023最佳论文荣誉提名奖、ACL 2022 DialDoc工作坊最佳论文奖和CIPSC杰出博士论文提名奖。他在DSTC7-DSTC11中取得了顶尖排名。他就对话系统发表了多次演讲。 Yunzhi Yao是浙江大学计算机科学与技术学院的博士候选人。他的研究兴趣集中在编辑大型语言模型和知识增强的自然语言处理。他曾在微软亚洲研究院担任研究实习生,由黄绍焕指导,并在阿里巴巴集团担任研究实习生。他在ACL、EMNLP、NAACL、SIGIR等会议上发表了许多论文。他是EMNLP 2023论文“编辑大型语言模型:问题、方法和机会”的第一作者,也是知识编辑框架EasyEdit的开发者之一,该框架与本教程相关。 Zhen Bi是浙江大学软件工程学院的博士候选人。他的研究兴趣集中在知识图谱、利用大型语言模型进行推理和知识增强的自然语言处理。他在ICLR、ACL、EMNLP等会议上发表了许多论文。此外,他也是知识编辑框架EasyEdit的开发者之一,该框架与本教程相关。 Shumin Deng是新加坡国立大学计算机科学系计算学院的研究员。她在浙江大学计算机科学与技术学院获得了博士学位。她的研究兴趣集中在自然语言处理、知识图谱、信息提取、神经符号推理和LLM推理。她获得了2022年浙江省杰出毕业生、2020年阿里巴巴集团学术合作杰出实习生奖。她是ACL的成员,也是中国信息处理学会青年工作委员会的成员。她曾担任EMNLP 2022信息提取研究会议主席,CoNLL 2023出版主席。她一直是许多高质量期刊的期刊审稿人,如TPAMI、TASLP、TALLIP、WWWJ、ESWA、KBS等;并担任NeurIPS、ICLR、ACL、EMNLP、EACL、AACL、WWW、AAAI、IJCAI、CIKM等的程序委员会成员。她构建了一个十亿规模的开放商业知识图谱(OpenBG),并发布了一个排行榜,吸引了数千个团队和研究人员。