【联邦学习】IJCAI主席杨强:联邦学习的最新发展及应用
“同态加密”的突破使联邦学习成为解决“隐私保护+小数据”双重挑战的利器。
AI 科技评论按:7月12日-7月14日,2019第四届全球人工智能与机器人峰会(CCF-GAIR 2019)于深圳正式召开。峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办,深圳市人工智能与机器人研究院协办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流博览盛会,旨在打造国内人工智能领域极具实力的跨界交流合作平台。
7 月 13 日,香港科技大学讲席教授,微众银行首席AI官,IJCAI理事会主席杨强为 CCF-GAIR 2019「AI 金融专场」做了题为「联邦学习的最新发展及应用」的大会报告,以下为杨强教授所做的大会报告全文。

大家好,今天很荣幸和大家分享联邦学习的最新发展与应用。

我们首先来看下微众银行这两年所做的努力和成就。
微众银行的目标是建立起强大的AI能力,助力小微企业成长。要做到这点,先不妨把金融各个环节分解开来,用以发现其中可以用人工智能革新的场景:
比如可以用人工智能来帮助做业务咨询(企业画像),企业在申请贷款和账号时,进行身份核实,这其中包括法人身份核实和个人申请账户身份核实,以及资料的审核等;此外AI可以赋能的地方还包括操作放款,贷前、贷终、贷后,整个流程都可实现自动化。
具体的产品案例有以下几种:
一是语音客服机器人。这类产品我们听过很多,比如智能音箱等。现在语音客服机器人在垂直领域已经做得非常细分化,目前,微众银行98%的客户问题由智能客服机器人提供7×24小时的解答,而且用户满意度颇高。为什么能做到这点?因为里面融合了很多人工智能的最新技术。
大家都知道,对话系统中有一个很难的问题,是如何进行多轮问答。
以音箱的语音交互为例,我们知道一般情况下,每执行一个口令任务,都需要用户说一次唤醒词,然后它才会回答你。而到了下一个问句,你又要说同样的唤醒词,再问它问题。而多轮问答是只要叫醒一次就可以进行多次问答。
这个技术实现过程里有很多难题:比如要理解每句话的意图和整个对话线程的意图。此外还需要进行情感分析,比如在一些场景中,需要分辨出客户的急躁或不满,也需分析出客户的兴趣点,机器只有区分开这些细微的信号,才能实现优质的多轮对话效果。除此之外,还要进行多线程的分析,比如用户说的上一句和下一句话意图不同,前言不搭后语,机器需把这个逻辑分解出来。
总的来说,这个领域还有非常多的工作要做。我们的看法是,对话系统最好的落地场景是:拥有上亿用户的垂直领域。
二是风控对话机器人。对话机器人还可以做风控,比如在和客户对话的过程中发现一些蛛丝马迹,辨别对方是否是在进行欺诈。就像我们面试一个人或者和借款人交流时,随时随地都要提高警惕,防止对方欺诈。
我们再举一个车险汇报的例子,发生车祸了,到底谁是责任人?可能汇报人的回答会出现前后不一致,机器人通过对这些细节的识别来实现测谎。
三是质检机器人。金融领域很特别的是,每次在客服与客户对话过程中和对话之后都要对对话质量进行检测。过去每个对话都是录音,成百上千的录音,人工没有办法一条条过,所以我们现在用自研的语音识别加意图识别手段,来发现客服对话质量不好的地方,进行自动质检。
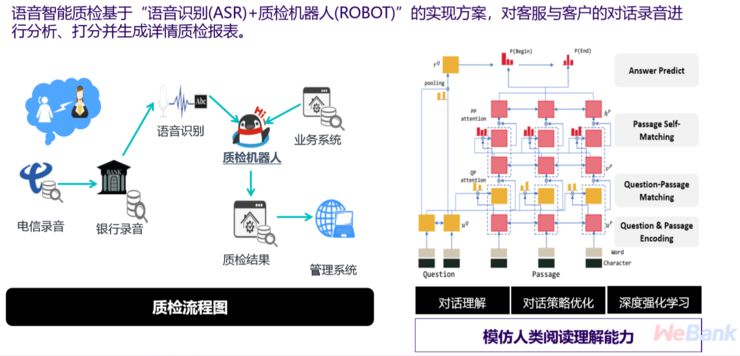
(微众AI:质检机器人)
上图是质检流程,我们在注意力机制下用深度学习来帮助做对话理解。质检可以帮助发现用户贷款时,客服需要做的改进,比方有些不应该拿贷款去投放给非常有风险的人或场景,有的时候,客服也要保持微笑的态度,如果质检机器人发现机器人客服态度不好,也会自动预警。
以上这些都是微众银行在服务类机器人方面所做的工作。
不难看出人工智能在小微企业、贷款、互联网银行等上都有很多应用。不过这些应用同样也遇到很多挑战,以至于我们有必要发明一些新的算法。主要有哪些挑战呢?概括来讲有三点:
第一,“对抗学习”的挑战。即针对人工智能应用的作假,比如人脸识别就可以做假,针对面部进行合成。如何应对这种“对抗学习”的挑战,这是金融场景下人工智能安全领域的重大题目。
第二,小数据的挑战。没有好的模型就无法做到好的自动化,好的模型往往需要好的大数据,但往往高质量、有标签的数据都是小数据。
假设收集数据3年,是不是就可以形成大数据?不是这样的,因为数据都在变化,每个阶段的数据和上一个阶段的数据有不同的分布,也许特征也会有不同。实时标注这些数据想形成好的训练数据又需要花费很多人力。
不仅金融场景,在法律场景也是这样,医疗场景更是如此。每个医院的数据集都是有限的,如果不能把这些数据打通,每个数据集就只能做简单的模型,也不能达到人类医生所要求的高质量的疾病识别。
然而,现在把数据合并变得越来越难,我们看到Facebook的股价此前出现过一天内断崖式下跌,主要是因为当时有新闻报道它和美国一个公司之间的数据共通影响了美国大选。
这类事情不仅引起资本市场的振动,法律界也开始有很大的动作,去年5月份欧洲首先提出非常严格的数据隐私保护法GDPR。GDPR对于人工智能机器的使用、数据的使用和数据确权,都提出非常严格的要求,以至于Google被多次罚款,每次金额都在几千万欧元左右。
因为GDPR其中一则条文就是数据使用不能偏离用户签的协议,也许用户的大数据分析,可以用作提高产品使用体验,但是如果公司拿这些数据训练对话系统,就违反了协议。如果公司要拿这些数据做另外的事,甚至拿这些数据和别人交换,前提必须是一定要获得用户的同意。
另外还有一些严格的要求,包括可遗忘权,就是说用户有一天不希望自己的数据用在你的模型里了,那他就有权告诉公司,公司有责任把该用户的数据从模型里拿出来。这种要求不仅在欧洲,在美国加州也实行了非常严格的类似的数据保护法。
中国对数据隐私和保护也进行了非常细致的研究,从2009年到2019年有一系列动作,而且越来越严格,经过长期的讨论和民众的交互,可能在今年年底到明年年初会有一系列正式的法律出台。
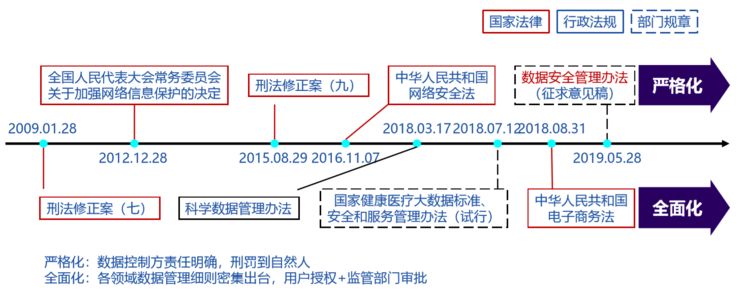
(国内数据监管法律体系研究)
因此我们会面对这样的困境:一方面我们的数据大部分是小数据,另一方面数据的合并会违反隐私法规。除了法规限制之外,利益驱使下公司们也不愿意把数据拿出来和其他公司交换。在这种现象下,很多人觉得很失望,觉得很灰暗,觉得人工智能的冬天也许又一次到来了。
但我们不这么看,我们觉得挑战反而是一个机会,是一个机遇,这个机会使得我们有必要发明一种新的技术,在严格遵从法规的前提下还能够把这些数据聚合起来建模。既保护隐私不把数据进行交换,又能利用大数据建立模型,这种看似矛盾的事怎么才能达到呢?这就是联邦学习(Federated Learning)的优势所在。
先来看一个通俗的类比:我们每个人的大脑里都有数据,当两个人在一起做作业或者一起写书的时候,我们并没有把两个脑袋物理性合在一起,而是两个人用语言交流。所以我们写书的时候,一个人写一部分,通过语言的交流最后把合作的文章或者书写出来。
我们交流的是参数,在交流参数的过程中有没有办法保护我们大脑里的隐私呢?是有办法的,这个办法是让不同的机构互相之间传递加密后的参数,以建立共享的模型,数据可以不出本地,这就是联邦学习的精髓。
“联邦学习”由Google在2016年首先提出,不过更多是2C的应用。当时Google特别关心它的安卓系统,2016年就在想能不能把下一代的安卓系统做成可以满足GDPR保护用户隐私。
安卓手机上有各种各样的模型,比如打字的时候会给你建议下一个字,照相的时候会给你提示一个标注、归类,这些都是模型驱动,这样的模型是需要不断更新的。
过去更新最简单的办法是把每个手机里的数据定时上传到云端,在云端建立大模型,因为每个人的数据是有限的,在几千万个手机的数据都上传的情况下就有了大数据,就可以做大模型,做好后再把这个模型下传到每个手机上,这样就完成了一次手机端的更新。
但现在这种做法是违规的,因为手机端用户传数据上去,Server就看到了用户的数据。
这时候,联邦学习的优势就出来了。从简单定义来讲,联邦学习是在本地把本地数据建一个模型,再把这个模型的关键参数加密,这种数据加密传到云端也没有办法解密,因为他得到的是一个加密数据包,云端把几千万的包用一个算法加以聚合,来更新现有的模型,然后再把更新后的模型下传。重要的是,整个过程中Server云端不知道每个包里装的内容。
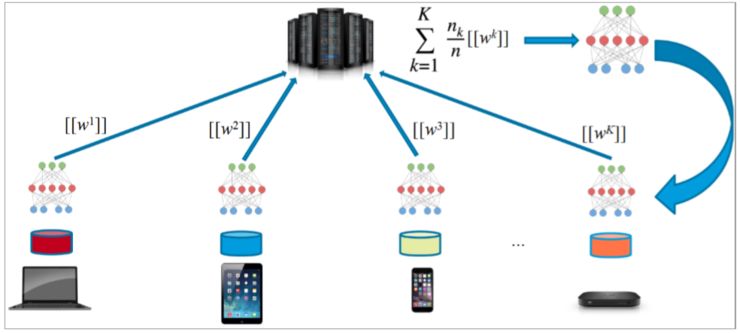
(基于同态加密的Model Averaging)
这听起来好像很难的样子,之前确实很难,但最近发生了一件很伟大的事,即加密算法可以隔着加密层去进行运算,这种加密方法叫“同态加密”,这种运算效率最近取得了重大提升,所以联邦学习就变成可以解决隐私,同时又可以解决小数据、数据孤岛问题的利器。不过需要注意的是这只是2C的例子,是云端面对大用户群的例子。
这个技术比较新,翻译成中文是我们首先翻译成“联邦学习”,大家可能听到其他的翻译,比如“联合学习、联盟学习、协作学习”,我们决定采取联邦学习的译法,是因为听起来比较入耳,一次就能记住,所以希望以后大家都叫联邦学习。
现在科学进入新领域,一定要涉及到多个学科的融合才能解决社会问题,联邦学习就是很好的例子。
首先我们要了解加密和解密,保护隐私的安全方法。计算机领域已经有很多研究,从70年代开始,包括我们熟悉的姚期智教授,他获得图灵奖的研究方向是“姚氏混淆电路”,另外还有差分隐私等。
这么多加密方法它们是做什么的呢?就是下面的公式:

它可以把多项式的加密,分解成每项加密的多项式,A+B的加密,变成A的加密加B的加密,这是非常伟大的贡献。因为这样就使得我们可以拿一个算法,在外面把算法给全部加密,加密的一层可以渗透到里面的每个单元。能做到这一点就能改变现有的机器学习的教科书,把任何算法变成加密的算法。
目前这个事没有做完,欢迎在座的博士生、硕士生赶快买一本机器学习的书,尝试把一个一个算法变成加密的算法。
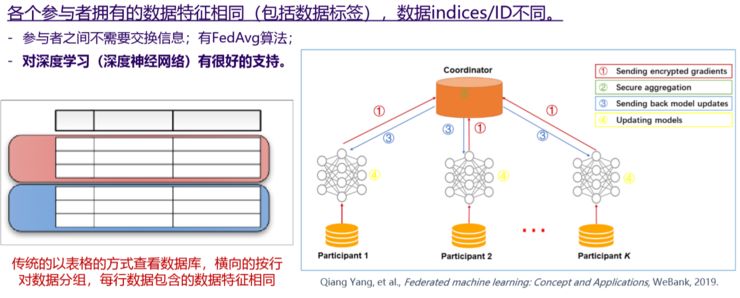
(横向联邦学习 Horizontal Federated Learning)
我刚才讲的是“横向联邦学习”,横向联邦学习是每行过来都可以看作一个用户的数据。按照用户来分,可以看作一、二、三个手机,它叫横向学习。还有一个原因是它们的纵向都是特征,比如手机型号、手机使用时间、电池以及人的位置等,这些都是特征。他们的特征都是一样的,样本都是不一样的,这是横向联邦学习。
主要做法是首先把信用评级得到,然后在加密状态下做聚合,这种聚合里面不是简单的加,而是很复杂的加,然后把征信模型再分发下来。
我们很期待5G的到来,加快速率,5G对联邦学习是大好事。现在还没有5G,所以大家想各种各样网络的设计,在底层网络的设计,甚至有人在设计联邦学习芯片,加速网络的设计和沟通,这些都是研究者们关心的研究方向。
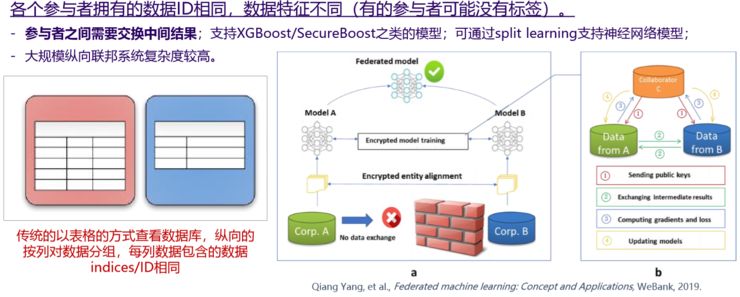
(纵向联邦学习 Vertical Federated Learning)
纵向联邦加密,大家的Feature不一样,一个机构红色、一个机构蓝色,大家可以想象两个医院,一个病人在红色医院做一些检测,在蓝色的医院做另外一些检测,当我们知道这两个医院有同样一群病人,他们不愿意直接交换数据的情况下,有没有办法联合建模?
它们中间有一个部门墙,我们可以在两边各自建一个深度学习模型,建模的时候关键的一步是梯度下降,梯度下降我们需要知道几个参数,上一轮参数、Loss(gradients)来搭配下一个模型的weight参数。这个过程中我们需要得到全部模型的参数级,这时候需要进行交换,交换的时候可以通过同态加密的算法,也可以通过secure multiparty computation,这里面有一系列的算法,两边交换加密参数,对方进行更新,再次交换参数,一直到系统覆盖。
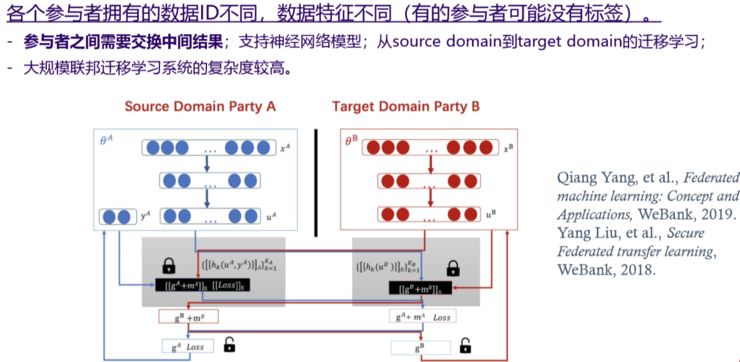
(联邦迁移学习 Federated Transfer Learning)
我刚才讲的,它们或者在特征上一样,或者在特征上不一样,但是他们的用户有些是有交集的,当用户和特征没有交集时,我们退一步想,我们可以把他们所在的空间进行降维或者升维,把他们带到另外的空间去。
在另外的空间可以发现他们的子空间是有交互的,这些子空间的交互就可以进行迁移学习。虽然他们没有直接的特征和用户的重合,我们还是可以找到共性进行迁移学习,这种叫联邦迁移学习。
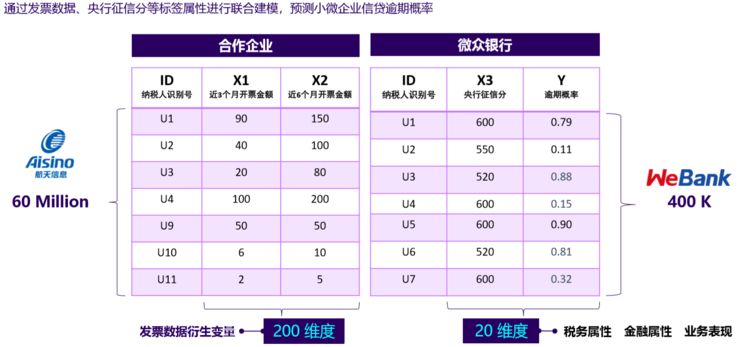
(基于联邦学习的企业风控模型)
我们来看一个微众银行和合作伙伴公司的案例。微众的特点是有很多用户Y,我们把数据集分为X和Y,X是用户的特征和行为,Y是最后的结论,我们在银行的结论是信用逾期是否发生,这是逾期概率,合作的伙伴企业可能是互联网企业或者是卖车的或者卖保险,不一定有结论数据Y,但是它有很多行为信息X。
现在这两个领域对于同一批用户如果要建模,属于纵向联邦学习,建立纵向联邦学习的应用,最后就取得了很好的效果,AUC指标大为上升,不良率大为下降。
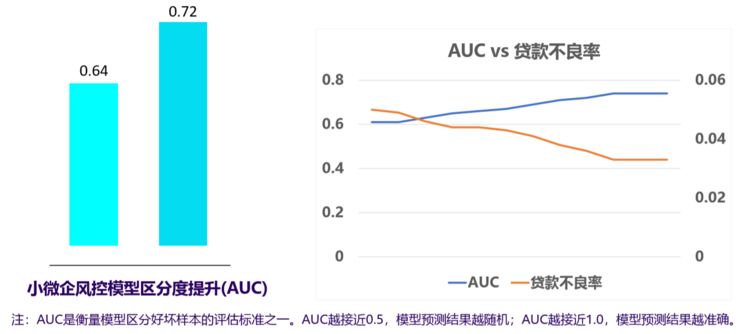
(联邦学习解决方案效果)
这个例子表明两个企业在数据不物理交换的前提下,确实有可能通过联邦学习各自获益,获益的效果是因为两边的数据确实不一样,是互补的,在有联邦学习和没有联邦学习的中间,联邦学习起到了几个作用:
商务上,如果我们给合作公司的老板解释,用联邦学习可以保护隐私,就更容易促成两个企业的合作,这是商务上做BD同事非常高兴,因为BD的成功率大为提高。
技术上,确实可以保证合法的进行联邦学习,并且是有效果的。
再来看第二个案例,这个案例完全不是为了从商业角度,而是城市管理。我们知道有很多工地,工地上有很多摄像头是用来监测工地安全,比如我们想知道工人有没有戴安全帽,有没有火灾、有没有人抽烟,以前是派人看,之后派摄像头在镜头前看。
那现在我们能不能用自动的方法、模型的方法来检测这些事情的发生和这事情有多严重?在香港如果有工人不戴帽子,工地会被勒令停产三天,这对工期非常不利,以至于老板们非常紧张。之前老板们的做法是把摄像头前面拿纸蒙上,不让政府看到。政府发现了这一点,就规定只要蒙上就是违法,就停工三天。
因此现在有来找我说有没有AI的办法来做?不过AI的做法有不同的摄像头,有政府的、有本地的,还有外包公司的,这些摄像头照出来的人脸我们都不希望对方看到,这是隐私问题。现在用联邦学习做这个事已经做通了,而且已经在几个工地上使用了。
第三个案例是语音识别,语音识别的数据很多,又有不同的细分场景,比如保险客服领域的语音识别、质量检测的语音识别等,这些数据可能来自不同的数据收集方,他们也不愿意把数据给对方,因为数据本身是资源。现在我们用联邦学习把它们联起来建立共享的ASR模型,现在也取得很好的成就。
联邦学习像一个操作系统,你自己玩是不行的,它的特点是多方合作,只有多方都认可,才有机会做起来,因此我们非常重视建立一个联邦学习的生态。
为此我们在学术界和工业界进行了大量的宣传,希望大家今后都来参加。8月12日,IJCAI会议将在澳门举行一次开放的FML,是一整天的研讨会,有很多业界的人将会做演讲。
同时我们做了很多开源项目,不只是我们,全世界各地都在做联邦学习的开源项目,希望大家积极参与进来。我们也FATE系统捐献给了Linux Foundation。
同时我们也正在推进建立国际标准IEEE P3652.1,8月11日在澳门召开第三次会议,现在进度很快,参与公司也很多。同时我们也在国内建立标准,工信部刚刚推出了第一个联邦学习的团体标准,下一步要推行国家标准。
我们推标准的原因是,联邦学习要像操作系统一样,是机构和机构之间的交流语言,机构合作首先得有语言(字典),得大家都说这个语言才能做起来,所以我们非常热衷建立这样的标准,并把它推行开来。也希望大家按照这样的方式参与到IEEE的标准委员会来。谢谢大家。

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




