【教程】语音识别中的End-to-End模型教程(附178页PDF全文下载)
【导读】Interspeech是由国际语音通信协会ISCA(International Speech Communication Association)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会,该会议每年举办一次,每次都会吸引全球语音信号领域以及人工智能领域知名学者、企业以及研发人员参加。本期内容为大家整理了google研究人员Rohit Prabhavalkar在大会上的端到端语音识别模型教程,希望对大家有所帮助。
介绍:
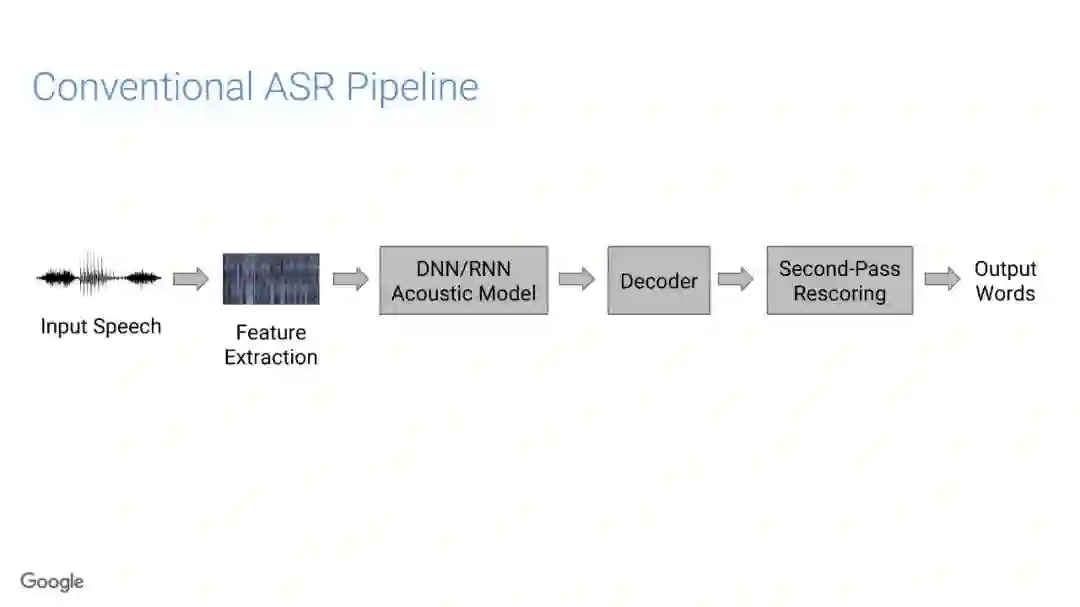
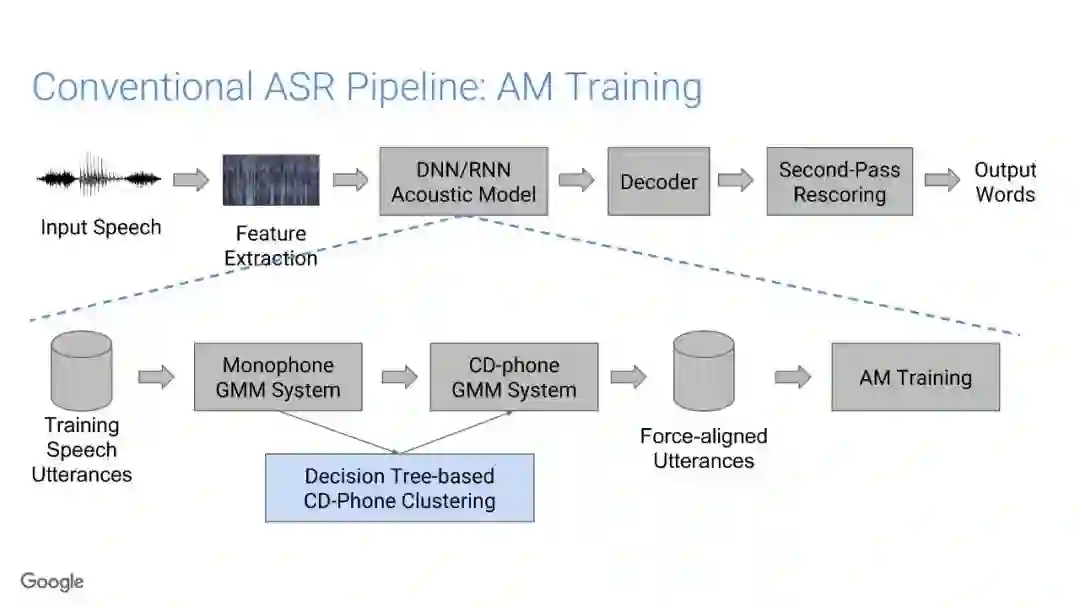
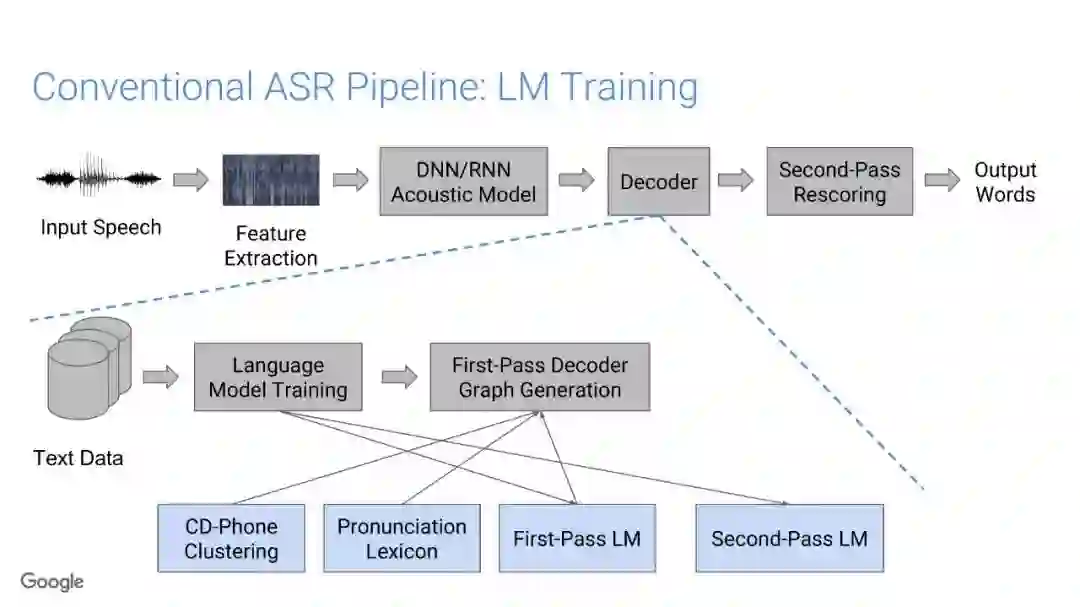
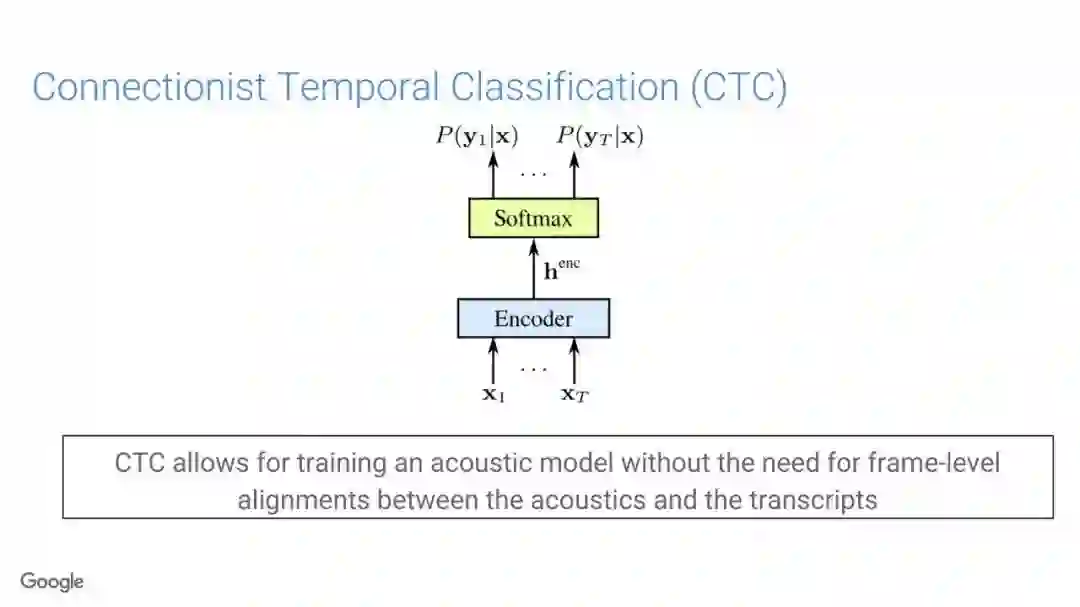
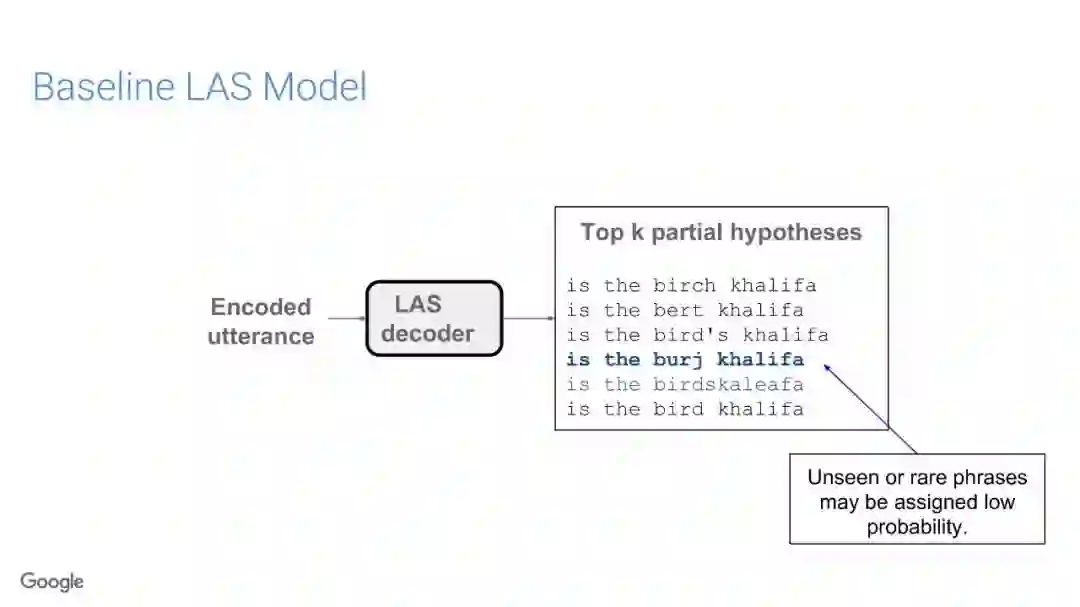
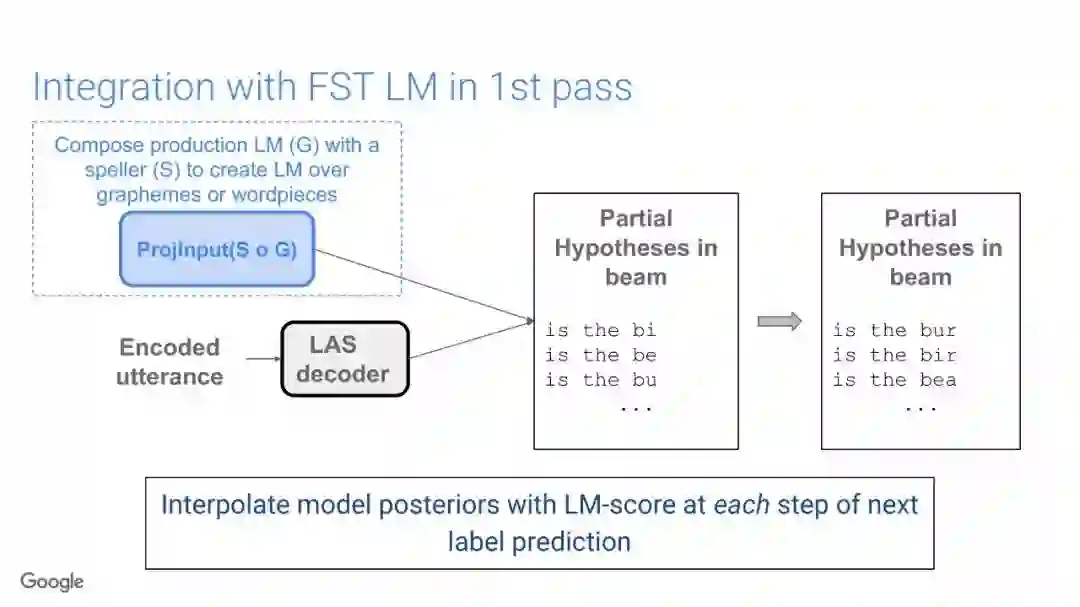
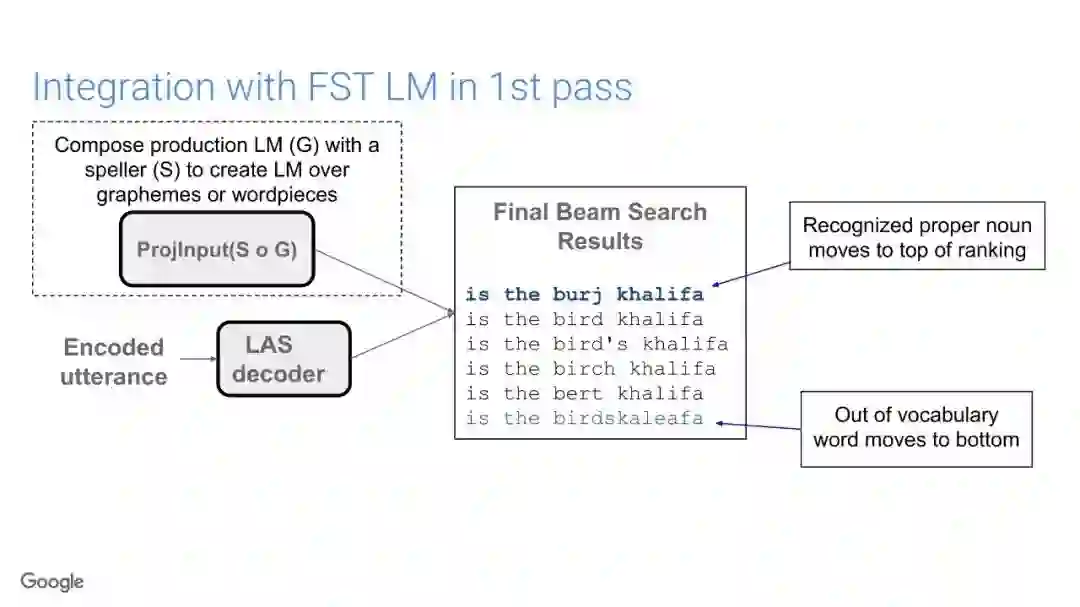
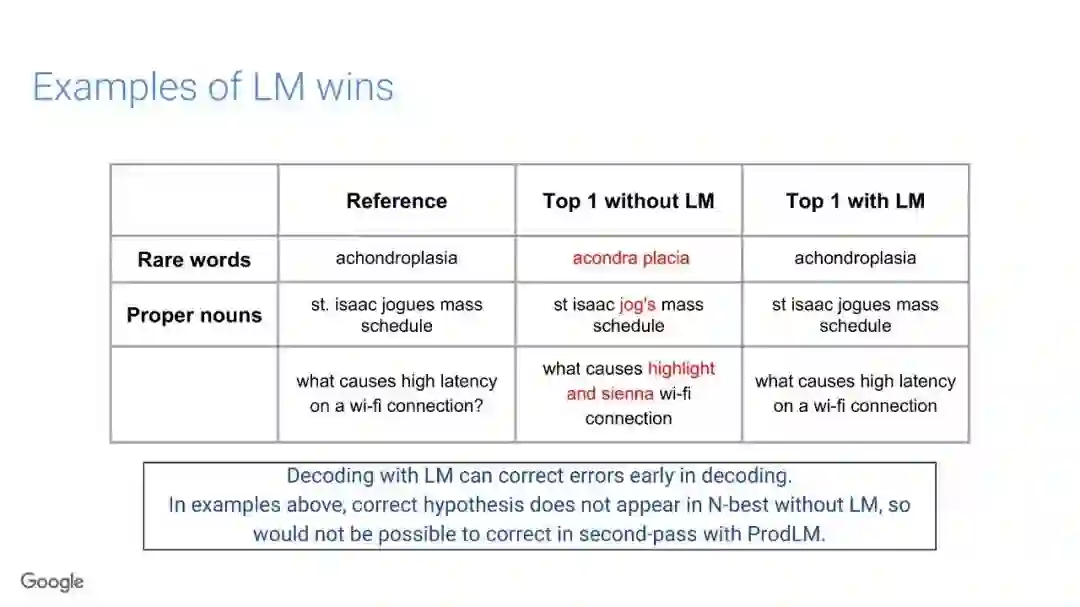
传统的语音识别系统是由一组独立的构件组成,即声学模型(AM)、语音模型(PM)、语言模型(LM)。其中AM输入以声学特征为主(通常是上下文相关的音素),以预测subword单元的分布;PM一般情况是人工设计的词典集合,它将声学模型产生的subword单元序列映射到单词上;最终,通过LM构件对各种词的概率进行计算,得到文本序列。
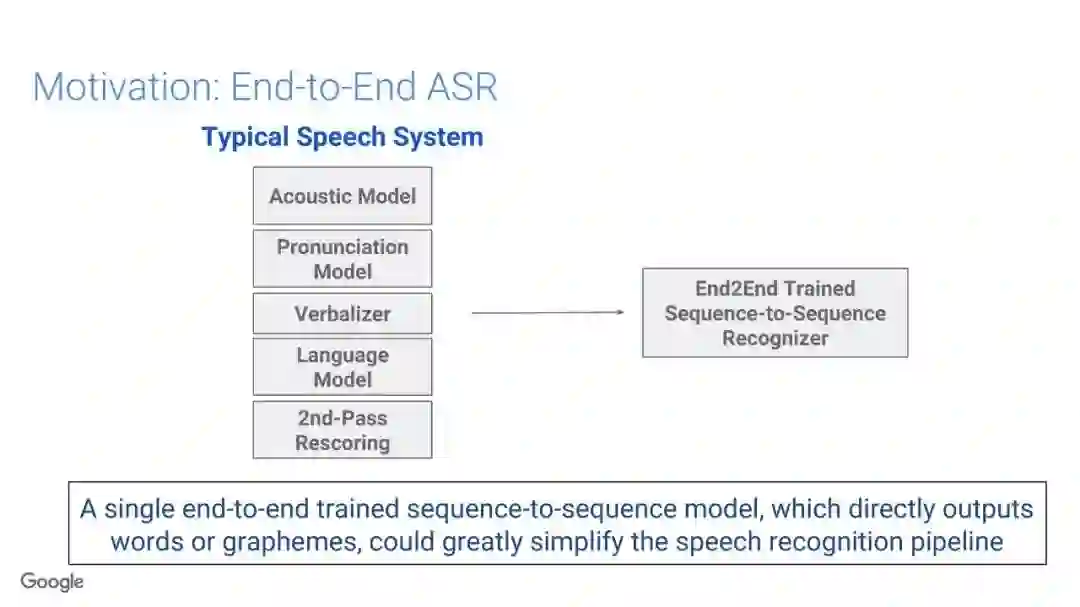
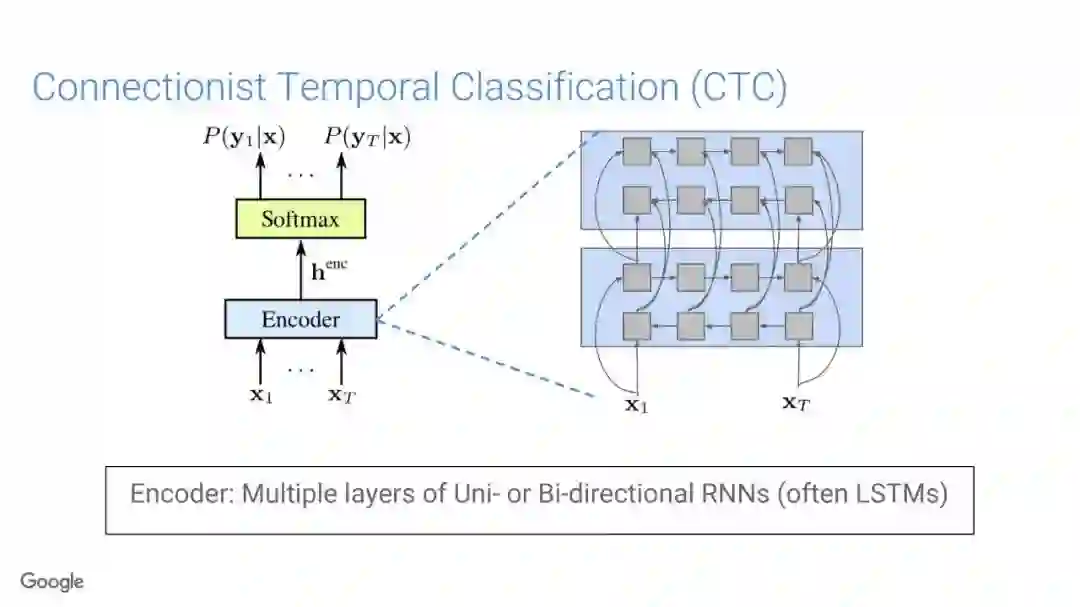
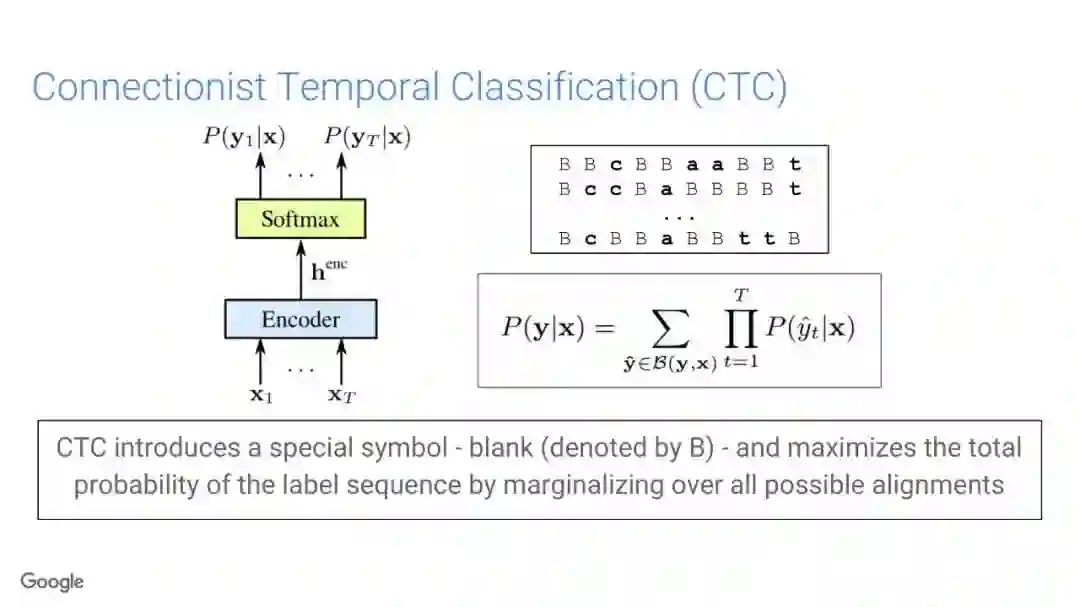
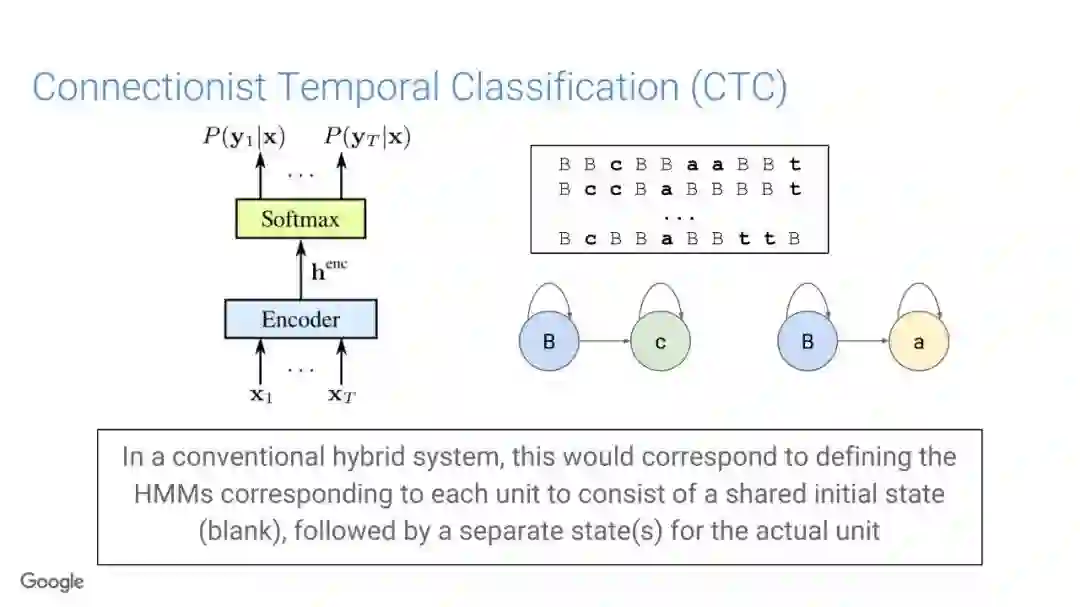
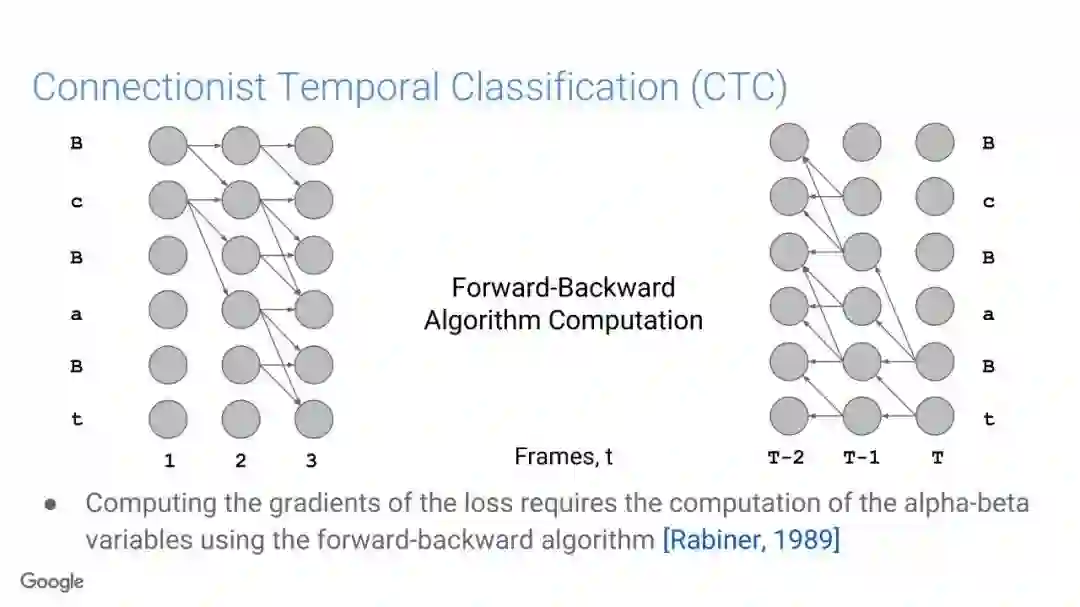
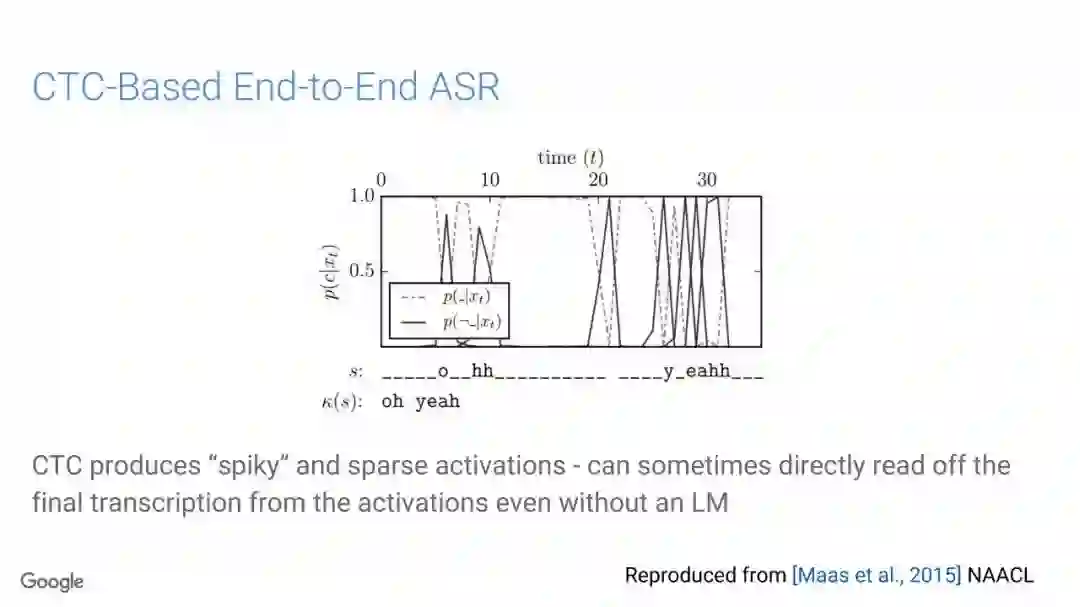
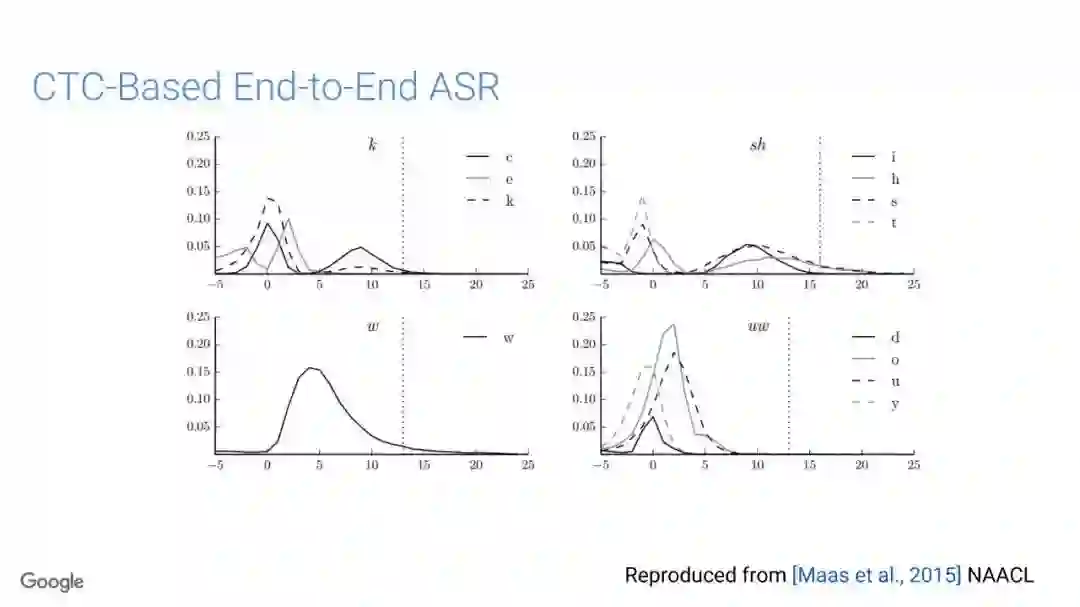
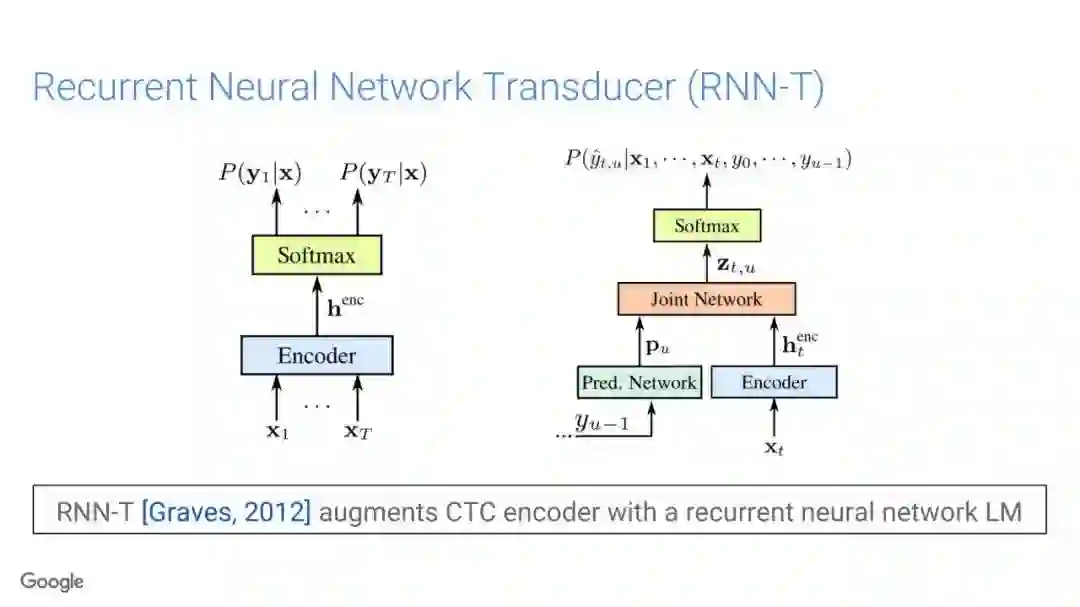
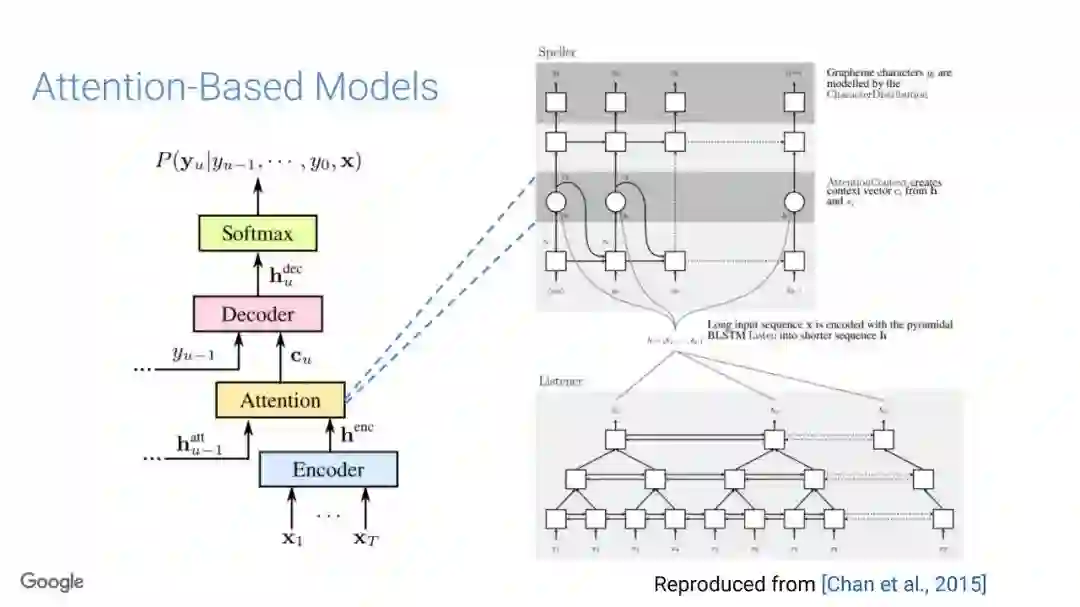
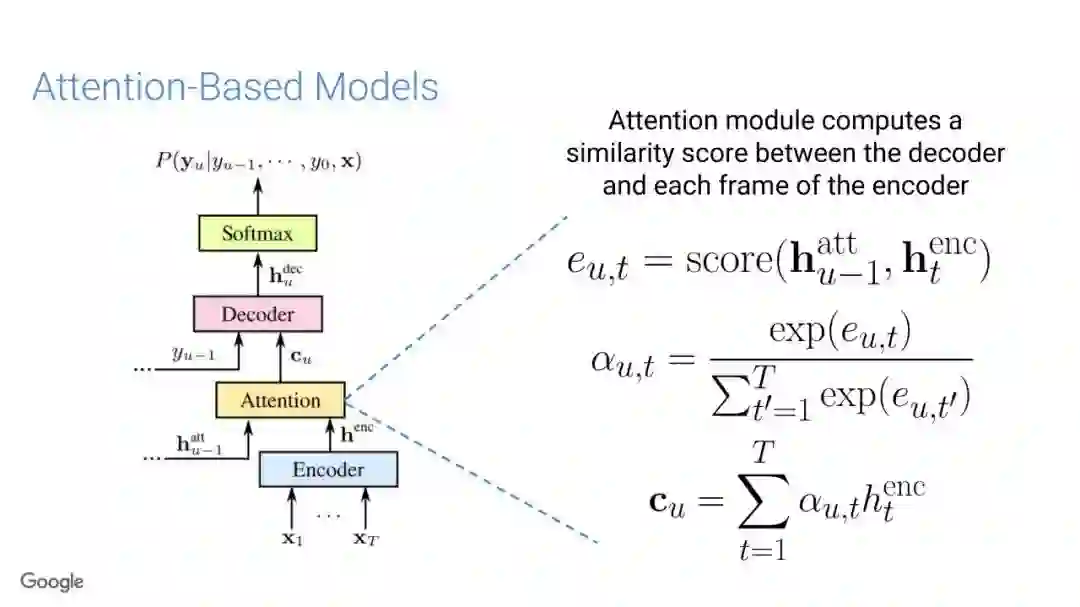
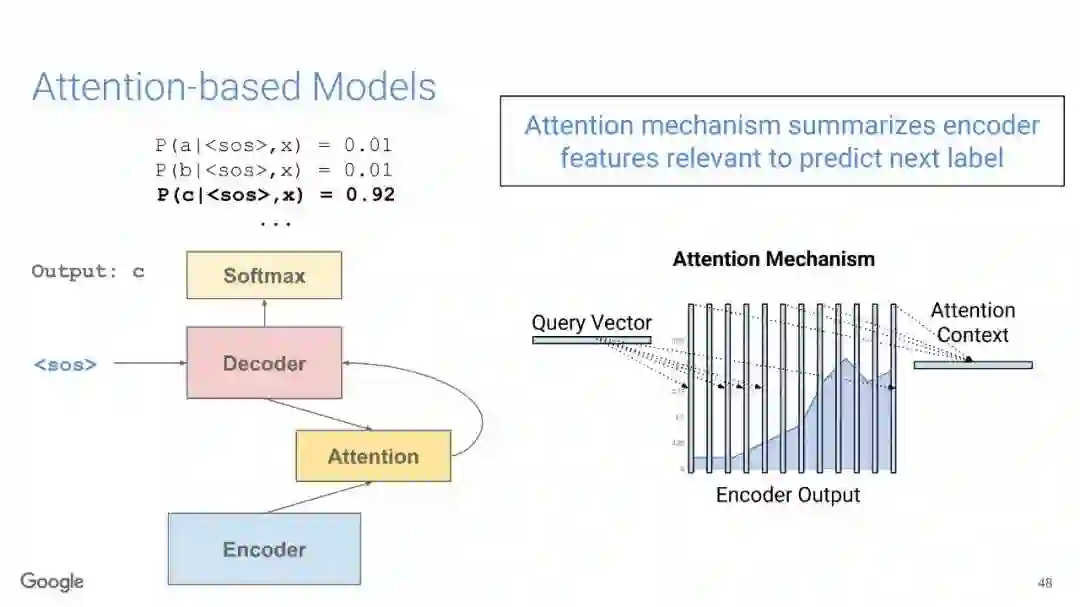
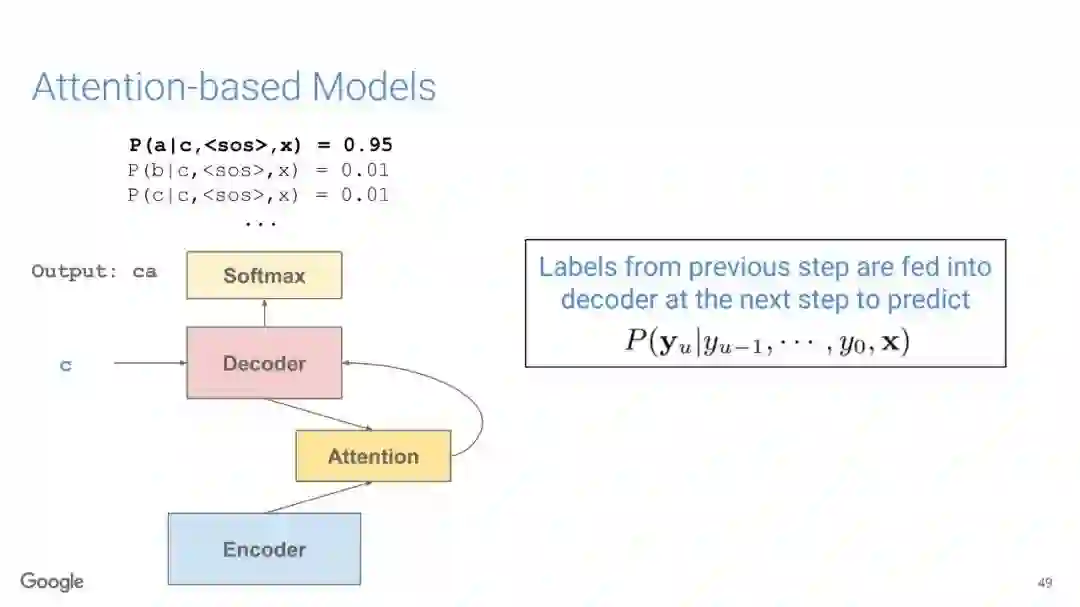
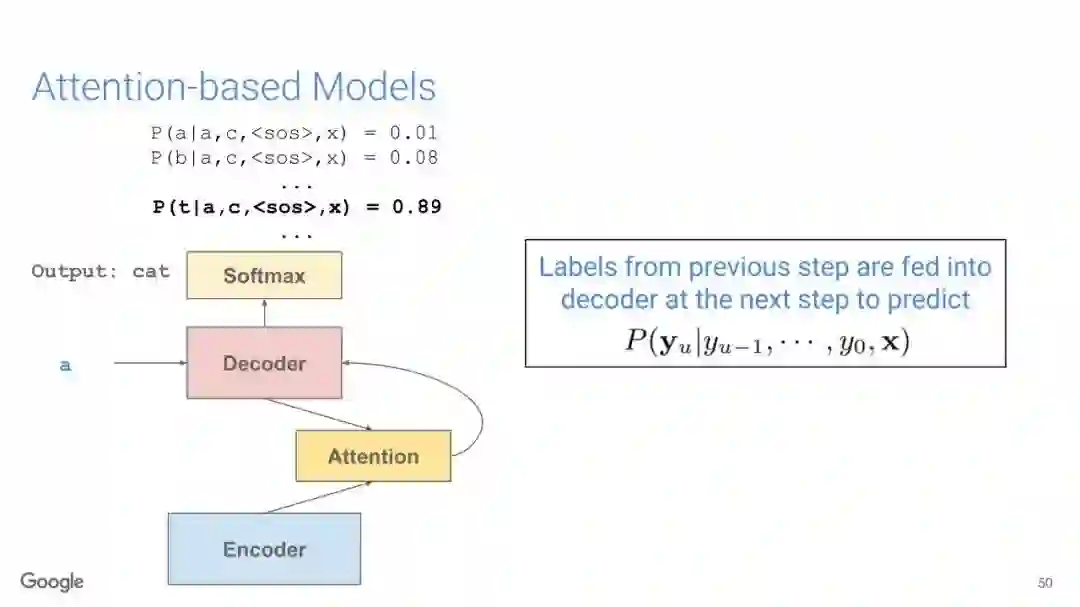
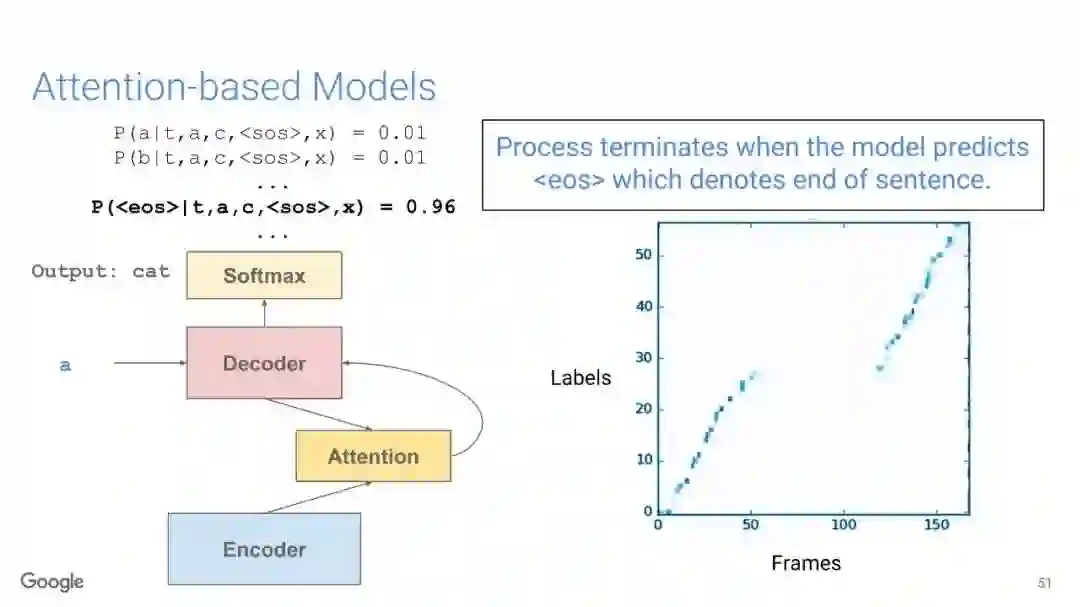
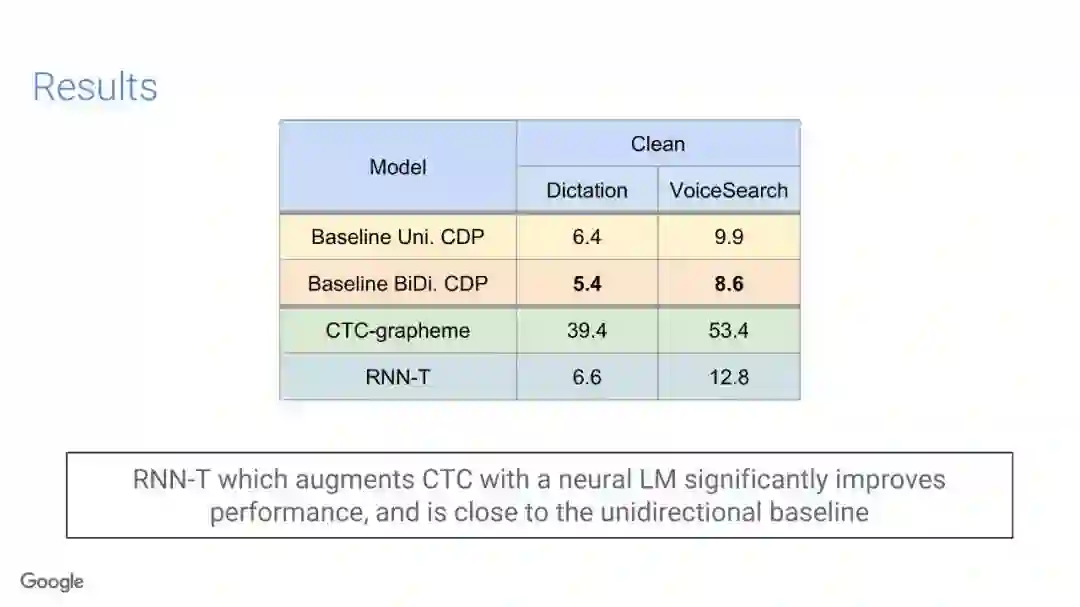
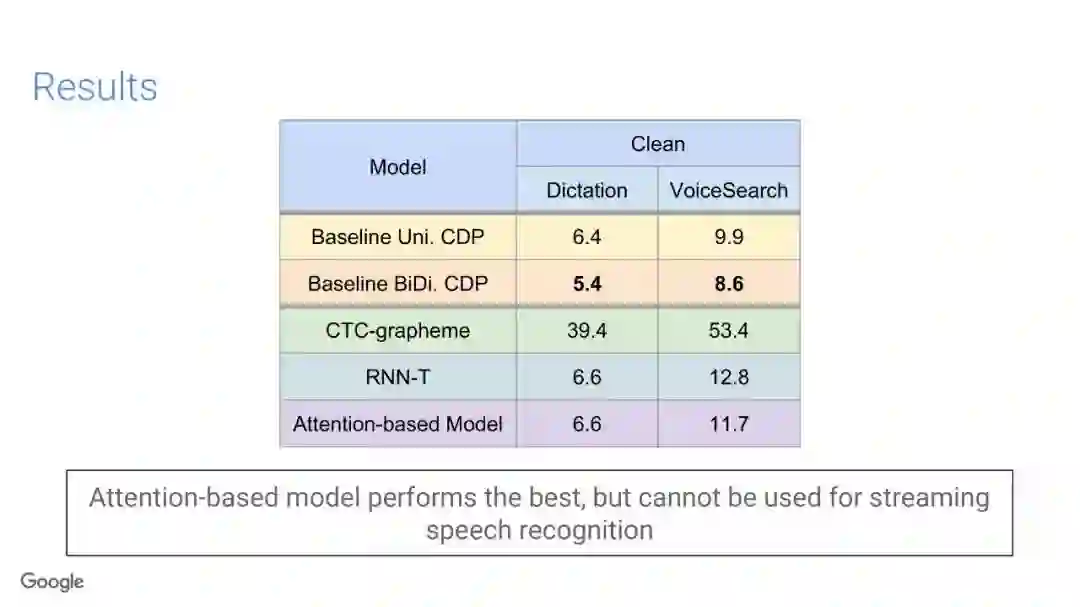
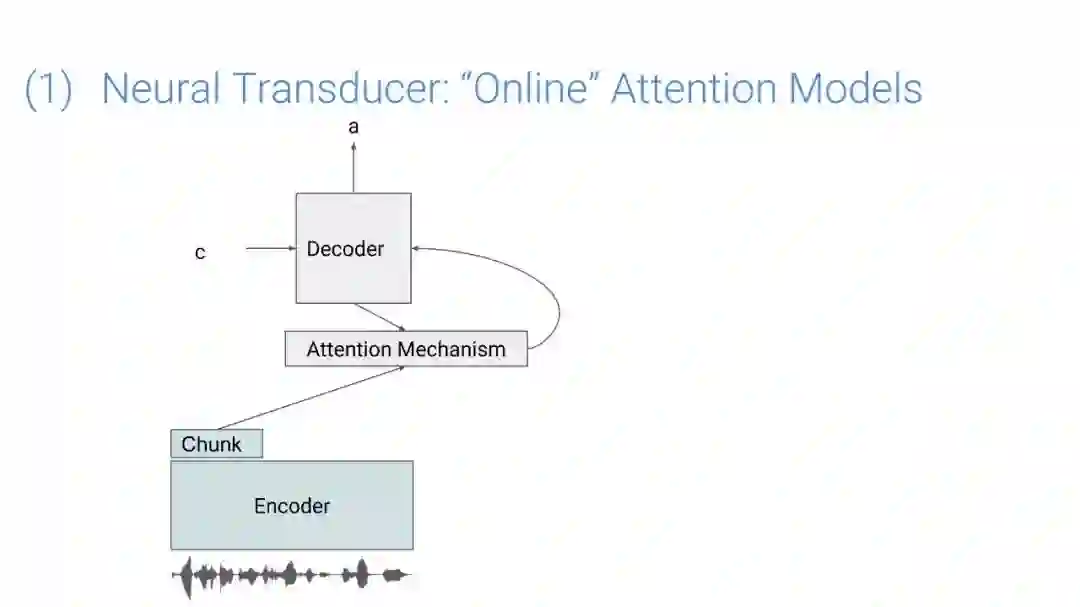
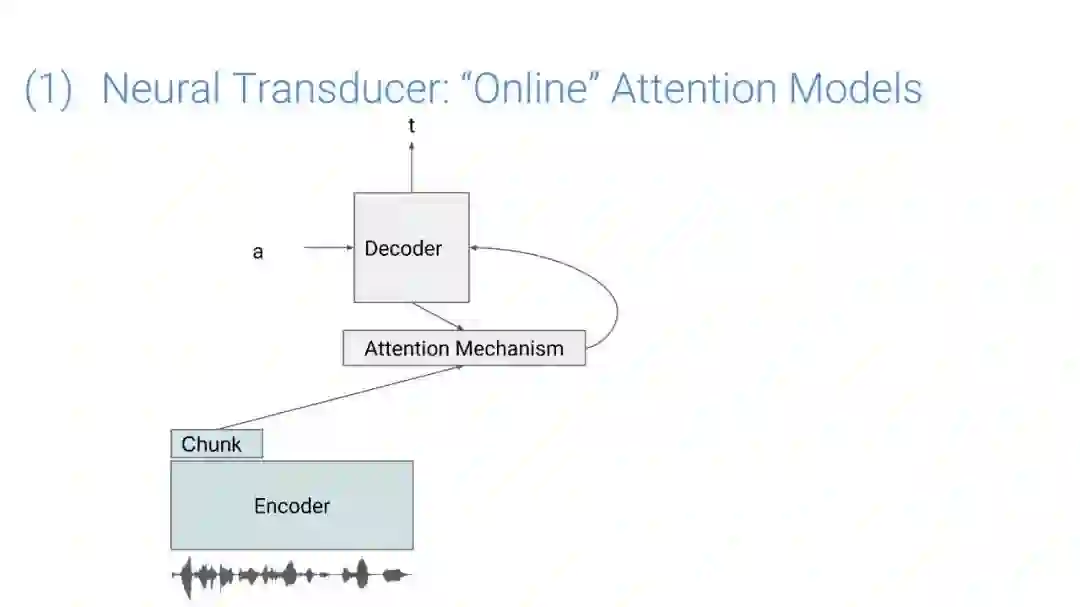
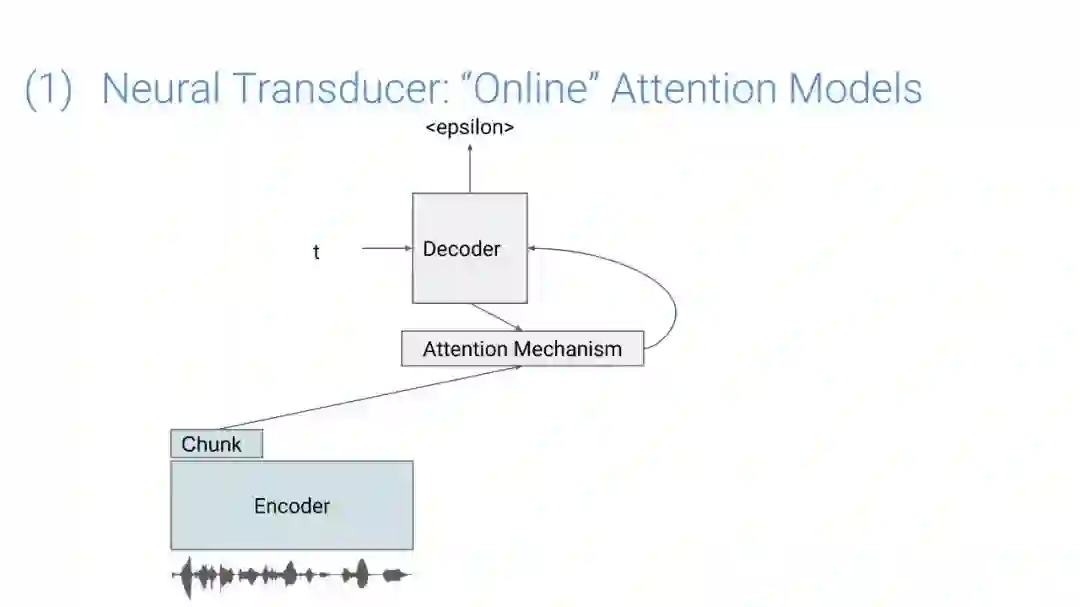
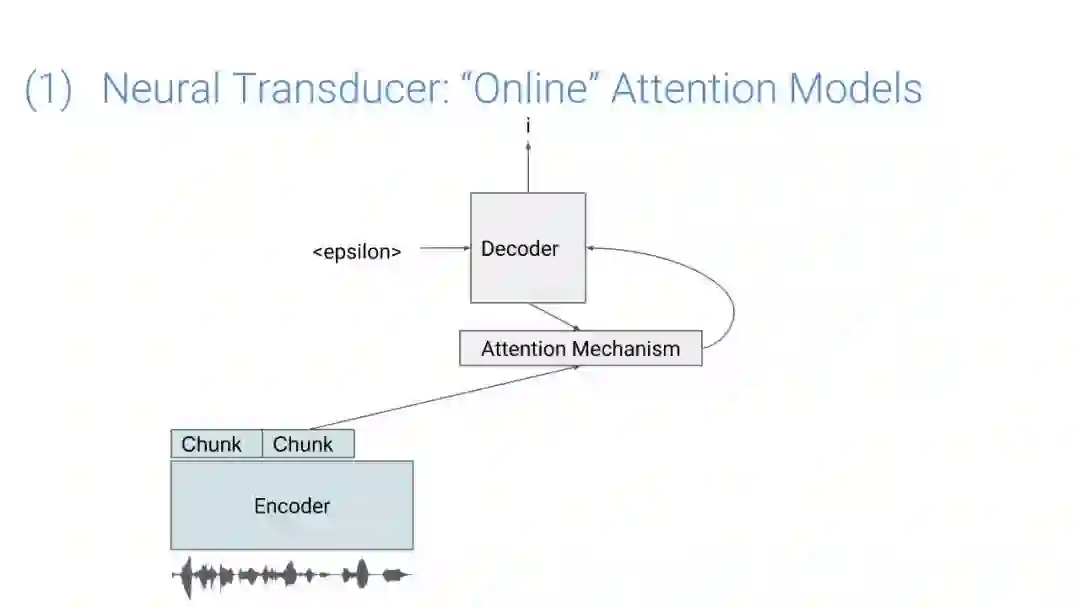
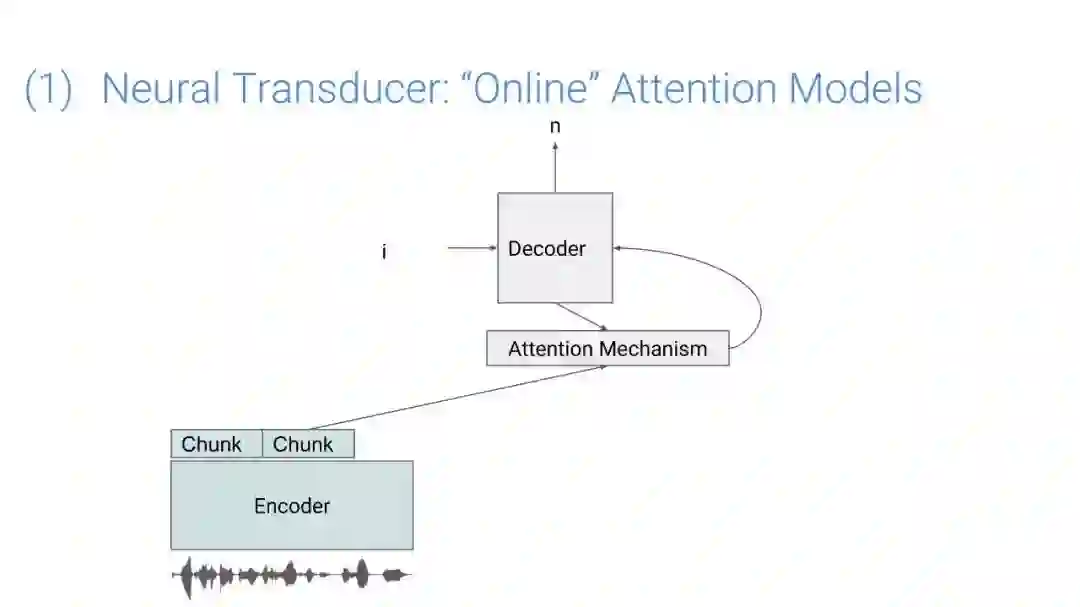
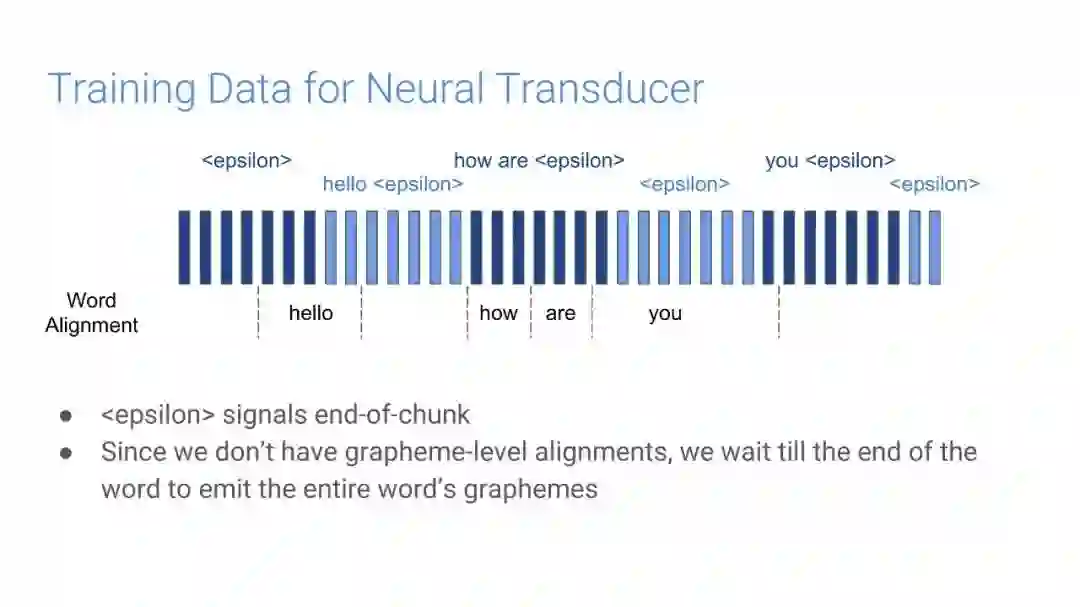
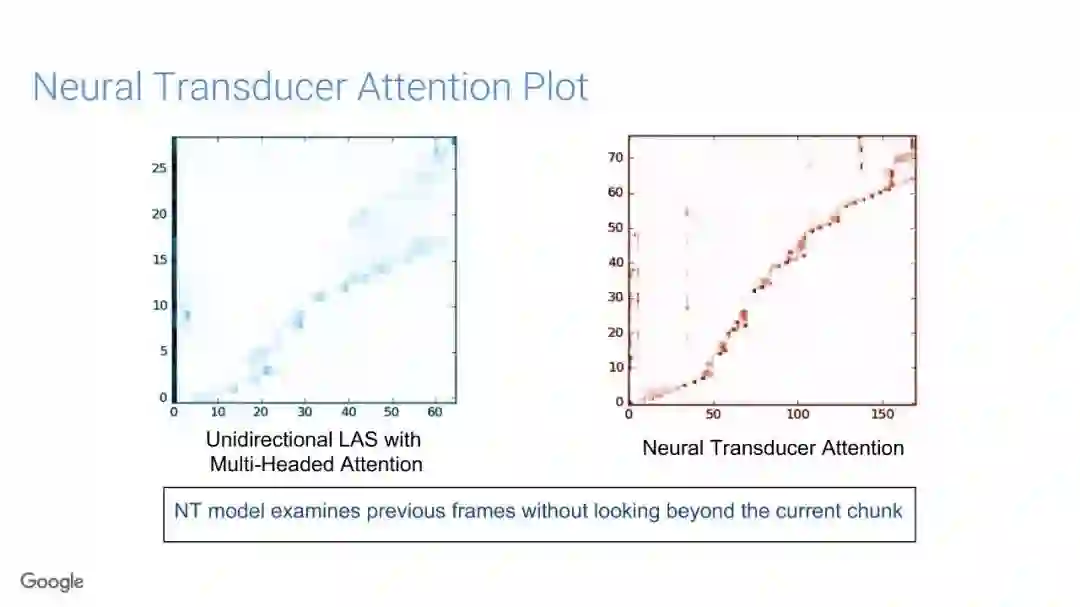
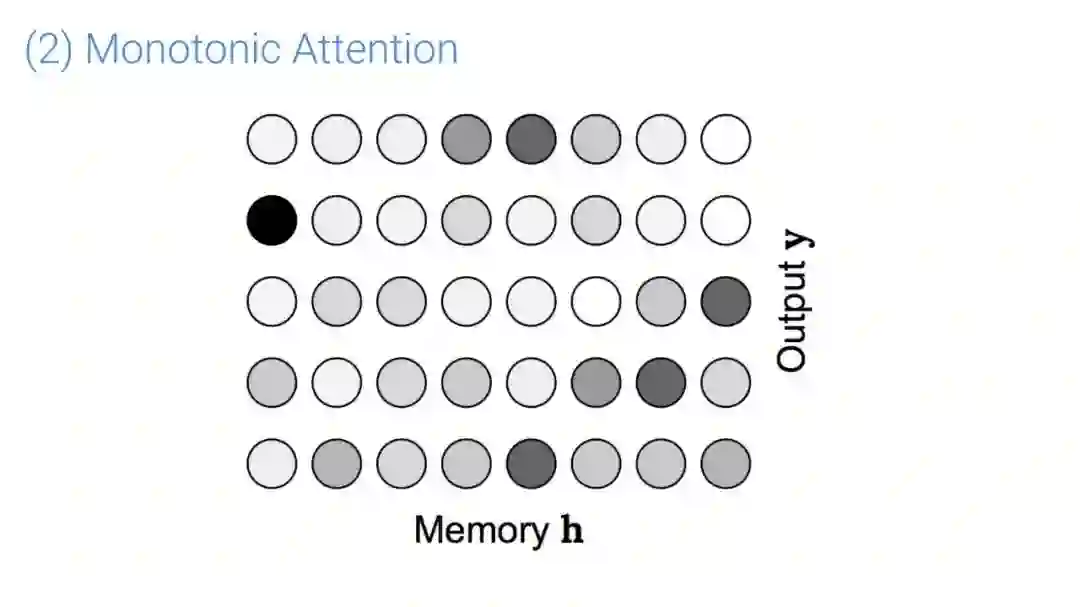
在传统的自动语音识别系统中,这些构件是在不同数据集上独立训练的,并且有一些独立的假设以方便处理。而在过去的几年里,人们对开发端到端的语音识别系统越来越感兴趣,这些系统试图在单个系统中完成多个构件的工作。例如基于attention的模型、循环神经传感器、循环神经校准器、目标词时序分类等。这些模型的共同特点在于,它们组成在一个单一的神经网络上,当接收一段语音信息后,直接输出一组图形或文字的概率分布。随着研究的逐渐深入,这种端到端的模型可以超过传统自动语音识别系统的性能。
在本教程中,我们将详细介绍自动语音识别中的端到端建模方案,从这些系统的历史发展开始,同时分析这些方法的共性和区别;进而,我们将讨论一些最近的创新工作,这些创新极大地改进了端到端模型的性能,使它们能够超过传统的自动语音识别系统的性能;然后,本教程将描述这项研究的一些令人兴奋的应用,以及一些可能的研究方向;最终,我们将讨论端到端模型现在存在的问题,以及将来所面临的挑战。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“EESR” 就可以获取全文报告 PDF下载链接~
附PDF全文:














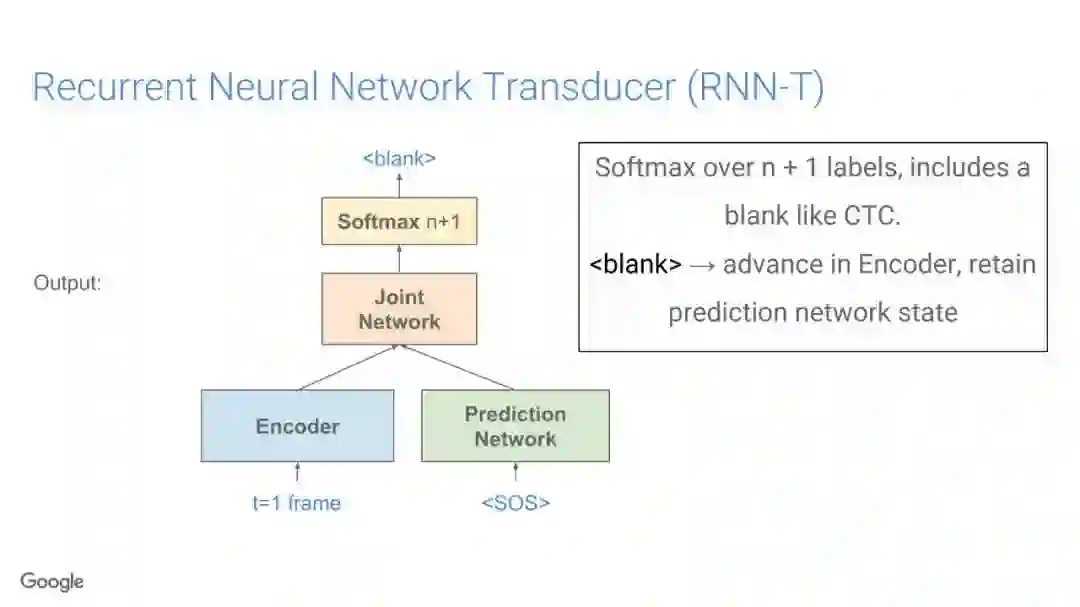
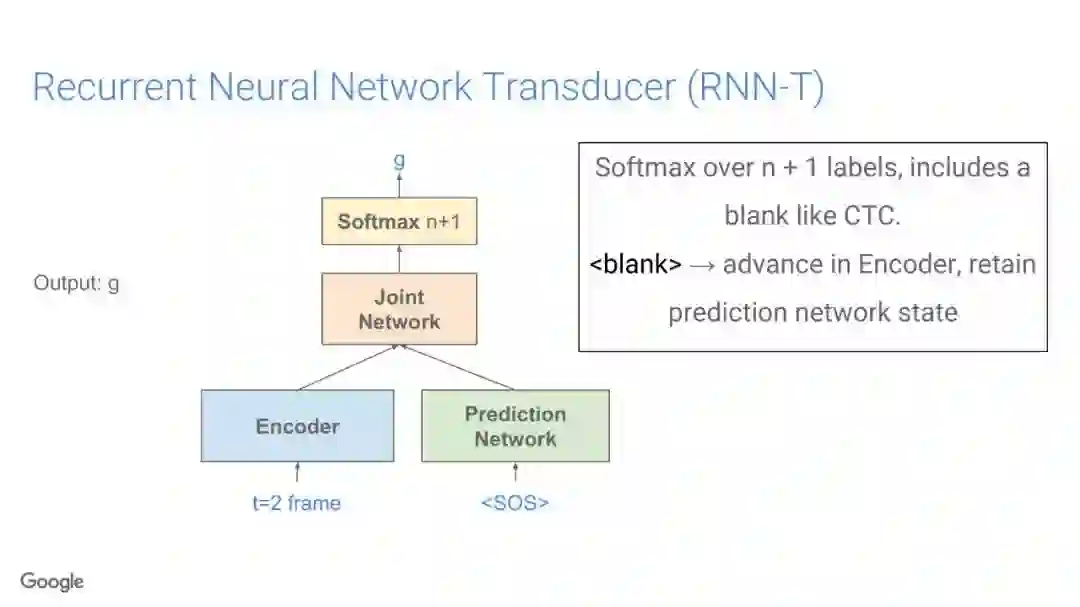
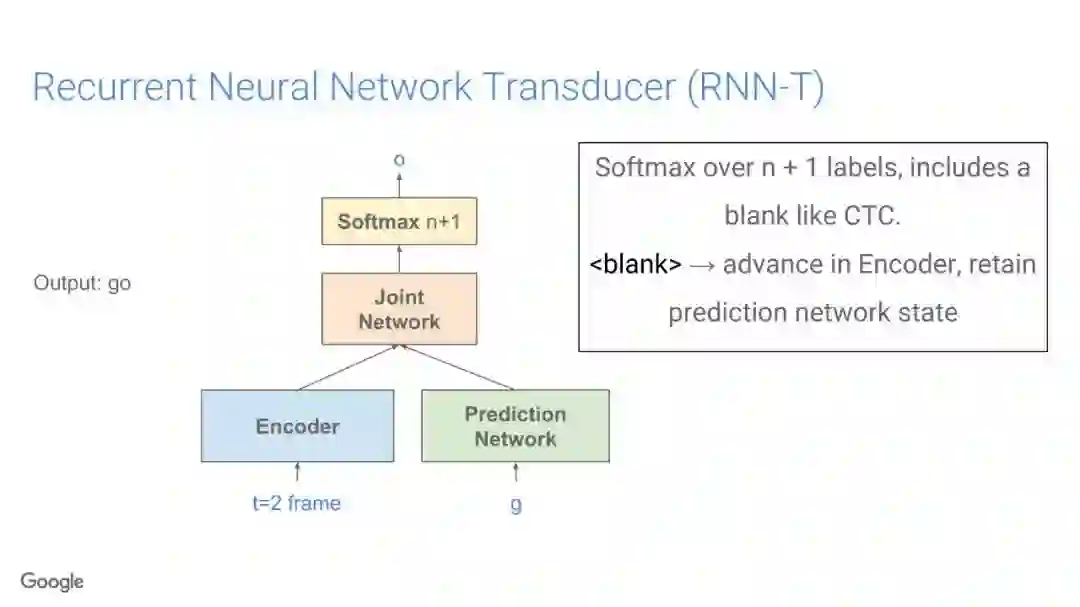
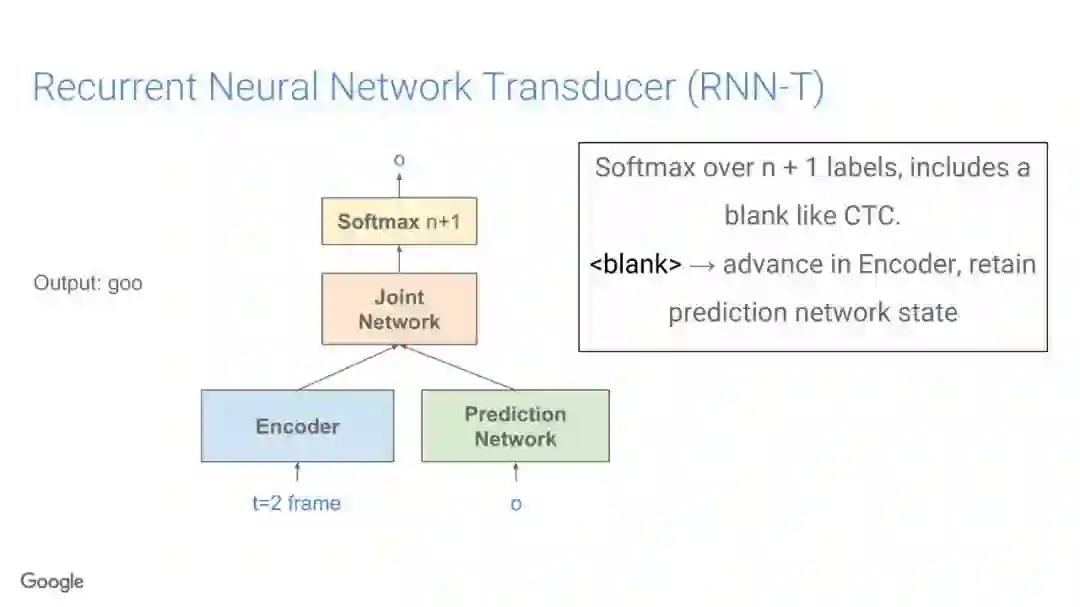




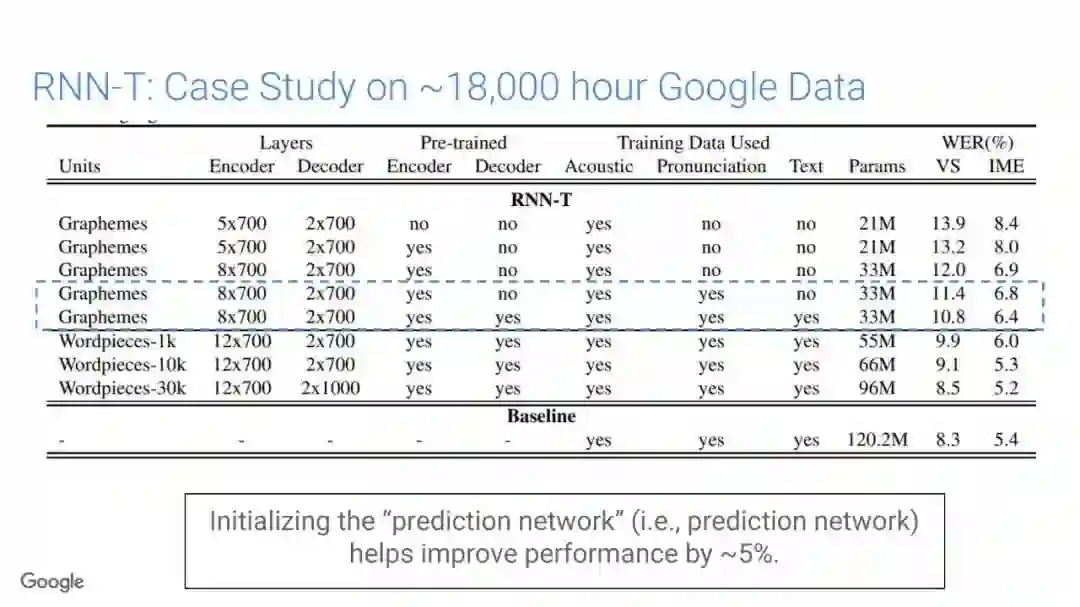
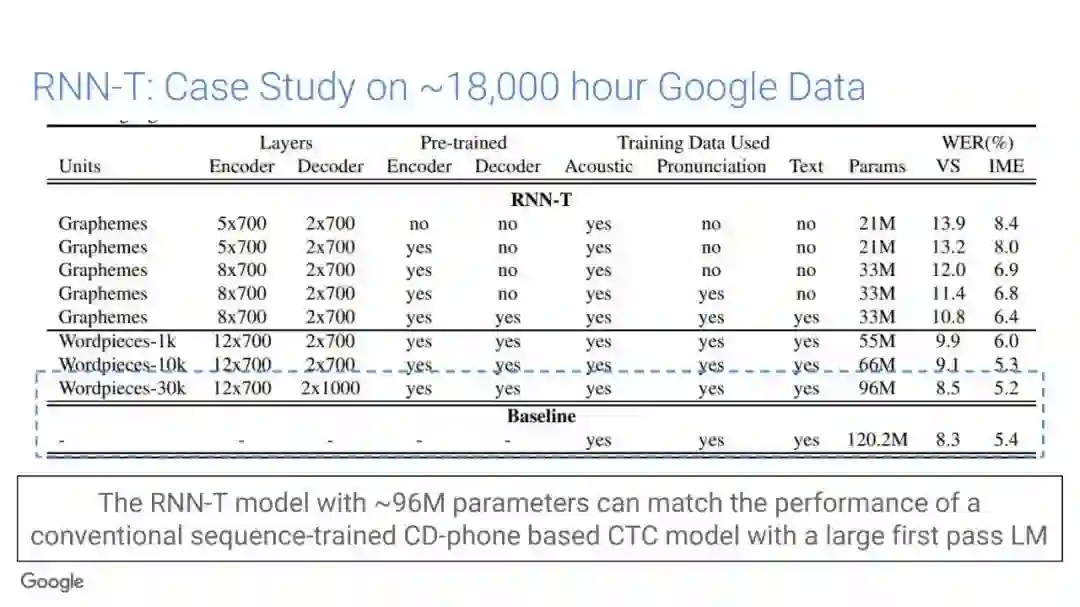

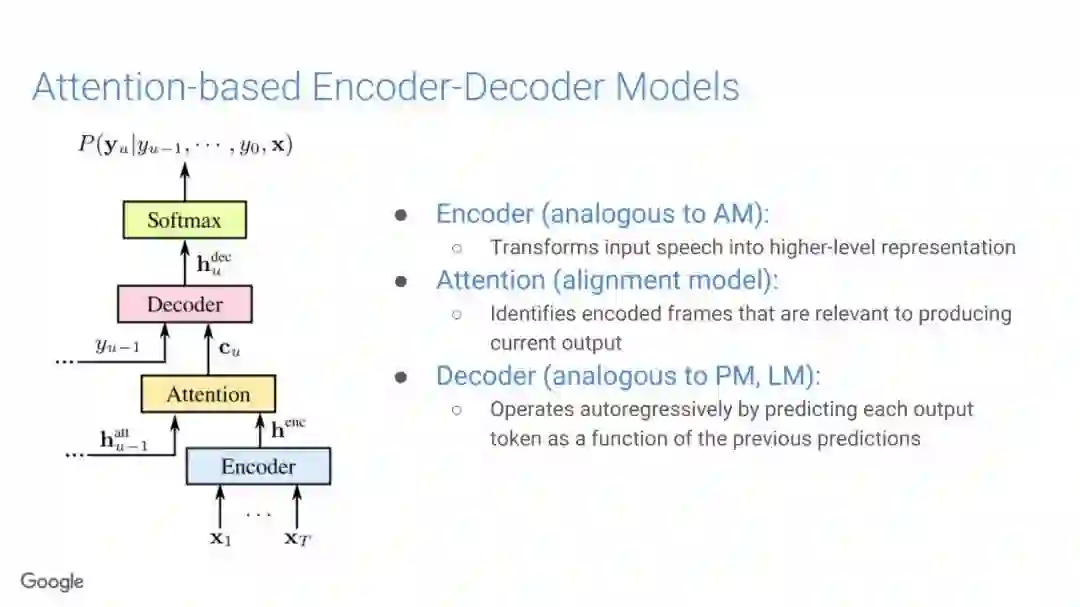
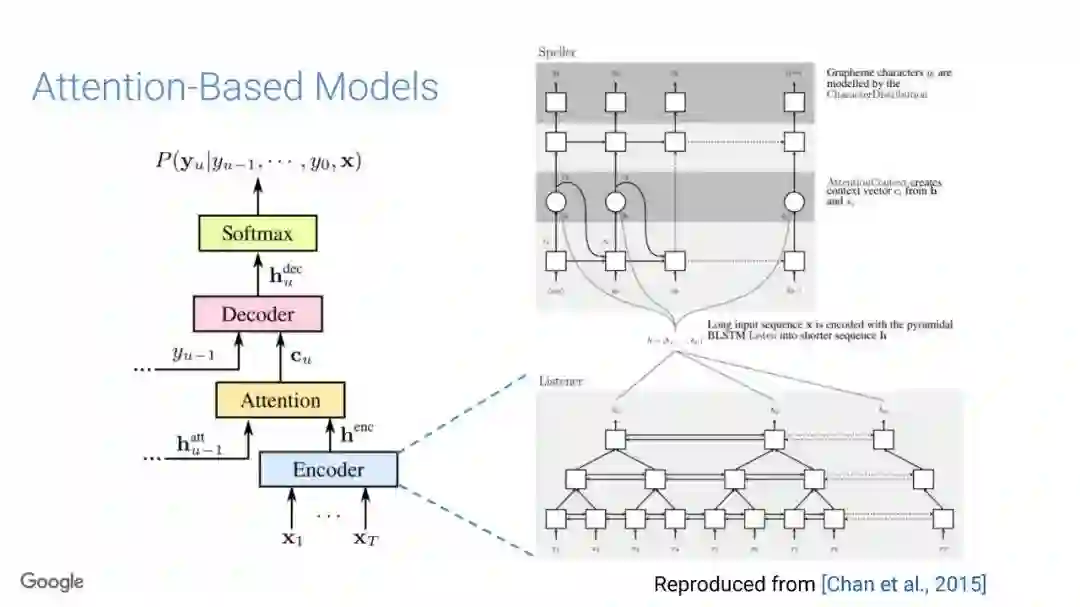

















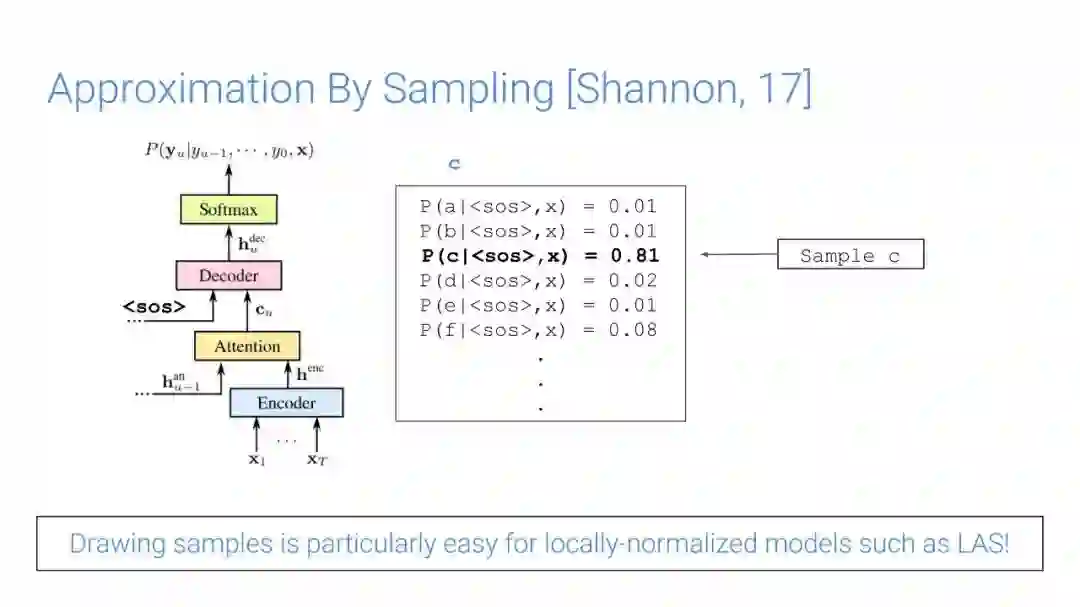
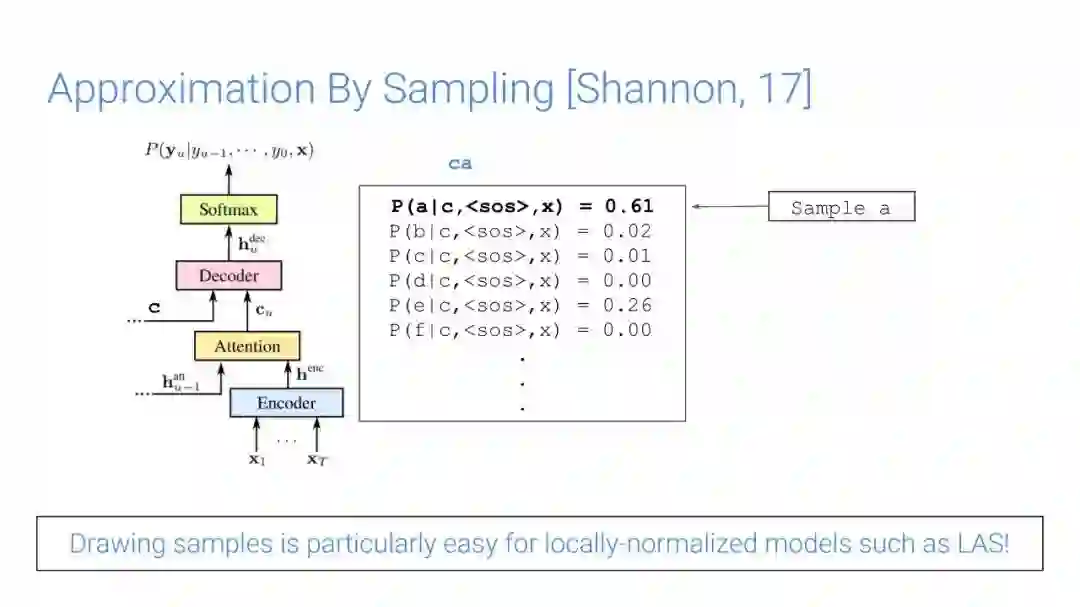





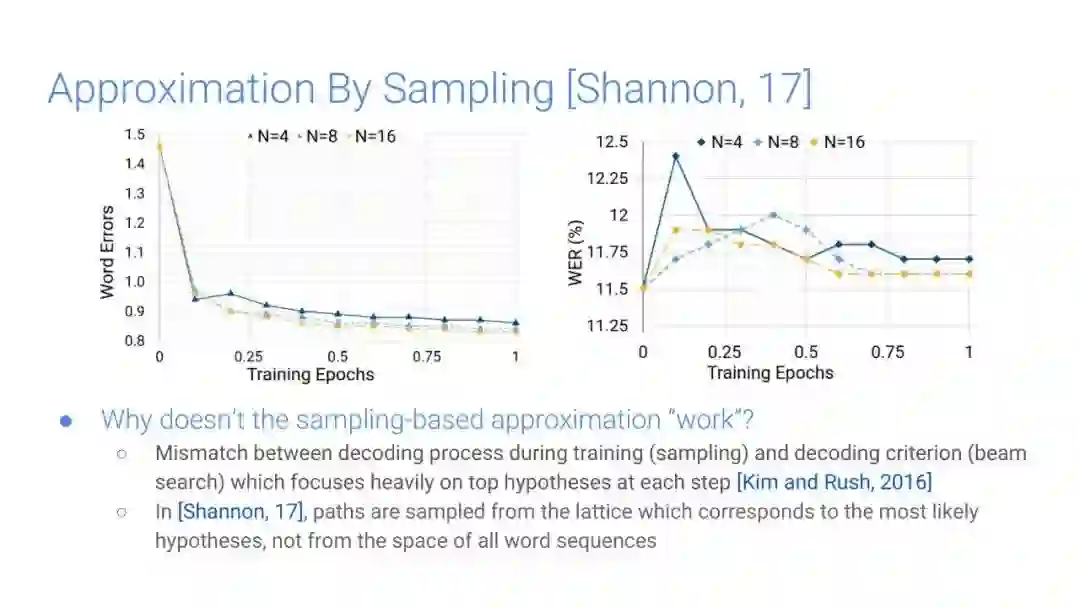


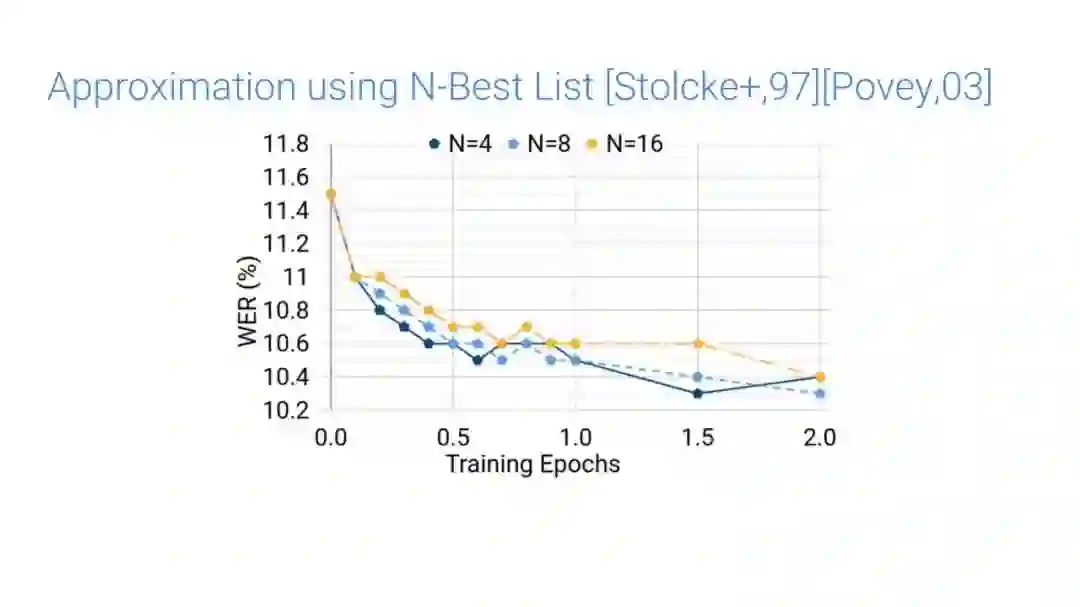

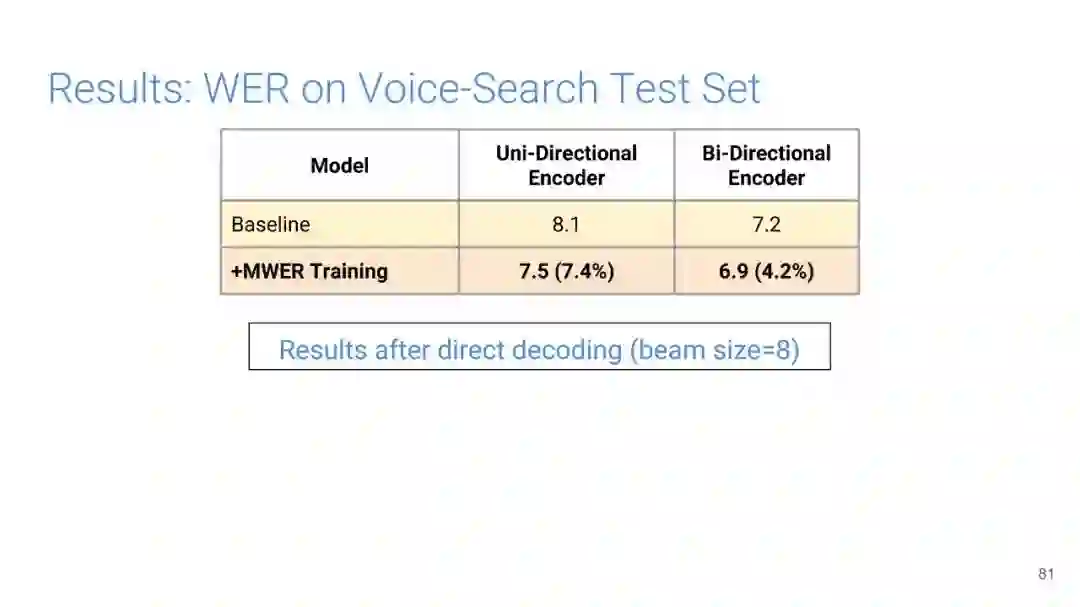


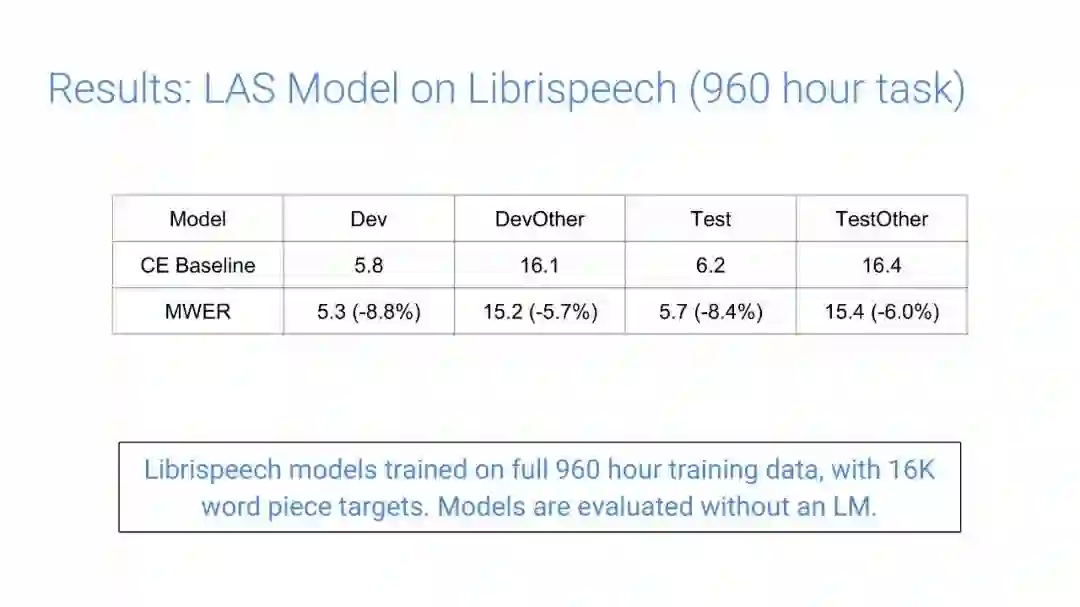

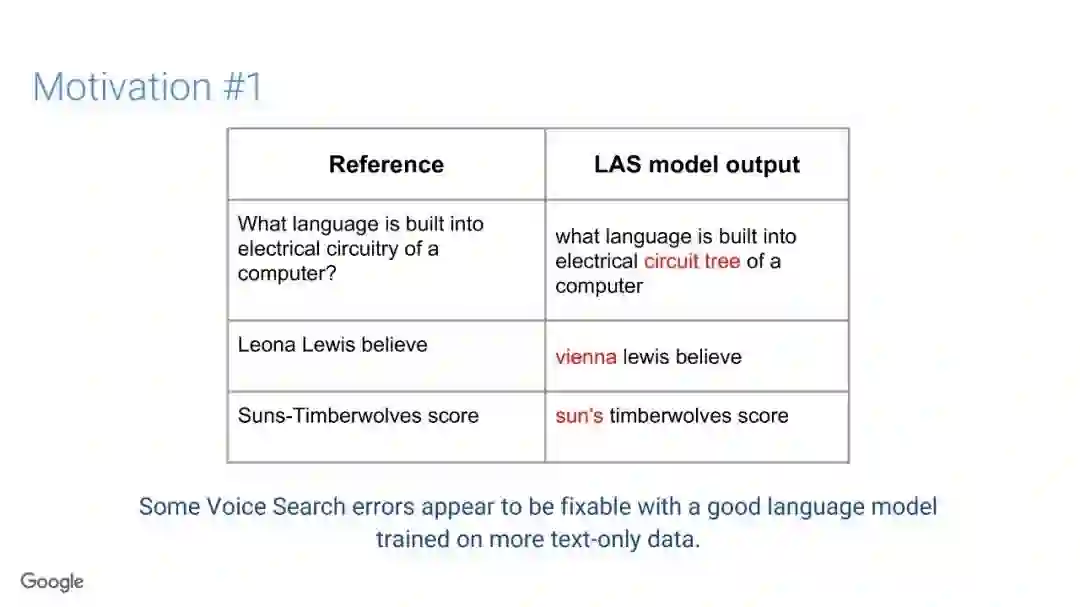


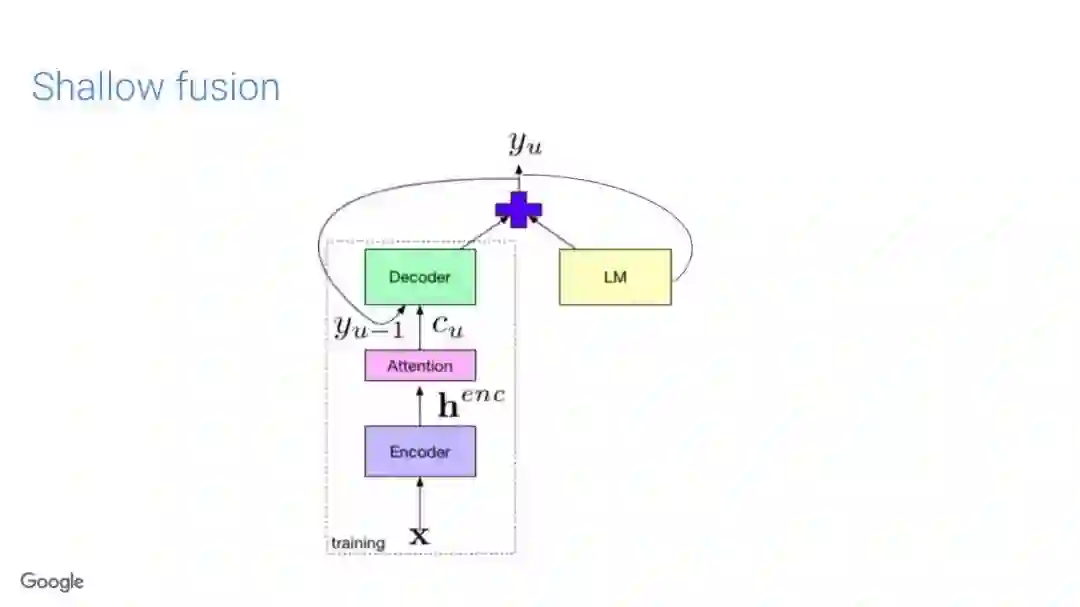






































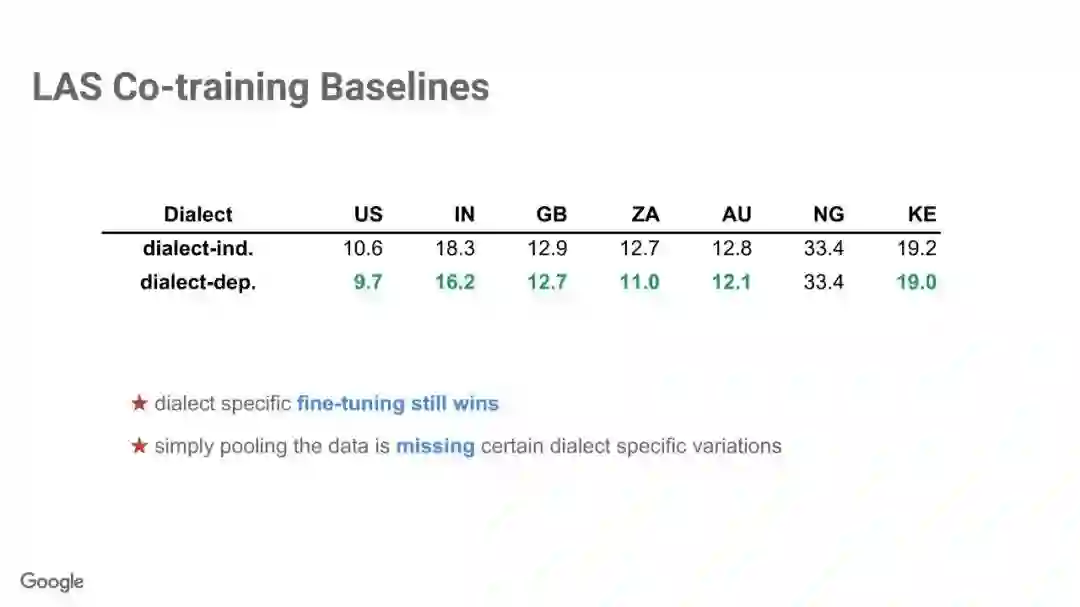
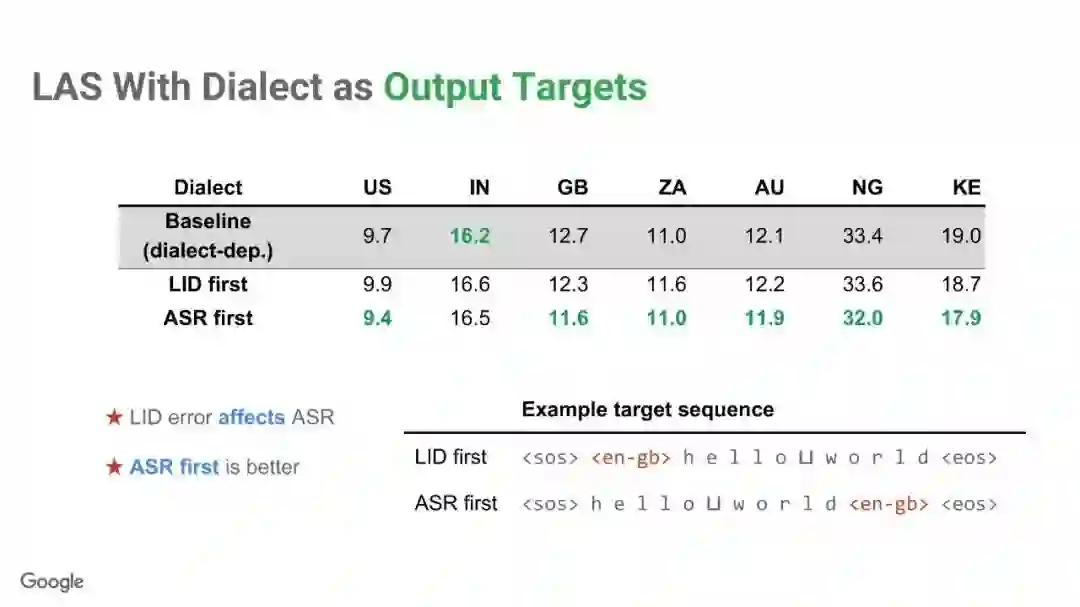
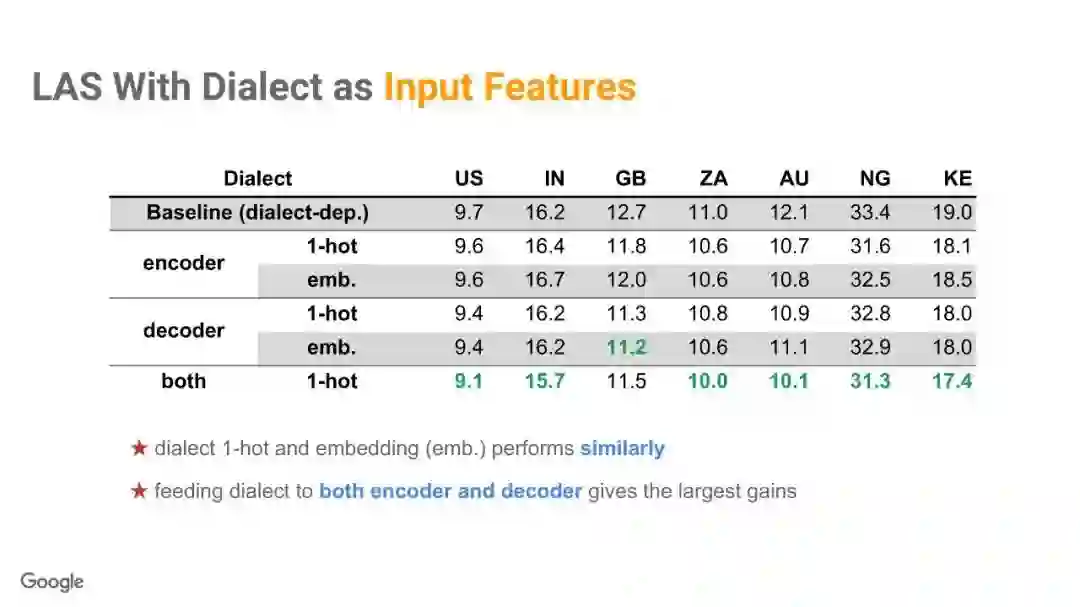

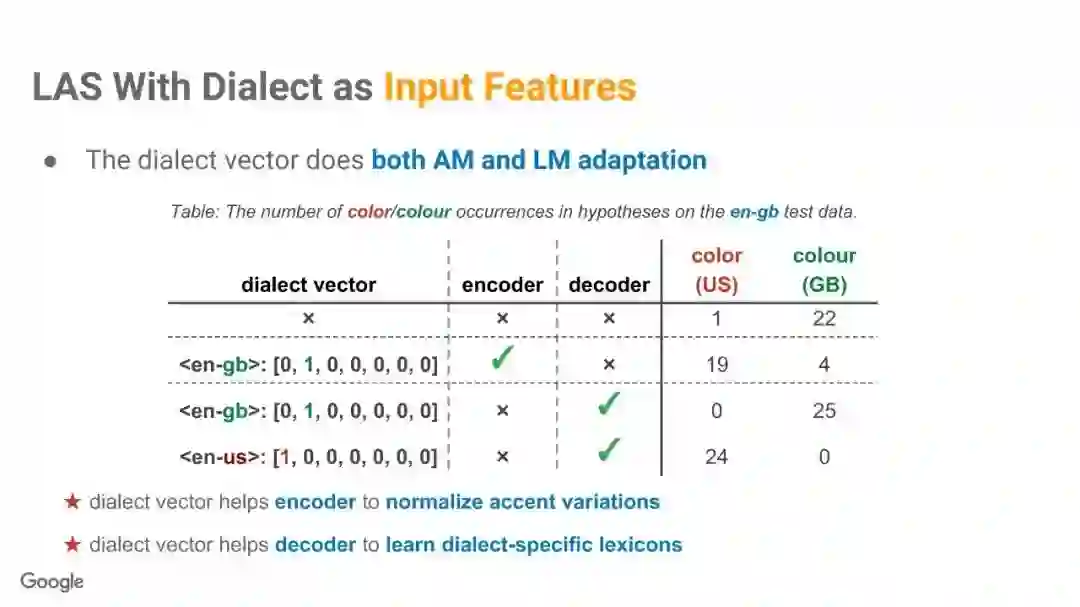










-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



