【EMNLP2019教程】分布式词向量表示,附239页PPT下载
导读
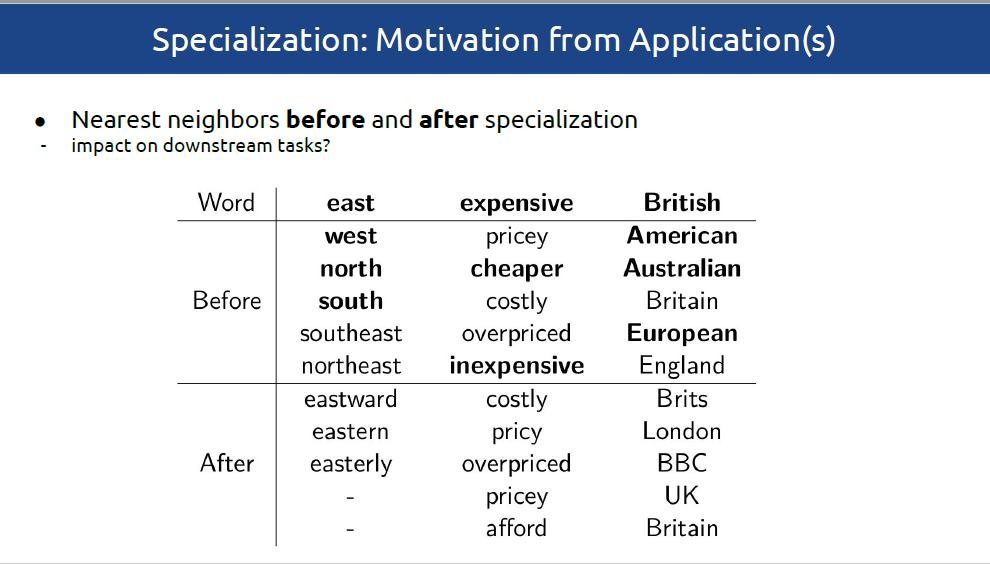
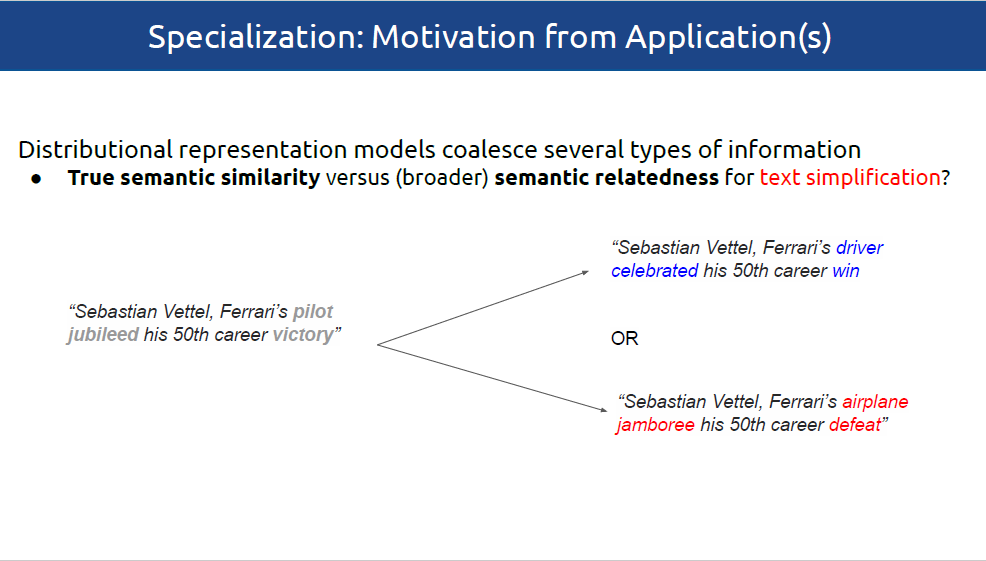
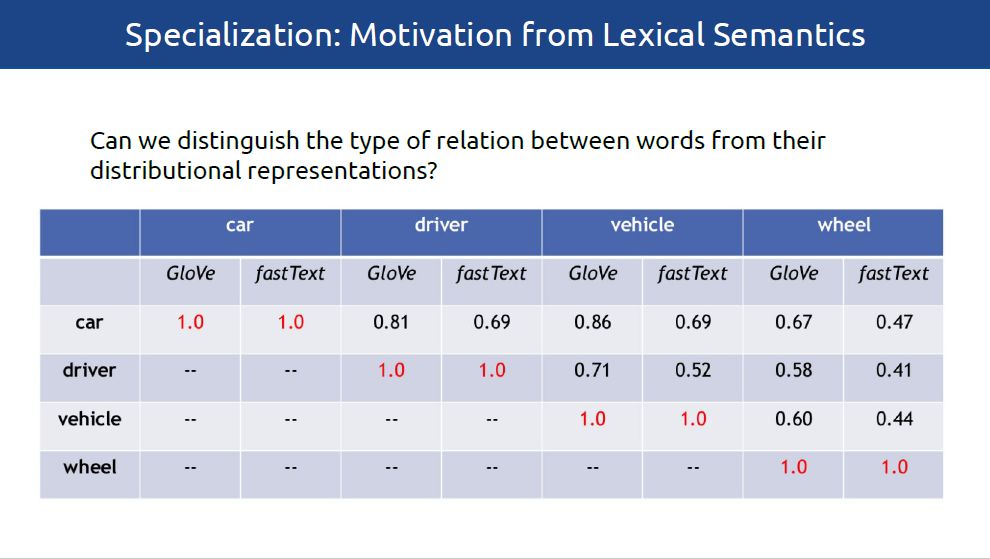
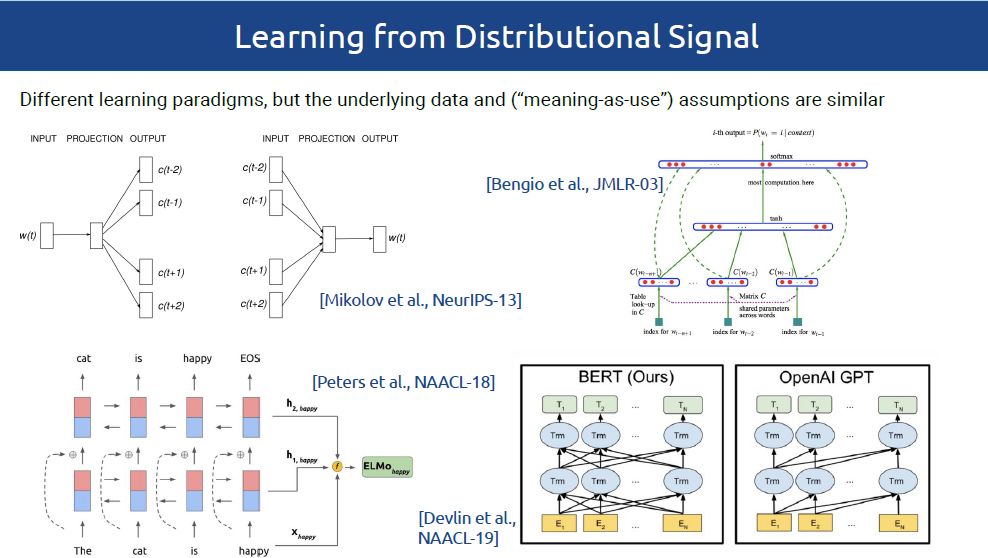
当前,分布式词向量已经成为NLP模型必不可少的一部分。基于潜在分布假设,分布式词向量,融合了各种聚合型和组合型的词汇语义关系。比如,基于分布式向量空间距离的主题关联,经常不能区分诸如同义词、相似词(car-automobile)或者词义蕴含(car-vehicle)等这些关系。由于不同的词汇语义关系支持不同的NLP应用,所以分布式空间的内在属性通常会影响下游应用的表现。如语义相似性为意译、对话状态跟踪和文本简化提供了指导,词义蕴涵支持自然语言推理和分类归纳,而更加广泛的主题关联则有助于命名实体识别、文本分类以及检索等任务。
在该教程中,作者对分布式词向量的语义特定化(Semantic Specialization of Distributional Word Vectors)方法进行了全面的概述,包括以下几点:1)joint specialization 方法,利用外部语言约束来增强分布式学习的目标。2)post-processing retrofitting模型:微调预训练的分布式词向量,以便更好地反映外部语言约束。3)最新提出的post-specialization方法,能够将2)中的post-processing方法扰动推广到整个分布式空间。

目录

介绍与动机:分布式特征模型,词汇关系,外部资源,信息互补等。(20min,lvan)
对于语义相似性的专门化方法:相似性,关联度以及其他关系等。(45min,lvan)
对于LE和其他关系的专门化方法:词义蕴含的专门化方法,在向量空间中嵌入层次结构等。(35min,Goran)
专门化方法的跨语义迁移:对于目标语言专门化的不同方法,支持资源贫乏语言的词汇资源建设等。(25min,Goran)
对于上下文表征模型的专门化:LIBERT,K-BERT,ERNIEs等(45min,Edoardo)
挑战,开放问题与结论(10min,Edoardo)

完整PPT下载:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMNLP2019DRM” 就可以获取本文完整PPT下载链接~





完整PPT下载:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMNLP2019DRM” 就可以获取本文完整PPT下载链接~
更多关于“分布式词向量”的论文知识资料,请登录专知网站www.zhuanzhi.ai,查看:
https://www.zhuanzhi.ai/topic/2001473347629013/paper