

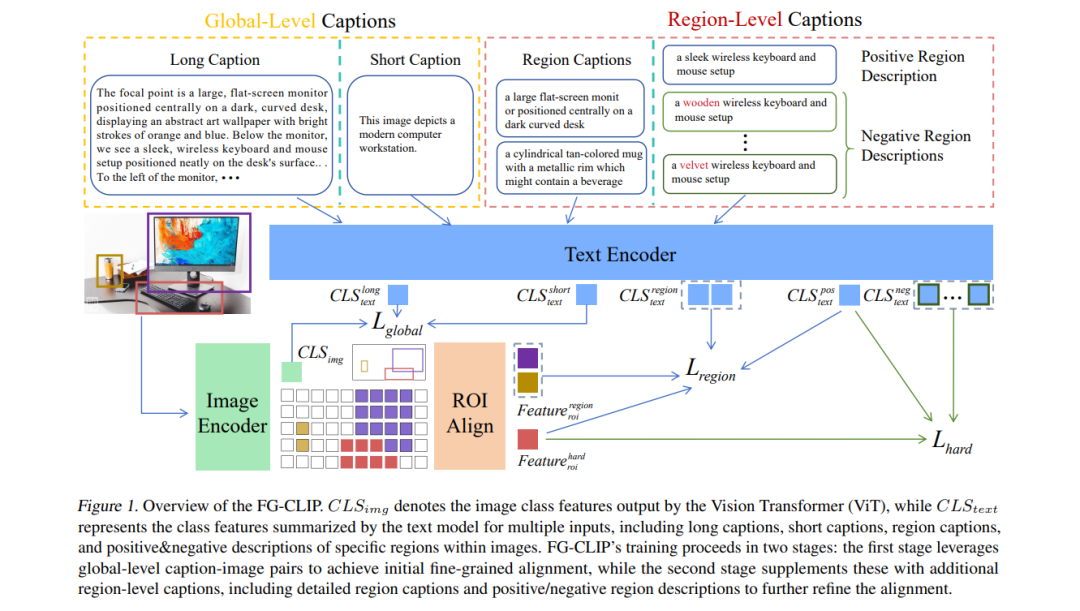
**CLIP(Contrastive Language-Image Pre-training)**在图文检索与零样本分类等多模态任务中表现出色,但由于其训练数据以粗粒度简短描述为主,在细粒度理解方面存在不足。为了解决这一问题,我们提出了 FG-CLIP(Fine-Grained CLIP),通过三项关键创新显著提升细粒度理解能力。 首先,我们利用大规模多模态模型生成了 16亿对长文本描述与图像的配对数据,以捕捉全局语义细节。其次,构建了一个高质量数据集,包含 1200万张图像与4000万个区域级别的边界框,并配以详细文本描述,以确保表示的精确性与语境丰富性。第三,我们引入了 1000万个细粒度难负样本,以增强模型对微小语义差异的区分能力。针对上述数据,我们设计了相应的训练策略。 大量实验结果表明,FG-CLIP 在多个下游任务中(包括细粒度图文理解、开放词汇物体检测、图文检索及通用多模态评估基准)均优于原始 CLIP 和其他最新方法。这些成果凸显了 FG-CLIP 在捕捉图像细节、提升整体性能方面的有效性。 相关数据、代码与模型可通过以下链接获取: 🔗 https://github.com/360CVGroup/FG-CLIP
成为VIP会员查看完整内容
相关内容
Arxiv
38+阅读 · 2023年4月19日
Arxiv
207+阅读 · 2023年4月7日
Arxiv
10+阅读 · 2021年9月30日
相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
207+阅读 · 2023年4月7日
Arxiv
10+阅读 · 2021年9月30日