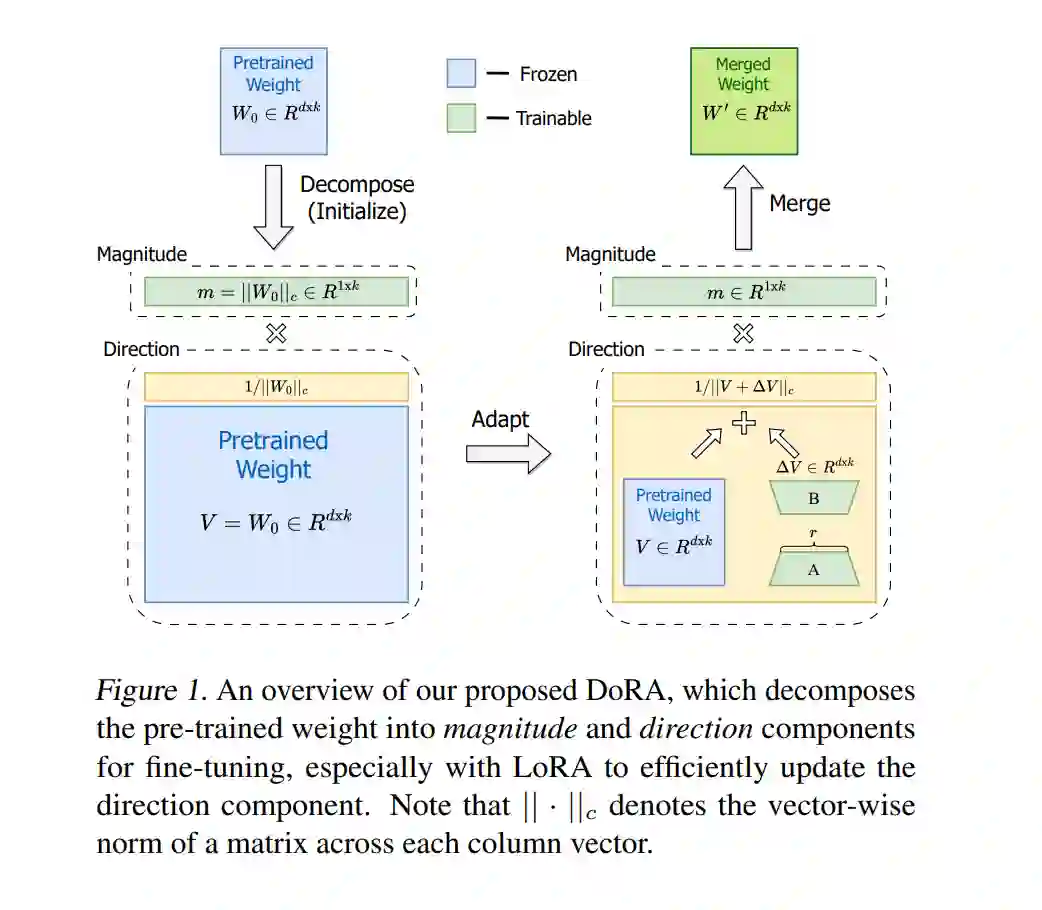
![]() 在广泛使用的参数高效微调(PEFT)方法中,LoRA及其变体因避免额外的推理成本而获得了相当的流行。然而,这些方法与完全微调(FT)之间通常仍存在准确性差距。在这项工作中,我们首先引入一种新颖的权重分解分析,以研究FT和LoRA之间的固有差异。为了模仿FT的学习能力,我们提出了权重分解的低秩适应(DoRA)。DoRA将预训练的权重分解为两个组成部分,幅度和方向,专门用于微调,并具体采用LoRA进行方向更新,以有效地最小化可训练参数的数量。通过使用DoRA,我们提高了LoRA的学习能力和训练稳定性,同时避免了任何额外的推理开销。在各种下游任务上,如常识推理、视觉指令调整和图像/视频-文本理解,DoRA始终优于LoRA,在对LLaMA、LLaVA和VL-BART进行微调时表现更佳。代码可在https://github.com/NVlabs/DoRA 获取。
在广泛使用的参数高效微调(PEFT)方法中,LoRA及其变体因避免额外的推理成本而获得了相当的流行。然而,这些方法与完全微调(FT)之间通常仍存在准确性差距。在这项工作中,我们首先引入一种新颖的权重分解分析,以研究FT和LoRA之间的固有差异。为了模仿FT的学习能力,我们提出了权重分解的低秩适应(DoRA)。DoRA将预训练的权重分解为两个组成部分,幅度和方向,专门用于微调,并具体采用LoRA进行方向更新,以有效地最小化可训练参数的数量。通过使用DoRA,我们提高了LoRA的学习能力和训练稳定性,同时避免了任何额外的推理开销。在各种下游任务上,如常识推理、视觉指令调整和图像/视频-文本理解,DoRA始终优于LoRA,在对LLaMA、LLaVA和VL-BART进行微调时表现更佳。代码可在https://github.com/NVlabs/DoRA 获取。
![]()