

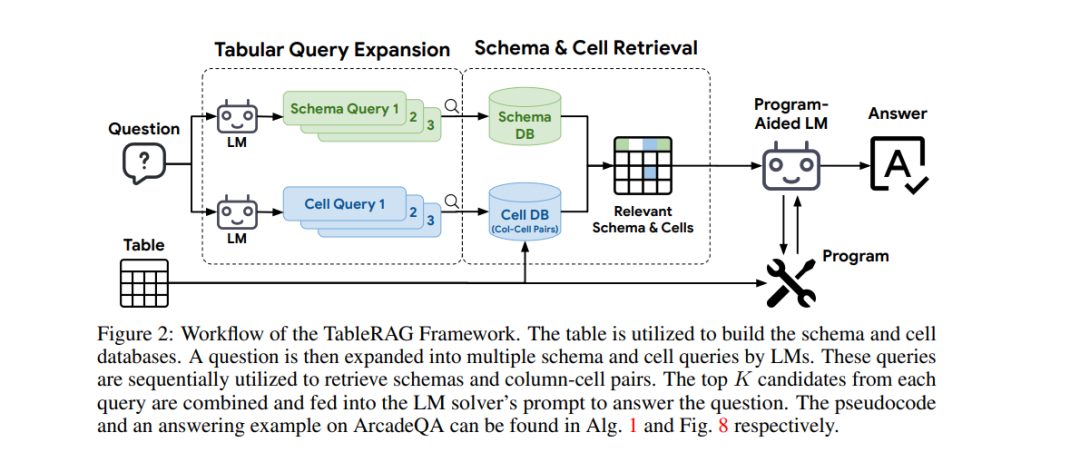
随着语言模型(LM)在处理表格数据能力方面的显著进步,尤其是通过程序辅助机制来操控和分析表格数据,其推理能力得到了显著提升。然而,这些方法通常需要将整个表格作为输入,这导致了由于位置偏差或上下文长度限制而产生的可扩展性问题。为应对这些挑战,我们引入了 TableRAG,这是一个专门设计用于基于LM的表格理解的检索增强生成(Retrieval-Augmented Generation, RAG)框架。TableRAG 利用查询扩展结合模式和单元检索,以在提供给语言模型之前精确定位关键信息。这种方法实现了更高效的数据编码和精准的检索,显著缩短了提示长度并减轻了信息损失。
为全面评估 TableRAG 在大规模应用中的有效性,我们基于 Arcade 和 BIRD-SQL 数据集开发了两个新的百万标记基准测试。我们的结果表明,TableRAG 的检索设计实现了最高的检索质量,并在大规模表格理解任务上达到了最新的技术水平。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日