

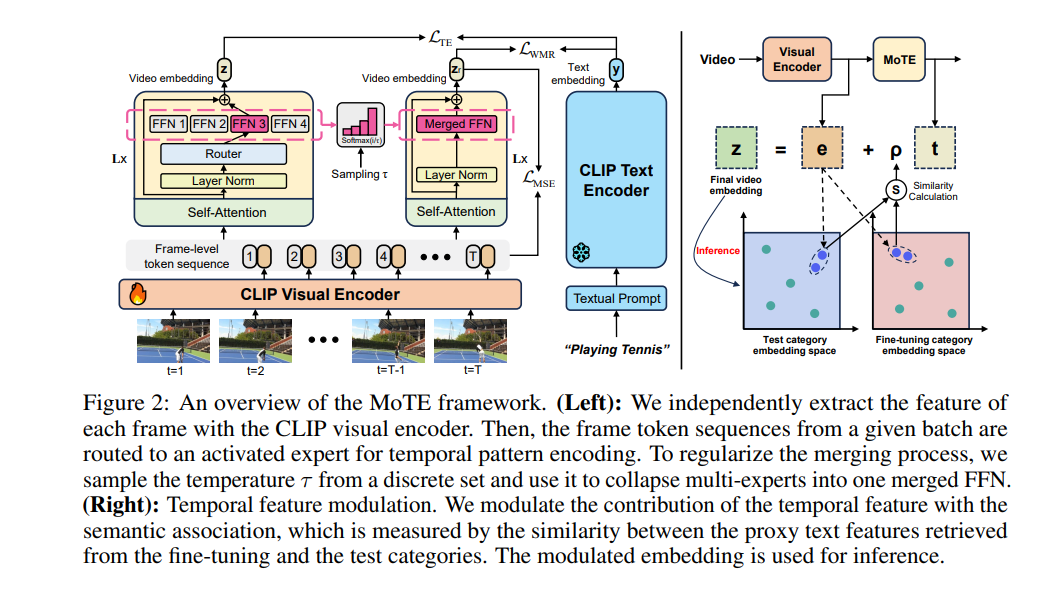
从大规模基础模型中转移视觉语言知识以用于视频识别已经被证明是有效的。为了弥合领域差距,额外的参数模块被添加以捕捉时间信息。然而,随着专用参数数量的增加,零样本泛化能力逐渐减弱,使得现有的方法在零样本泛化和闭集性能之间需要进行权衡。在本文中,我们提出了MoTE,一个新颖的框架,能够在一个统一的模型中平衡泛化和专门化。我们的方法通过调整一组时间专家的混合体来学习多个任务视角,并适应不同程度的数据拟合。为了最大程度地保留每个专家的知识,我们提出了“权重合并正则化”,它在权重空间中对专家的合并过程进行正则化。此外,通过时间特征调制来正则化测试期间时间特征的贡献。我们在零样本和闭集视频识别任务之间实现了良好的平衡,并在多个数据集(包括Kinetics-400 & 600、UCF和HMDB)上获得了最先进的或具有竞争力的结果。代码已发布在:https://github.com/ZMHH-H/MoTE。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日