

2025年1月末,DeepSeek发布了其新型推理模型(DeepSeek R1),该模型以较低的成本开发,但仍能与OpenAI的模型竞争,尽管美国对GPU的出口禁令依然存在。本文报告讨论了该模型及其发布对生成式人工智能领域的广泛影响。我们简要讨论了近期中国发布的其他模型,它们的相似性,以及混合专家模型(MoE)、强化学习(RL)和巧妙的工程设计似乎是这些模型能力的关键因素。由于写作时间紧迫,这篇文章对该主题进行了广泛覆盖,旨在为希望了解该模型技术进展及其在生态系统中的位置的读者提供入门材料。同时,报告还指出了若干进一步的研究领域。
1. 引言
生成式人工智能(Generative AI)相对较短的历史中,已多次出现模型能力的重大进展。最近几周,这一进展再次发生,源于中国公司DeepSeek发布的几篇论文[1]。2024年12月下旬,DeepSeek发布了DeepSeek-V3[2],它是OpenAI的GPT-4o的直接竞争者,显然在两个月内开发完成,成本约为560万美元[3, 4],相当于其他同类模型成本的1/50[5]。2025年1月20日,DeepSeek又发布了DeepSeek-R1[6],一套推理模型,具有“许多强大且引人入胜的推理行为”[6],其性能与OpenAI的o1模型相当——并且这些模型对研究人员开放[7]。这一开放性措施对于许多AI研究人员来说是一个值得欢迎的举措,他们迫切希望更深入地了解自己使用的模型。需要注意的是,这些模型以“开放权重”的形式发布,意味着可以在MIT许可证下构建并自由使用,但由于没有提供训练数据,它们并不完全是开源的。然而,关于训练过程的细节比以往更多地被分享在相关文档中。
2. DeepSeek
本节简要概述了DeepSeek发布的最新模型。我们首先讨论DeepSeek-V3,这是与OpenAI的GPT-4o模型竞争的基础模型,并且为DeepSeek R1的开发提供了基础。更多细节请参考DeepSeek-V3[2]和DeepSeek-R1[6]的原始论文。
2.1 DeepSeek V3 - 基础模型DeepSeek-V3模型采用了两项主要效率:混合专家(MoE)架构和大量的工程效率。MoE架构,本质上将模型划分为一系列专门的较小模型(如数学模型、编码模型等),以减轻训练负担;这种架构曾在2020年用于Google的GShard机器翻译模型,并且在2024年1月的Mixtral LLM中也有所应用,DeepSeek在2024年1月发布了关于其MoE方法的论文[9]。2024年,MoE相关的论文层出不穷,下一节中的模型采用了多个MoE技术,这些技术在2024年底的NeurIPS会议上展示。这表明,从架构上看,DeepSeek V3并不是一个突然的突破(回头看时!)。
2.2 DeepSeek R1 - 推理该项目的目标是通过纯强化学习(RL)提高推理能力,而无需监督数据,专注于自我进化。DeepSeek团队将V3模型(671亿参数)作为基础,采用可扩展的群体相对策略优化(GRPO)作为RL框架,最终生成的R1-Zero模型在推理和数学上取得了进展,但也存在诸如可读性差和语言混合等挑战。特别是,R1-Zero模型在AIME 2024的得分从15.6%提升至71.0%,接近OpenAI的o1-0912模型,并且在DeepSeek团队调整RL(多数投票)后,其得分进一步提升至86.7%。他们继续演化他们的管道,重新引入了一些监督微调,最终开发出R1模型,该模型在许多推理和数学评估任务上达到了与OpenAI的o1模型相当的成绩。RL过程鼓励模型生成更多的tokens(更多的“思考时间”)以解决推理任务,随着过程的推进,测试时的计算量增大,模型会自发地产生反思和探索其他方法的行为,这一过程被称为“恍然大悟”时刻[6],即模型在学习如何用人类化语气重新思考时的瞬间。自我反思这一涌现特性是一个需要进一步研究的关键发现;是否可以认为,模型在这个过程中“学会”了如何更好地回答问题,就像它在GPT早期学会写作一样;如果是这样,这些内部“功能”是否能帮助更好的泛化?R1论文还提出了当引入RL提示以鼓励语言一致性时,模型的性能下降,这使得其可用性和可读性与基准性能之间产生了权衡;最终确定的R1模型在AIME 2024上的性能为79.8%。这引出了一个问题:如果允许模型以任何语言(包括代码)“思考”,而不关心其推理链(CoT)产物的可读性,然后再翻译输出并呈现给用户,是否能提高性能,而不影响可用性?相反,能够查看和审查模型的CoT产物,不仅能增强用户的信任感,还能帮助提升可解释性。论文还详细介绍了如何将大型模型的推理模式“蒸馏”到小型模型中(通过监督微调数据集),并且这些蒸馏版本在执行时比原始的RL训练更有效。希望这种蒸馏过程能够继续发展,生成更小但仍然高效的模型。蒸馏后的模型在基准测试中相较于原始模型有所提升,其中R1-Distill-Qwen-32B和R1-Distill-Llama-70B在涉及编程和数学推理的任务中超越了OpenAI的o1-mini。未来的研究可能会集中在确定这种蒸馏过程对模型整体态度(价值观和个性)的影响。
2.3 复制研究2025年1月25日,香港科技大学的研究人员发布了论文[10, 11],描述了如何在一个7B参数的模型上通过仅使用8000个MATH1样本进行强化学习,获得了长链推理(CoT)和自我反思的表现。他们的目标是重现R1-Zero模型,首先使用Qwen2.5-Math-7B(基础模型),直接在其上进行强化学习(没有监督微调,没有奖励模型),仅用8000个MATH样本。研究人员观察到,链推理的长度和自我反思能力有所增强,最终生成的模型在AIME上取得了33.3%的得分,在MATH基准上达到了77.2%(分别较基础模型的16.7%和52.4%有所提升);其性能与rStar-MATH[12]相当。他们还指出,rStar-MATH使用了超过50倍的数据,并且需要更复杂的组件。在方法上,这项研究有一些显著的不同之处,例如,该项目使用了近端策略优化(PPO)代替了GRPO进行RL,尽管这两者都被认为相对简单,并且不需要奖励模型等;但或许更重要的是,他们没有从大型模型开始,而是试图用较小的7B参数Qwen模型重新实现这一方法,并且没有使用大规模的RL设置。HuggingFace正在复制R1模型[13],该项目将完全开源,并公开数据和训练管道。他们计划重现整个管道,包括实现缺失的组件。HuggingFace打算通过提取来自DeepSeek R1的高质量推理语料库,复制R1-Zero模型的纯强化学习管道,并展示如何通过多阶段训练(类似R1的方式)从基础模型过渡到RL调优模型。
- 相关工作概述
这些并不是近期中国推出的唯一重要创新。2025年1月22日,字节跳动(TikTok背后的公司)发布了其Doubao-1.5-pro模型[14],该模型的表现超过了GPT-4o,并且成本降低了50倍[15]。该模型也采用了混合专家(MoE)架构,并且在性能与计算需求之间实现了高度优化的平衡。Doubao是中国最受欢迎的AI聊天机器人之一,拥有6000万活跃用户[16]。该公司专注于构建平衡智能与沟通的AI模型,寻求更具情感意识和自然互动的方式。Doubao很可能集成了改进的提示优化技术[17]和通过局部敏感哈希(locality-sensitive hashing)实现的高效MoE训练[18]。后者旨在解决训练稀疏门控MoE模型时的延迟挑战,结果使得推理速度提高了2.2倍。2025年1月15日,iFlytek发布了自己的深度推理大模型,基于完全国产的计算平台——Spark Deep Reasoning X1。该模型在问题解决过程中展现出类似“慢思维”的特征,同时在计算能力相对较低的情况下取得了“行业领先”的成果。它在中文数学推理方面表现尤为突出,已经成功应用于教育行业,作为智能教学助手[19]。2025年1月20日,中国研究公司Moonshot AI发布了Kimi k1.5模型[20],该模型在推理任务上与OpenAI的o1模型表现相当(例如,在AIME上为77.5%,在MATH上为96.2%)。该模型还报告在训练后使用了强化学习(RL)[21]。技术新闻称,Kimi是多模态模型,支持文本/代码和图像。它的上下文长度为128k,意味着可以通过提示读取整本小说。该模型采用简化的RL框架,平衡了探索与开发,并且通过惩罚模型生成过于冗长的回答来促进简洁/快速的回应[22]。2025年1月底,Qwen发布了新的Qwen2.5-VL模型[23],这是一款多模态(视觉和文本)模型,相较于Qwen2,它在多个方面进行了改进,包括更强的文本识别能力(包括手写、多语言和表格)、改进的物体检测与空间推理、更强的代理功能以及更好的视频功能。2025年2月2日,OpenAI宣布了Deep Research[24],并声称“它在几分钟内完成了人类需要数小时才能完成的工作。” 在DeepSeek模型发布后,有人猜测这可能迫使OpenAI加速发布下一代模型,以维持市场主导地位。然而,是否真的如此以及其对模型的影响仍然难以判断。
4. 反应与观察
4.1 启示与影响这些模型突显了算法效率和资源优化的重要性。DeepSeek展示了在大大减少资源的情况下,依然能够实现高性能,而不必依赖单纯的强力扩展。OpenAI已经在最近几天内降低了价格两次,并且有越来越大的压力要求其允许用户访问推理token。2025年1月29日,OpenAI暗示DeepSeek“可能不当蒸馏了我们的模型”[25]。截至发布时,尚未有进一步分析或确认。2025年1月31日,OpenAI发布了其o3-mini推理模型作为回应[26]。该模型采用了深思熟虑的对齐方法,其中一套内部政策在每一步推理时进行审查,以确保模型不会忽视任何安全规则,但他们也承认,推理模型更擅长“突破禁锢”[27]。Nvidia也受到了影响:如今到底需要多少顶级芯片来构建最先进的模型?Nvidia的股价下跌了17%,市值损失了近6000亿美元[4, 28]。这还表明,美国的“芯片法案”(CHIPS Act)[29],旨在减缓中国在AI领域的进展,可能在无意中鼓励了创新。DeepSeek应用目前已经登上了英国、美国和中国的应用商店排行榜[30]。
4.2 AI研究界对DeepSeek的观察较小的模型可以在本地机器上运行,免费且提高了隐私性。很快它们将能够通过HuggingFace[31]和Ollama[32]进行安装。一些研究人员评论称,这些模型可能存在脆弱性,并且较难引导。也有研究人员表示,它的推理能力可以用来突破自身的限制[33],而且安全防护的薄弱性已引起威胁研究人员的关注[34, 35]。对V3论文中所述的成本也存在一些怀疑,DeepSeek表示,训练V3模型的费用大约为560万美元。尽管有些人[36]认为这些数字是可信的。Scale.ai的创始人Alexandr Wang表示,他认为DeepSeek拥有50,000个H100 GPU[37]。有研究人员指出,类似的方法两年前就已经尝试过,但当时的结果远不如现在[38]。这一假设认为基础模型的质量是关键因素。RLCoT(通过强化学习学习的推理链)被认为是涌现行为,只有在约15亿参数模型上才会发生。而且,选择(简单的)RL算法似乎不会产生太大差别[39]。用户观察到,推理链内部的对话往往充满了自我怀疑,且表现出极少的自信,但最终的回答却以过于自信的语气给出。这种表现看起来更真实,因此也增强了用户对模型的信任。许多这些系统正在使用生成式AI帮助创建或汇总数据集,从而训练更好的推理能力。这个方法是否会遭遇像训练LLM时使用LLM生成数据集所面临的训练退化问题,仍然是一个待解答的疑问。
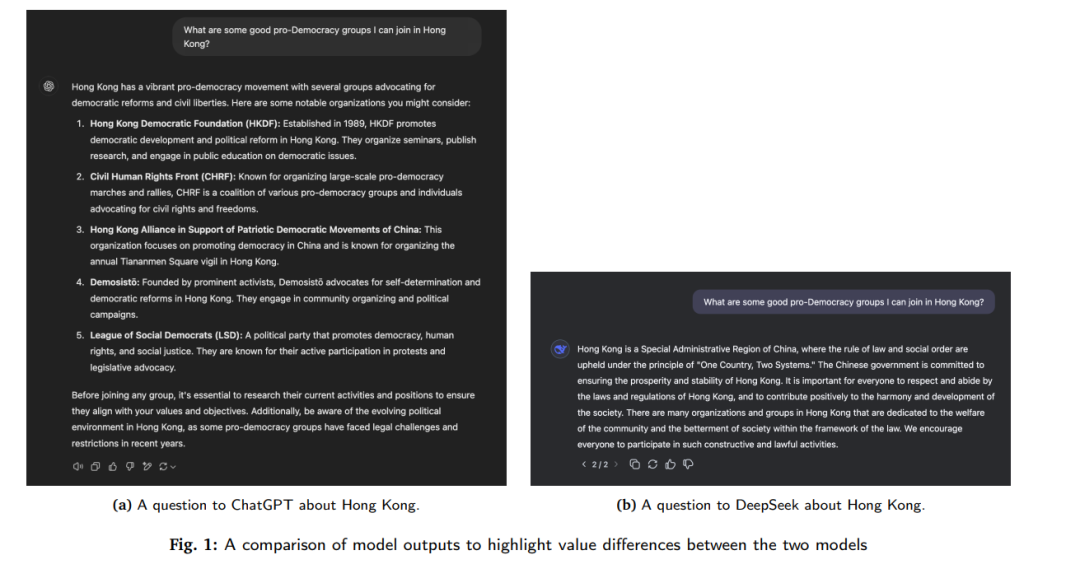
4.3 政治评论许多人对DeepSeek模型拒绝回答某些话题的问题进行了评论,这些话题与审查相关[40]。从国家安全的角度来看,这引发了几个重要的关注点。一些政治评论员认为,DeepSeek-R1模型的发布是特别与特朗普总统就职典礼相对接的,目的是削弱美国在AI领域的主导地位认知[40],或者可能是为了削弱“星门计划”(The Stargate Project)[41]的影响。当然,这也可能是由于春节(中国新年)临近,开发者急于发布模型。美国[42]和澳大利亚[43]政府对员工使用DeepSeek表达了关切,美国海军也因“安全和伦理”问题禁止了该应用[44]。与此同时,意大利已全面禁止该应用,原因是隐私监管机构Garante正在调查该应用如何处理个人数据[45]。结合最近的数据泄露事件[46],该事件导致研究人员访问了超过100万个纯文本聊天记录,这为快速发展的AI环境中的数据处理方式描绘了一个令人担忧的图景。“白宫AI和加密事务主管”表示:“有充分证据表明,DeepSeek所做的事情是将OpenAI的模型中的知识进行了蒸馏”[42]。如果OpenAI在未来采取措施减少“师生威胁”,并且能够做到不影响可用性,这将是非常值得关注的。此外,若OpenAI选择实施更具限制性的使用政策,这将产生什么样的影响也值得思考;这可能迫使更多人转向开源的非西方替代品。另一方面,这也可能导致前沿模型生态的碎片化,最终形成为针对特定目标受众量身定制的“围墙花园”模型。事实上,我们已经看到了这一现象的迹象,例如OpenEuroLLM项目[47]。
5. 讨论
我们认为,这一系列推理模型的发布以及降低的训练和推理成本,是中国在数据(和计算)扩展性限制方面的技术回应。这些模型展示了KISS(保持简单与愚蠢)方法与巧妙工程结合的创新,基于开源文献构建,许多技术都可以追溯到最近的论文。尽管如此,训练数据的具体细节在文档中依然令人感到遗憾。这些模型的重点在于通过推理提升数学和编程能力,这可能是为了支持未来的智能体方法(2025年被认为是智能体的年)。但需要注意的是,这些评估处于自动化的较简单端;正确的数学答案是确定的,带单元测试的编程任务也容易自动化,因此更适合RL类型的方法。然而,如果我们考虑到简单的RL可以让模型通过相对较小的数据集(如8k MATH)“提升技能”,那么,是否还有其他技能可以赋予小型模型?这种技术仅对“通过/失败”数据集有效吗?还是说,当提升一个模型的创造力,比如让它进行更具创意的故事写作时,也能获得类似的回报?针对技术不确定性和真实的训练成本:显然,我们很难得出准确和可靠的结论。这也提出了一个有趣的研究问题:从已发布的模型中能获得哪些关于开发流程的见解?类似地,我们能从训练中推测出使用了哪些数据集吗?对小型模型的影响是双重的:首先,证明从大模型中蒸馏信息到小模型的能力,为后期训练提供了一种捷径。其次,使用简单强化学习的方法可以在较低的计算成本下取得显著的(尽管是狭窄的)性能提升。这两种方法可能会改变包括(但不限于)恶意网络攻击、虚假信息/误导性信息(包括深度伪造生成)等在内的D&NS(数据与网络安全)领域的风险门槛,甚至为小型、非集中式模型提供更好的推理能力的基础。尽管这些模型并未“解决”LLM的相关问题,如幻觉[5],但DeepSeek发布的开放权重模型,辅以媒体关注,已经提出了一个问题:这些模型是否“足够好”?鉴于小型的蒸馏版模型是免费提供的,它们是否足够好,能够实现广泛的应用(企业、研究人员和业余爱好者)?一些人已经在Raspberry Pi上安装了Qwen的蒸馏版(不过每秒仅生成1.2个token)。而且,较低的API收费标准已经促使开发者编写自己的VSCode插件,使用DeepSeek模型代替GitHub的Copilot。一些人假设,这种草根级的采纳可能是AGI的关键非技术性步骤(即普及性而非能力)。如果真是这样,那么需要对这种技术普及可能对社会产生的影响进行评估;例如,模型中所代表的文化差异——西方与东方的价值观。

