3D Human相关研究总结:人体、姿态估计、人体重建等

©PaperWeekly 原创 · 作者|张莹
单位|腾讯

常用3D表示


+ 可以处理任意拓扑结构
- 随着分辨率增加,内存呈立方级增长
- 物体表示不够精细
- 纹理不友好

+ 可以处理任意拓扑结构
- 缺少点与点之间连接关系
- 物体表示不够精细
- 纹理不友好

+ 内存占有较少
+ 纹理友好
- 不同物体类别需要不同的 mesh 模版
- 网络较难学习
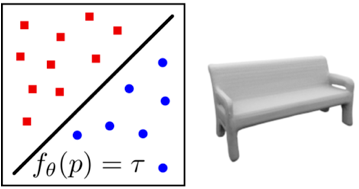
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构
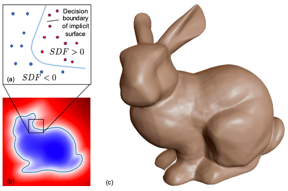
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构

常用3D人体模型

mesh 表示:6890 vertices, 13776 faces
pose 控制:24 个关节点,24*3 维旋转向量
shape 控制:10 维向量
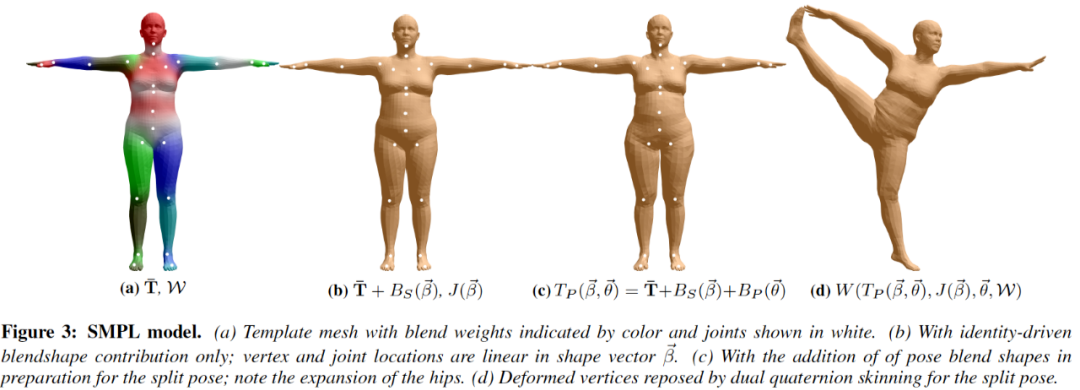
-
mesh 表示:10475 vertices, 20908 faces -
pose 控制:身体 54 个关节点,75 维 PCA -
手部控制:24 维 PCA -
表情控制:10 维向量 -
shape 控制:10 维向量
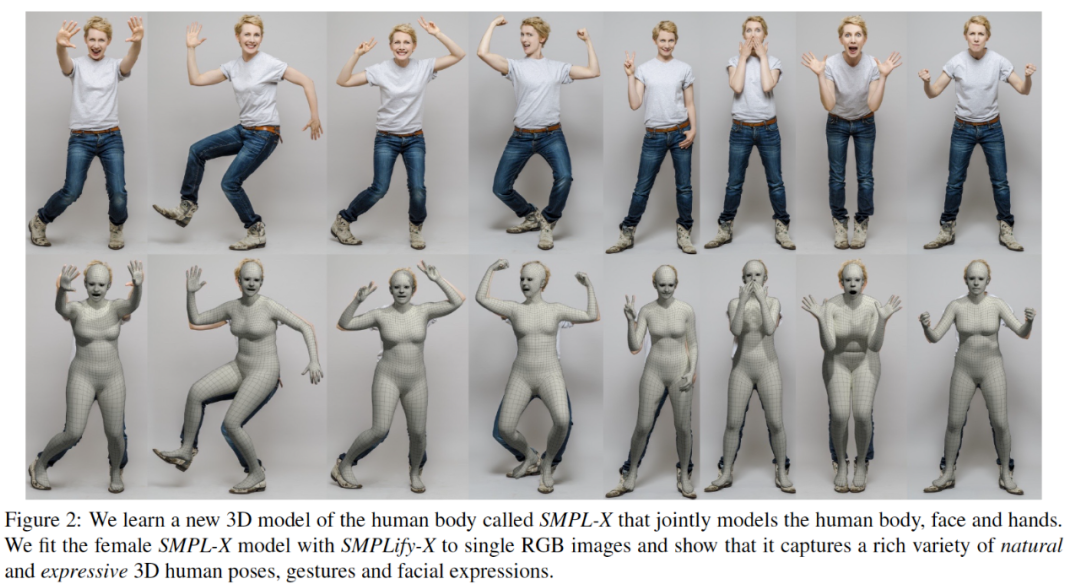

3D人体姿态估计

I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image. In ECCV, 2020.
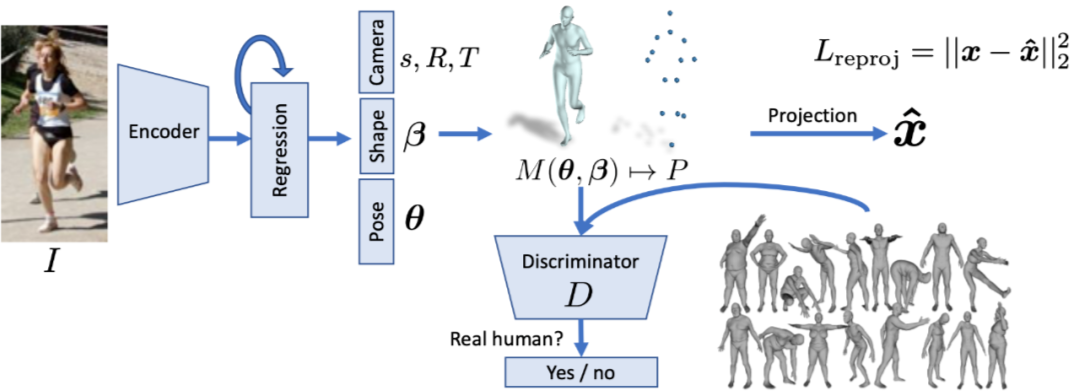
Learning 3D Human Dynamics from Video. In CVPR, 2019.
Monocular Total Capture: Posing Face, Body, and Hands in the Wild. In CVPR, 2019.
Human Mesh Recovery from Monocular Images via a Skeleton-disentangled Representation. In ICCV, 2019.
VIBE: Video Inference for Human Body Pose and Shape Estimation. In CVPR, 2020.
PoseNet3D: Learning Temporally Consistent 3D Human Pose via Knowledge Distillation. In CVPR, 2020.
Appearance Consensus Driven Self-Supervised Human Mesh Recovery. In ECCV, 2020.


3D人体重建

4.1 单张RGB图像
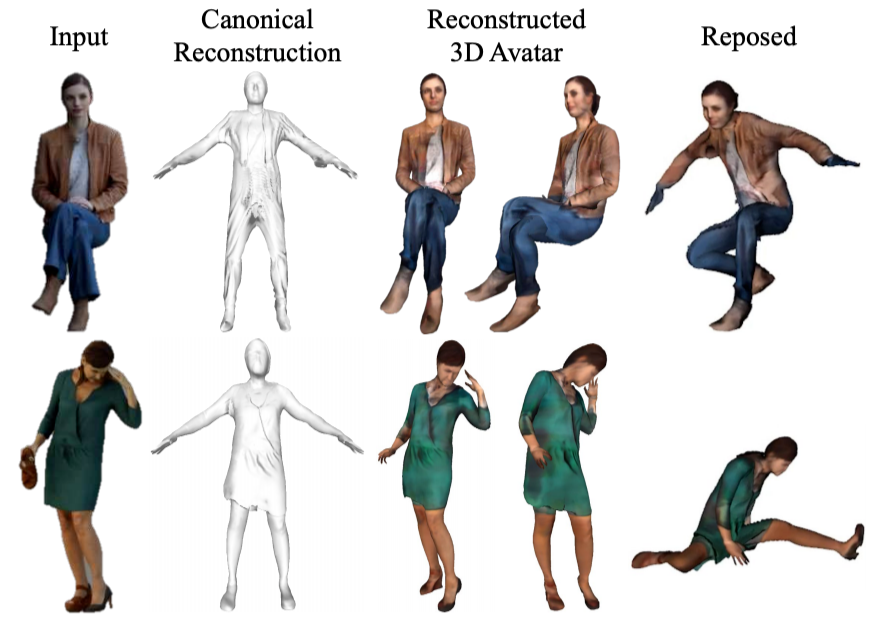
+ 带纹理
+ 能直接驱动
360-Degree Textures of People in Clothing from a Single Image. In 3DV, 2019.
Tex2Shape: Detailed Full Human Body Geometry From a Single Image. In ICCV, 2019.
ARCH: Animatable Reconstruction of Clothed Humans. In CVPR, 2020.
3D Human Avatar Digitization from a Single Image. In VRCAI, 2019.
-
带衣服人体表示:SMPL+Deformation+Texture; -
思路1:估计 3D pose 采样部分纹理,再用 GAN 网络生成完整纹理和displacement; 思路2:估计 3D pose 并 warp 到 canonical 空间中用 PIFU 估计 Occupancy;
优势:可直接驱动,生成纹理质量较高;
问题:过度依赖扫描 3D 人体真值来训练网络;需要非常准确的 Pose 估计做先验;较难处理复杂形变如长发和裙子;
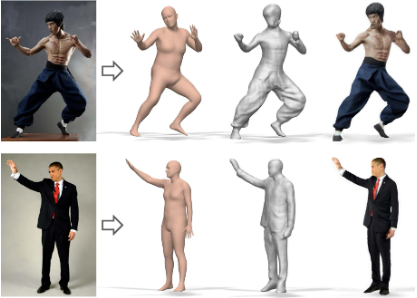
+ 带纹理
- 不能直接驱动
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. In ICCV, 2019.
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization. In CVPR, 2020.
SiCloPe: Silhouette-Based Clothed People. In CVPR, 2019.
PaMIR: Parametric Model-Conditioned Implicit Representation for Image-based Human Reconstruction. In TPAMI, 2020.
Reconstructing NBA Players. In ECCV, 2020.
带衣服人体表示:Occupancy + RGB;
思路1:训练网络提取空间点投影到图像位置的特征,并结合该点位置预测其 Occupancy 值和 RGB 值;
优势:适用于任意 pose,可建模复杂外观如长发裙子
问题:过度依赖扫描 3D 人体真值来训练网络;后期需要注册 SMPL 才能进行驱动;纹理质量并不是很高;

- 不带纹理
- 不能直接驱动
BodyNet: Volumetric Inference of 3D Human Body Shapes. In ECCV, 2018.
DeepHuman: 3D Human Reconstruction From a Single Image. In ICCV, 2019.
-
带衣服人体表示:voxel grid occupancy; -
思路1:预测 voxel grid 每个格子是否在 body 内部; -
优势:适用于任意 pose,可建模复杂外观如长发裙子 问题:需要另外估纹理;分辨率较低;过度依赖扫描 3D 人体真值来训练网络;后期需要注册 SMPL 才能进行驱动;

+ 带纹理
- 不能直接驱动
Deep Volumetric Video From Very Sparse Multi-View Performance Capture. In ECCV, 2018.
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. In ICCV, 2019.
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization. In CVPR, 2020.
-
带衣服人体表示:Occupancy + RGB; -
思路:多视角 PIFU; -
优势:多视角信息预测更准确;适用于任意 pose;可建模复杂外观如长发和裙子; 问题:多视角数据较难采集,过度依赖扫描 3D 人体真值来训练网络;后期需要注册 SMPL 才能进行驱动;纹理质量并不是很高;

+ 带纹理
- 不能直接驱动
-
带衣服人体表示:3D point cloud + triangulation; -
思路:GAN 网络生成 front-view 和 back-view 的 depth 和 color,再用 triangulation 得到 mesh; -
优势:适用于任意 pose;可建模复杂外观如长发和裙子; 问题:过度依赖扫描 3D 人体真值来训练网络;后期需要注册 SMPL 才能进行驱动;纹理质量并不是很高;
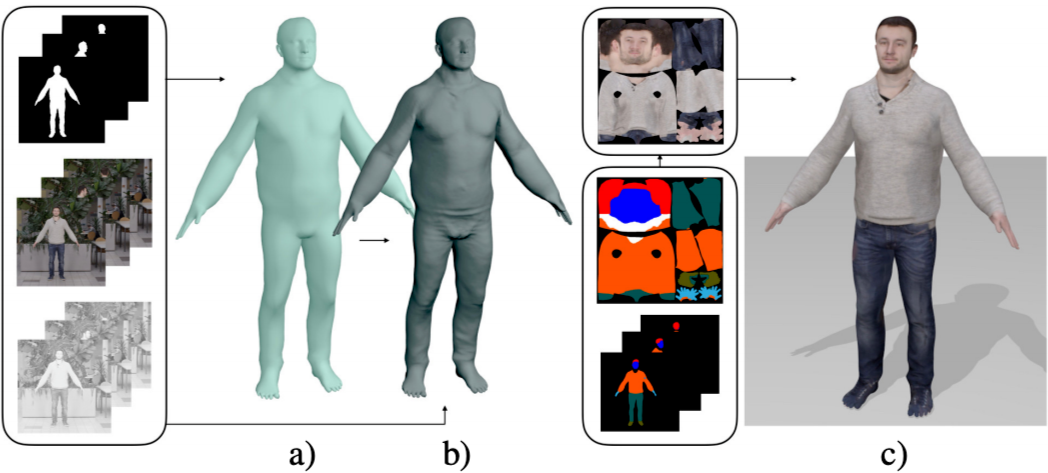
+ 带纹理
+ 能直接驱动
Video Based Reconstruction of 3D People Models. In CVPR, 2018.
Detailed Human Avatars from Monocular Video. In 3DV, 2018.
Learning to Reconstruct People in Clothing from a Single RGB Camera. In CVPR, 2019.
Multi-Garment Net: Learning to Dress 3D People from Images. In ICCV, 2019.
-
带衣服人体表示:SMPL+Deformation+Texture; -
思路1:多帧联合估计 canonical T-pose 下的 SMPL+D,投影回每帧提取纹理融合; -
优势:可直接驱动;生成纹理质量较高;简单场景下效果较好; 问题:过度依赖扫描 3D 人体真值来训练网络;需要较准确的 Pose 估计和 human parsing 做先验;较难处理复杂形变如长发裙子

- 不带纹理
- 不能直接驱动
-
带衣服人体表示:SMPL+Deformation; -
思路:每帧估计 SMPL 参数并联合多帧优化得到稳定 shape 和每帧 pose,为不同衣服建模形变参数化模型,约束 Silhouette, Clothing segmentation, Photometric, normal 等信息一致 -
优势:无需 3D 真值;可以建模较为细致的衣服形变; 问题:依赖较准确的 pose 和 segmentation 估计;只能处理部分衣服类型;

+ 带纹理
+ 也许能直接驱动
Robust 3D Self-portraits in Seconds. In CVPR, 2020.
TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video. In ECCV, 2020.
-
带衣服人体表示:Occupancy+RGB; -
思路1:RGBD 版 PIFU 生成每帧先验,TSDF(truncated signed distance function)分为 inner model 和 surface layer,PIFusion 做 double layer-based non-rigid tracking,多帧联合微调优化得到 3D portrait; -
优势:建模较精细,可以处理较大形变如长发和裙子;不需要扫描真值; 问题:流程略复杂;纹理质量一般;
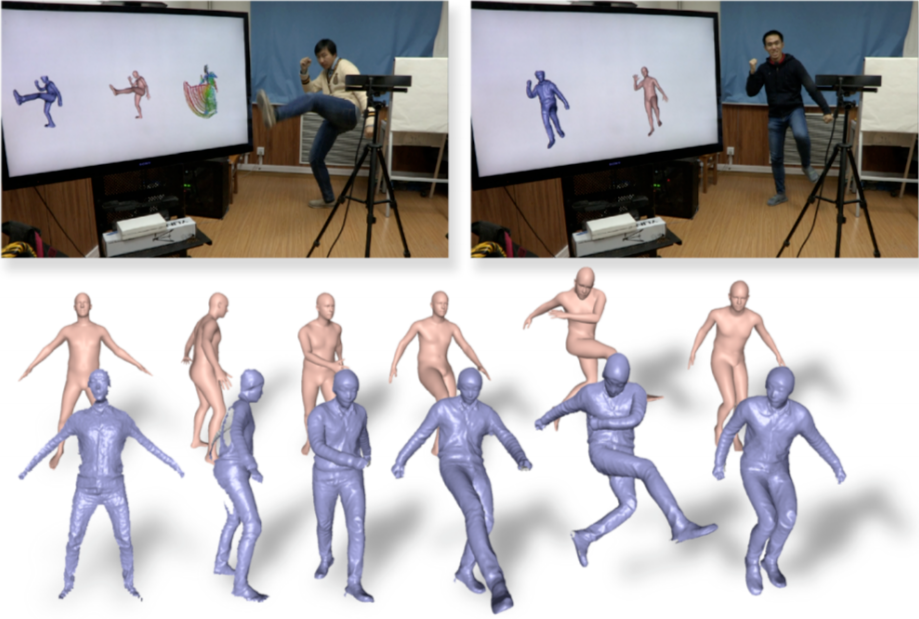
- 不带纹理
+ 也许能直接驱动
-
带衣服人体表示:outer layer + inner layer(SMPL) -
思路:joint motion tracking, geometric fusion and volumetric shape-pose optimization -
优势:建模较精细;速度快,可以实时; 问题:无纹理;

3D衣服建模

Physics-Inspired Garment Recovery from a Single-View Image. In TOG, 2018.
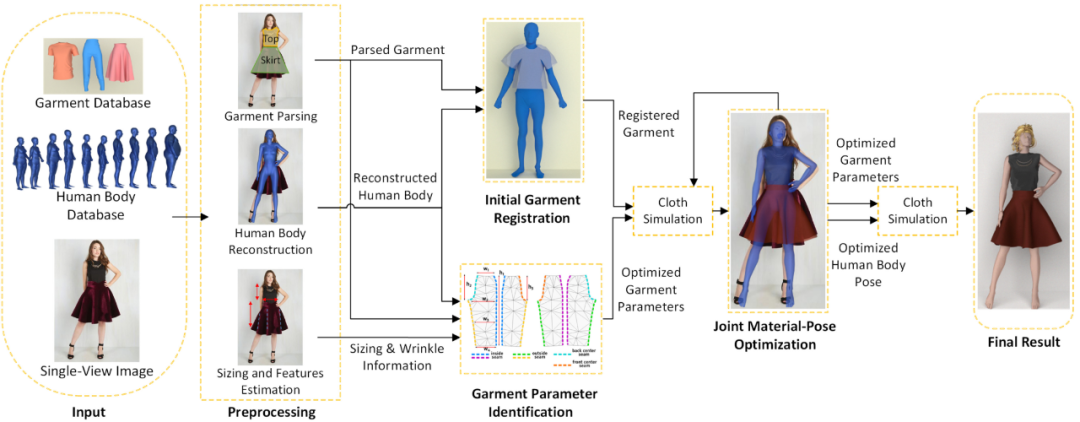
思路:衣服分割+衣服特征估计(尺码,布料,褶皱)+人体 mesh 估计,材质-姿态联合优化+衣物仿真;
优势:衣服和人体参数化表示较规范;引入物理、统计、几何先验;
-
问题:衣服特征估计受光照和图像质量影响较大,受限于 garment 模版的丰富程度;需要后期通过衣物仿真联合优化来调整效果;
DeepWrinkles: Accurate and Realistic Clothing Modeling. In ECCV, 2018.
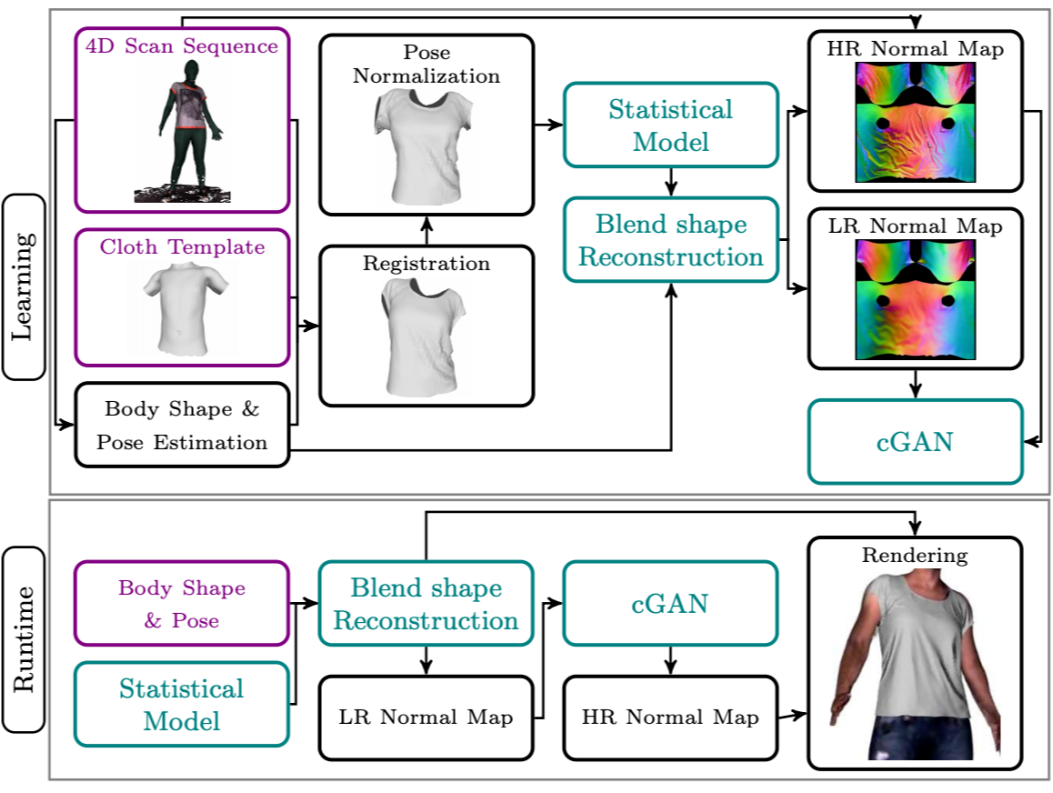
-
思路:统计模型学习衣服在某 pose 和 shape 下的大致效果,GAN 模型生成更细致的褶皱; -
优势:用 GAN 可以生成逼真细致的褶皱; -
问题:依赖 4D 扫描动作序列真值;需提前做好衣服注册;
Multi-Garment Net: Learning to Dress 3D People from Images. In ICCV, 2019.
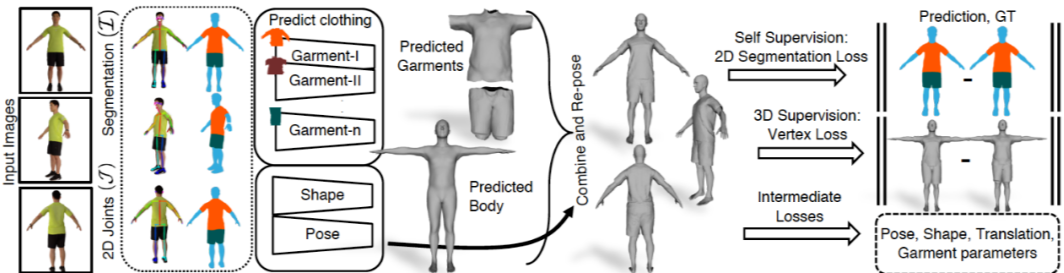
-
思路:human parsing 分割衣服并预测类别,估计衣服 PCA 参数和细节 Displacement; -
优势:明确 3D scan segmentation 和 Garment registration 的 pipeline;引入 Human parsing 可以得到更准确的衣服类别; -
问题:过度依赖 3D 真值训练;PCA 参数表示的准确性依赖 dataset 大小;
Learning-Based Animation of Clothing for Virtual Try-On. In EUROGRAPHICS, 2019.
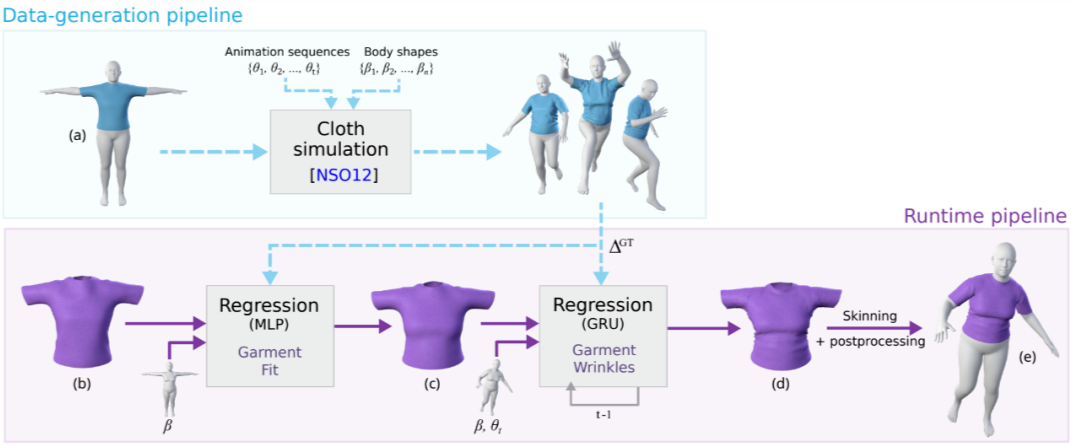
-
思路:衣服仿真生成真值帮助网络训练,基于 shape 学习衣服模版变形,基于 pose 和 shape 学习动态褶皱, -
优势:衣物仿真可以得到任意 pose 下的大量真值数据; -
问题:与现实数据差距较大;依赖衣物模版的丰富程度;直接学习 defromation 不够稳定,容易穿模需后处理;
TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style. In CVPR, 2020.
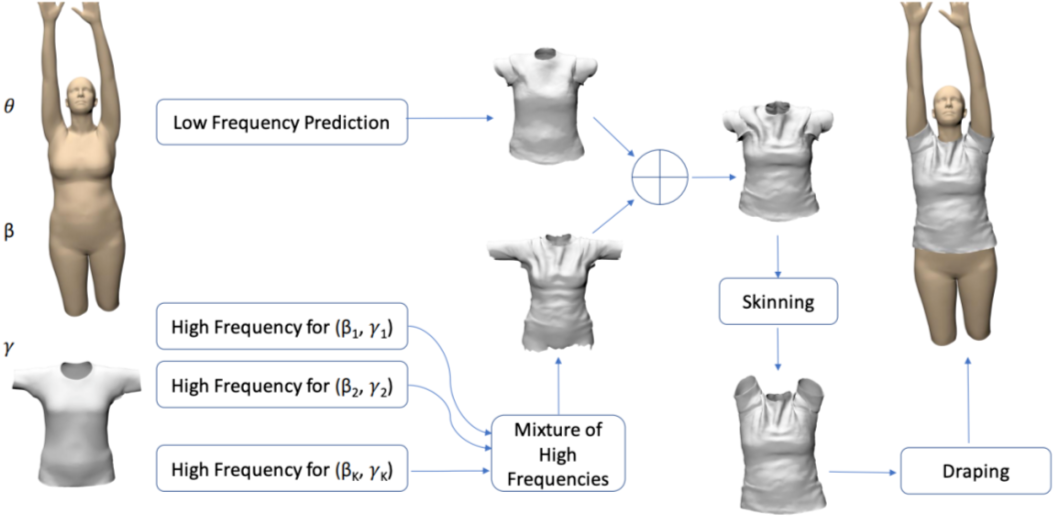
-
思路:将衣服形变分为高频和低频,低频部分用网络估计大致形变,高频部分估计多个特定 style-shape 模型,每个模型负责估计特定形变及加权权重; -
优势:可以得到较为细致的衣服褶皱;提出合成数据集,仿真 20 件衣服,1782 个 pose 和 9 种 shape; -
问题:在不同 shape 和 style 上训练得到结果过于平滑,不够真实;
BCNet: Learning Body and Cloth Shape from A Single Image. In ECCV, 2020.
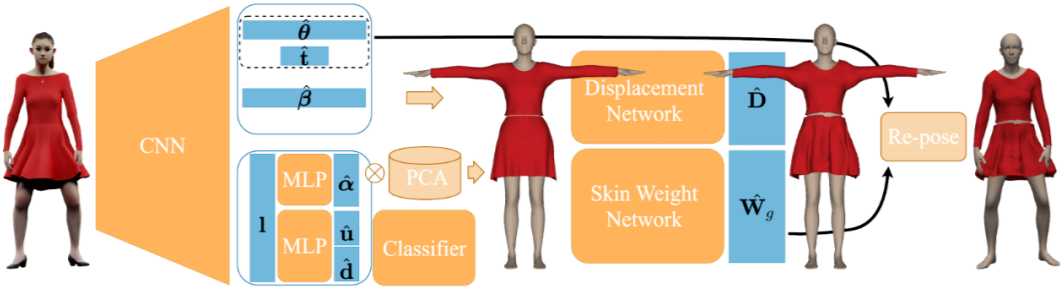
-
思路:基于单张图像估计 SMPL 参数和上下身的 Garment 参数,用两个网络分别估计 displacement 和 skining weight; -
优势:对 garment 学习蒙皮权重,动起来可以更自然;garment mesh 与 body mesh 不绑定,可以重建更多衣服类别; -
问题:将衣服分为上下半身,对连衣裙和长款不友好;
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images. In ECCV, 2020.

贡献:提出 Deep Fashion3D 数据集,包括 2000 件衣服,10 种类型,标记相应点云,多视角图像,3D body pose,和 feature lines;
思路:提出基于单张图像的 3D 衣服重建,通过估计衣服类型,body pose,feature lines 对 adaptable template 进行形变;
优势:衣服类型、feature line 估计可以提供更多 deformation 先验;引入 implicit surface 重建更精细;
-
问题:当衣服类型与 adaptable template 差距较大时,handle-based Laplcacian deformation 优化较难;

人体动作驱动


总结

参考文献
[1] Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR, 2019.
[2] DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In CVPR, 2019.
[3] SMPL: A Skinned Multi-Person Linear Model. In SIGGRAPH Asia, 2015.
[4] Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. In CVPR, 2019.
[5] SoftSMPL: Data-driven Modeling of Nonlinear Soft-tissue Dynamics for Parametric Humans. In Eurographics, 2020.
[6] STAR: Sparse Trained Articulated Human Body Regressor. ECCV, 2020.
[7] BLSM: A Bone-Level Skinned Model of the Human Mesh. ECCV, 2020.
[8] GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models. CVPR (Oral), 2020.
[9] 3D Human Motion Editing and Synthesis: A Survey. In CMMM, 2020.
[10] MoSh: Motion and Shape Capture from Sparse Markers. In SIGGRAPH Asia, 2014.
[11] Phase-Functioned Neural Networks for Character Control. In SIGGRAPH, 2017.
[12] Dancing to Music Neural Information Processing Systems. In NeurIPS, 2019.
[13] Robust Motion In-betweening. In SIGGRAPH, 2020.
[14] Human Motion Prediction via Spatio-Temporal Inpainting. In ICCV, 2019.
[15] DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills. In SIGGRAPH 2018.
[16] RigNet: Neural Rigging for Articulated Characters. In SIGGRAPH, 2020.
[17] Skeleton-Aware Networks for Deep Motion Retargeting. In SIGGRAPH, 2020.
[18] Motion Retargetting based on Dilated Convolutions and Skeleton-specific Loss Functions. In Eurographics, 2020.
[19] Dense Pose Transfer. In ECCV, 2018.
[20] Everybody Dance Now. In ICCV, 2019.
[21] Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis. In ICCV, 2019.
[22] [Few-shot Video-to-Video Synthesis. In NeurIPS 2019.
[23] TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting. In CVPR, 2020.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






