

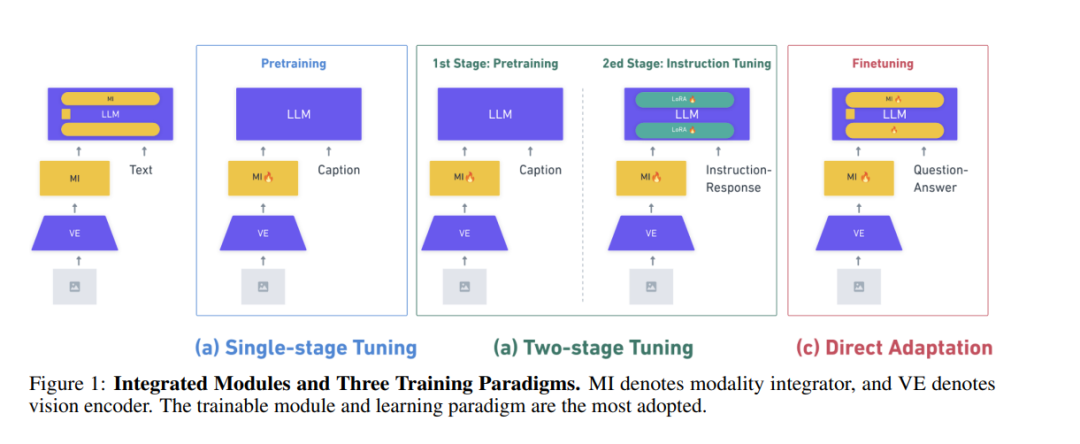
视觉-语言模态的集成一直是多模态学习的一个重要研究方向,传统上依赖于视觉-语言预训练模型。然而,随着大语言模型(LLMs)的出现,越来越多的研究开始关注将LLMs与视觉模态相结合。随之而来的是将视觉模态融入LLMs的训练范式的演变。最初,集成模态的方法是通过预训练模态集成器来实现,称为单阶段微调(Single-stage Tuning)。此后,这一方法逐渐分化为两种主要的研究方向:一是专注于性能提升的二阶段微调(Two-stage Tuning),二是优先考虑参数效率的直接适应(Direct Adaptation)。然而,现有的综述主要集中在最新的视觉大语言模型(VLLMs)与二阶段微调方法上,缺乏对训练范式演变及其独特的参数效率考虑的深入理解。 本文对34篇来自顶级会议、期刊和高引用的Arxiv论文中的VLLM进行了分类和综述,重点从训练范式角度讨论在适应过程中的参数效率。我们首先介绍LLMs的架构和参数效率学习方法,接着讨论视觉编码器和模态集成器的全面分类。然后,我们回顾了三种训练范式及其效率考量,并总结了VLLM领域的基准测试。为了更深入了解它们在参数效率上的效果,我们比较并讨论了具有代表性的模型的实验结果,其中包括复制直接适应范式的实验。通过提供对近期发展的见解以及实际应用的参考,本综述为研究人员和从业人员在高效集成视觉模态到LLMs中的探索提供了重要指导。 关键词: 多模态 · 大语言模型 · 视觉-语言模型 · 参数效率学习 · 指令微调 · 强化学习

成为VIP会员查看完整内容
相关内容

大语言模型是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。参数量的提升使得模型能够更加精细地捕捉人类语言微妙之处,更加深入地理解人类语言的复杂性。在过去的一年里,大语言模型在吸纳新知识、分解复杂任务以及图文对齐等多方面都有显著提升。随着技术的不断成熟,它将不断拓展其应用范围,为人类提供更加智能化和个性化的服务,进一步改善人们的生活和生产方式。
Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日