

Prompt工程是一种技术,涉及用任务特定的提示,即prompts,增强大型预训练模型,以使模型适应新任务。提示可以作为自然语言指令手动创建,或者作为自然语言指令或向量表示自动生成。Prompt工程使得基于提示进行预测成为可能,而不更新模型参数,也更容易地将大型预训练模型应用于实际任务中。在过去的几年里,Prompt工程在自然语言处理中得到了深入研究。近期,它在视觉-语言建模中也得到了深入的研究。然而,目前缺乏对预训练视觉-语言模型上的Prompt工程的系统性概述。本文旨在为视觉-语言模型上的Prompt工程提供一个全面的调查,涉及三种类型的视觉-语言模型:多模态到文本生成模型(例如Flamingo)、图像-文本匹配模型(例如CLIP)和文本到图像生成模型(例如Stable Diffusion)。对于每一种模型,我们都总结并讨论了简短的模型摘要、提示方法、基于提示的应用以及相应的责任和完整性问题。此外,还讨论了在视觉-语言模型、语言模型和视觉模型上进行提示的共性和差异性。最后,总结了这一话题的挑战、未来方向和研究机会,以促进未来的研究。
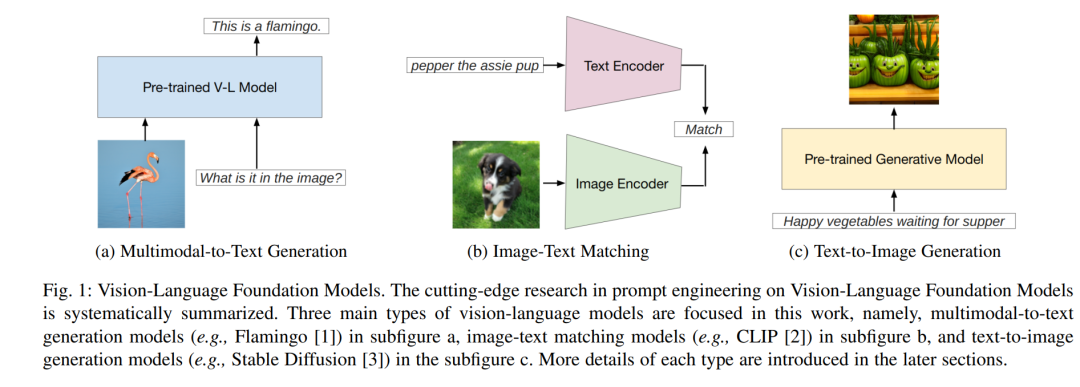
Prompt工程是一种方法,通过用任务特定的提示增强模型输入,将大型预训练模型(也称为基础模型)适应新任务。具体而言,模型的输入被增加了一个额外的部分,称为提示,这可以是手动创建的自然语言指示[4]、自动生成的自然语言指示[5],或自动生成的向量表示[6]。自然语言指令也被称为离散提示或硬提示,而向量表示被称为连续提示或软提示。Prompt工程实际上与大型预训练模型的出现同时出现,并因此而变得突出,这两者一起导致了机器学习(ML)的范式转变。传统的范式要求标记大量的数据,然后从头开始训练一个特定任务的ML模型或对预训练的大型模型进行微调。模型的性能在很大程度上依赖于标记数据的质量和数量,这可能需要大量的资源来获取。此外,传统范式需要在某种程度上调整模型的参数,即在从头开始训练ML模型或完全微调预训练模型的情况下的所有参数,或在参数高效微调的情况下的部分参数。这限制了ML模型的可扩展性,并要求每个任务都有一个特定的模型副本。最近,提示预训练的大型模型使其适应特定任务已成为一种新趋势。Prompt工程的关键思想是提供提示并与输入一起,引导预训练模型使用其现有知识解决新任务。如果提示是人类可解释的自然语言(硬提示),相关的研究被称为InContext Learning[7],它使模型能够从任务指示、用少数示例的示范或上下文中的支持信息中学习。此外,提示也可以是连续的向量表示(软提示)。相关的工作被称为Prompt-Tuning[6],它直接在模型的嵌入空间中优化提示。 在本文中,我们的目标是通过提供关于预训练VLMs的Prompt工程的前沿研究的全面调查,来弥补这一缺口。具体来说,我们根据模板的可读性将提示方法分类为两个主要类别,即硬提示和软提示。硬提示可以进一步划分为四个子类,即任务指示、上下文学习、基于检索的提示和思维链提示。另一方面,软提示是可以使用基于梯度的方法进行微调的连续向量。请注意,这项调查主要关注保持模型架构的提示方法,因此,如P-tuning[13]和LoRa[14]这样将额外模块引入模型的方法并不是这项调查的主要范围。我们研究了三种类型的VL模型上的Prompt工程,分别是多模态到文本生成模型、图像文本匹配模型和文本到图像生成模型。每种模型类型的明确定义在Sec. 2.1中提供。此外,我们从编码器-解码器的角度分类现有的Prompt工程方法,如图1所示,即编码端提示或解码端提示,其中提示分别添加到编码器和解码器。本文的其余部分组织如下。在Sec. 2中,我们总结并定义了我们在此调查中使用的分类和符号。Sec. 3、4和5介绍了多模态到文本生成模型、图像-文本匹配模型和文本到图像生成模型上Prompt工程的当前进展,每一节首先介绍相应模型的初步情况,然后详细讨论提示方法,再研究这些提示方法的应用和负责任的AI考虑因素。Sec. 6提供了提示单模态模型和VLMs之间的比较,并对它们的相似之处和差异进行了深入讨论。最后,在Sec. 7中,我们强调了挑战和潜在的研究方向。为了方便文献搜索,我们还建立并发布了一个项目页面,其中列出了与我们主题相关的论文并进行了组织。
多模态-文本提示方法
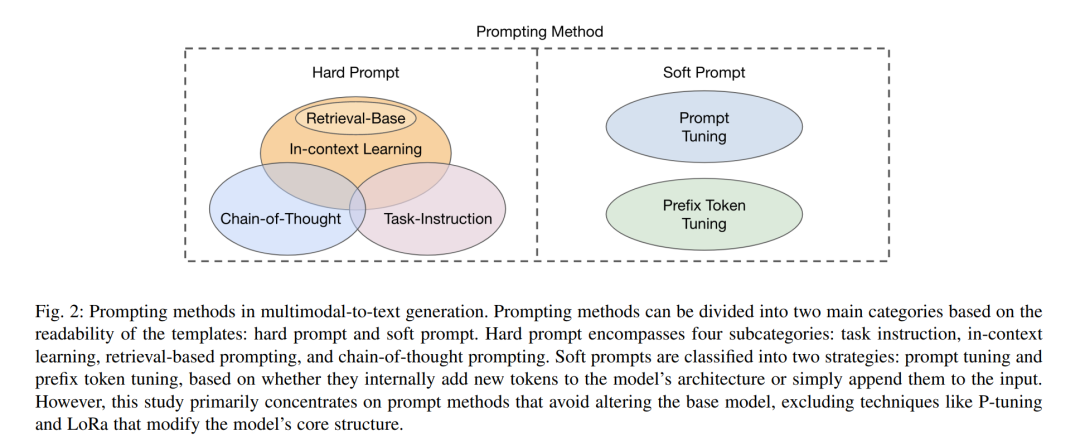
图2展示了提示方法的分类。提示方法分为两类:硬提示,它们是劳动密集型的、手工制作的文本提示,带有离散的标记;而软提示是可优化的、可学习的张量,与输入嵌入连接在一起,但由于与真实词嵌入不对齐,所以缺乏人类可读性。
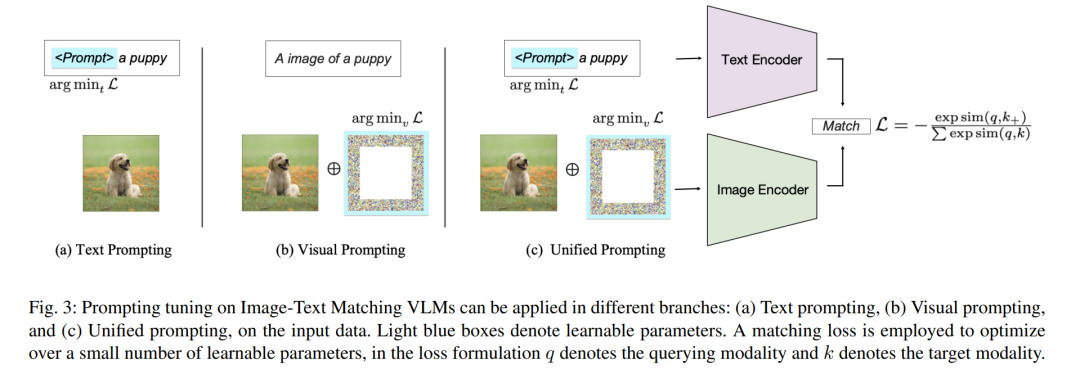
在图像-文本匹配中的提示模型
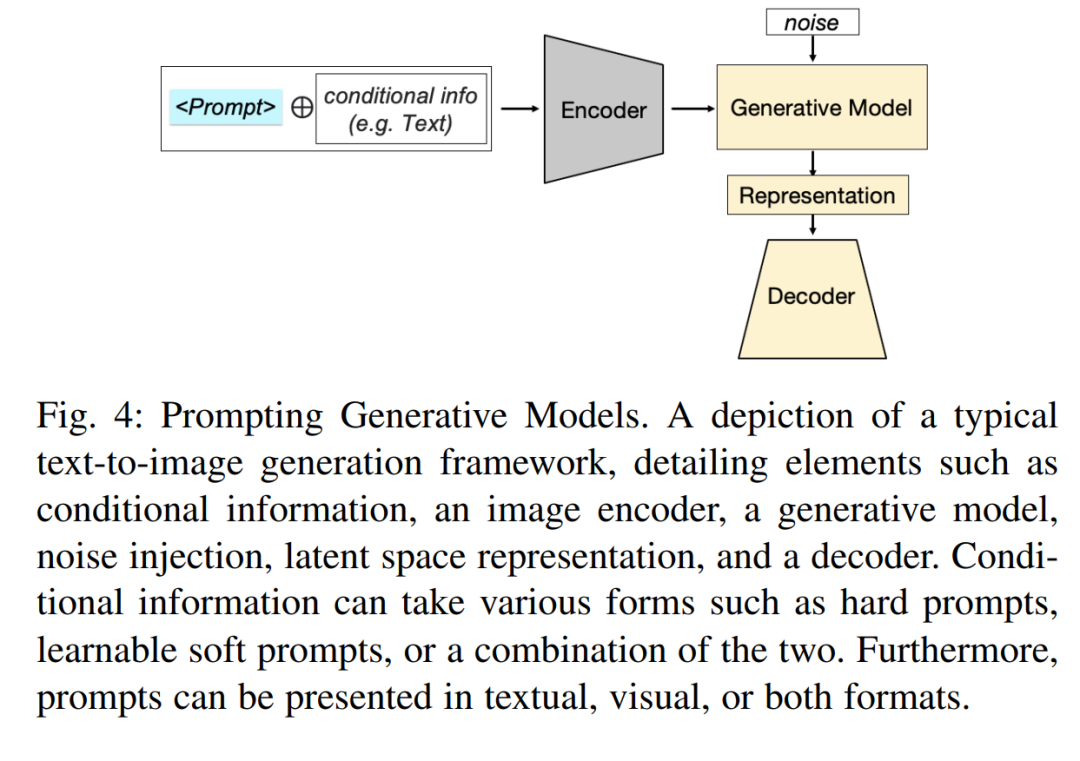
在文本-图像生成中的提示模型
结论
这篇关于预训练视觉语言模型的提示工程的调查论文为这个领域的当前研究状况提供了宝贵的见解。通过分析确定的主要发现和趋势揭示了在适应视觉语言任务中有效使用提示来调整大型预训练模型的方法。一个关键的发现是提示工程在不同类型的视觉语言模型上的多功能性和适用性,包括多模态到文本生成模型、图像-文本匹配模型和文本到图像生成模型。此调查从它们各自的特点探讨了每种模型类型,强调了在它们上的各种提示方法。这些发现对学术界和工业界都有重要意义。通过利用提示工程技术,研究人员可以在视觉语言模型中获得显著的性能提升,而不需要大量的标记数据。这有可能减少数据注释的负担并加速视觉语言模型在实际应用中的部署。然而,重要的是要承认这次调查的局限性。该领域迅速发展的性质和现有的广泛提示工程方法使得提供一个详尽的概述变得具有挑战性。此外,调查主要从提示工程的角度关注预训练的视觉语言模型,并可能没有涵盖其他相关领域的所有最新进展。为了解决这些局限性,我们将维护并发布一个平台来持续跟踪这一领域的进展。进一步的研究应探讨提示工程技术与其他新兴技术,如强化学习或元学习,的集成,以提高视觉语言模型的性能和泛化能力。此外,研究提示工程模型的可解释性和鲁棒性对于确保其在实际部署和伦理使用中的关键。总的来说,这项调查为现有的知识体系做出了贡献,为预训练视觉语言模型中的提示工程提供了一个全面的概述。通过阐明提示工程技术的当前状况、关键趋势和影响,这项调查为那些希望利用视觉语言模型进行各种应用的研究者和从业者提供了宝贵的资源。它在研究中填补了一个空白,为预训练模型在视觉和语言的背景下的适应提供了见解,为这一令人兴奋的领域的进一步进展铺平了道路。

