

在过去的二十年里,物联网(IoT)是一个变革性的概念,而随着 2030 年的临近,一种被称为感官互联网(IoS)的新模式正在兴起。与传统的虚拟现实(VR)不同,IoS 试图提供多感官体验,承认在我们的物理现实中,我们的感知远远超出了视觉和听觉;它包括一系列感官。本文探讨了推动身临其境的多感官媒体的现有技术,深入研究了它们的功能和潜在应用。这种探索包括对传统的沉浸式媒体流和利用生成式人工智能(AI)的语义通信的建议用例进行比较分析。这项分析的重点是,在拟议的方案中,带宽消耗大幅减少了 99.93%。通过比较,旨在强调生成式人工智能在沉浸式媒体中的实际应用,同时应对挑战并勾勒出未来的发展轨迹。
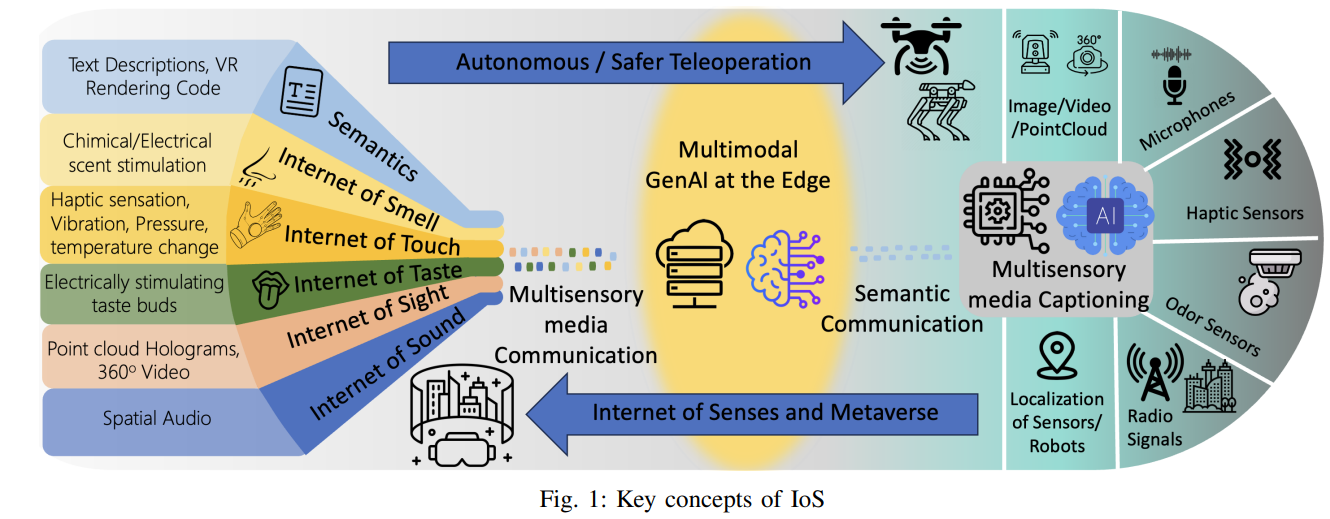
第五代(5G)移动网络的出现和最近计算技术的进步重新定义了互联网的概念,从基本的连接到更先进的数字体验,从仅仅是更快的通信过渡到与数字领域的沉浸式互动。这一概念最近在元宇宙(Metaverse)和数字孪生(digital twins)的框架下被引入,并开辟了广泛的应用领域,包括虚拟现实(VR)、增强现实(AR)、全息传送(holoportation)和远程操作(tele-operation)等。在这一领域,有四个主要基础被认为是连接网络和物理世界的范例,即互联智能机器、数字化可编程世界、互联可持续世界和感知互联网(IoS)[1]。IoS 概念将通过创建一个超越传统界限的完全沉浸式环境,彻底改变数字交互方式。通过将视觉、听觉、触觉、嗅觉和味觉等感官体验整合到数字领域,这项技术有望打造一个更引人入胜的网络世界,让虚拟体验与物理世界一样丰富和多维。
人类通过不同的感官体验世界,感知大脑中整合或分离的感官信号。如果这些感官,特别是触觉反馈,能够准确地与现实世界保持一致,就能对行动和行为(如反应时间和探测)产生积极影响[2]。在此背景下,物联网技术将使人们能够远程体验各种感觉,为工业、医疗保健、网络、教育和旅游等各种垂直领域带来革命性的变化。为了充分发挥物联网技术的潜力,需要应对众多挑战,以实现完全身临其境的多感官体验。这些挑战涉及多种媒体的时间同步、解决晕动症、确保高吞吐量以及最大限度地减少端到端(E2E)延迟。从视觉、听觉和触觉等各种传感器模式收集数据在打造多感官体验中起着至关重要的作用,这些数据可以在源端或目的端(即终端设备或边缘服务器)同步。虚拟体验无法真正复制我们的感官,会给人类大脑带来混乱,导致恶心、头晕和偏头痛等症状。为了减少这些弊端,关键是要增强虚拟感觉的真实性,减少 VR/AR 设备的延迟,从而最大限度地减少不同模式之间的延迟,避免其不匹配[3]。此外,为了在长达一英里的距离内实现精确控制,并防止出现晕动症,必须以极低的 E2E 延迟(理想情况下为 1-10 毫秒)传输感官信息[4]。
关于物联网中沉浸式媒体可靠通信的关键性能指标(KPI),有研究表明,未来的 6G 网络应实现高质量视频流和触觉信号 1 毫秒范围内的 E2E 延迟性能,数据速率要求从几十 Mbps 到 1 Tbps,可靠性能达到 10^-7[5]。此外,虽然味觉和嗅觉信号的要求没有视频和触觉信号那么严格,但要充分发挥物联网系统的潜力,就必须实现不同感官信号之间的完美同步。在各种技术中,语义通信是有希望实现超低延迟通信的候选技术,它通过通信传输信息的含义/语义,而不是通信整个信号,从而实现更快、带宽更高效的传输。
作为先进的人工智能(AI)系统,人工智能的一个子领域--大语言模型(LLMs)最近被认为是超级压缩器,它能够用较小的信息(提示)提取出要传达的基本信息[6]。LLM 是一种深度神经网络(DNN),拥有超过十亿个参数,通常达到数百亿甚至数千亿个,并在广泛的自然语言数据集上进行过训练。这种全面的参数化使其在生成、推理和泛化方面的能力达到了传统 DNN 模型无法企及的水平[7]。虽然 LLM 恢复的信息与原始信息并不完全相同,但它们能充分代表信息的含义并传达预期的信息。
因此,人们设想 LLM 将发展成为 IoS 的认知中心,通过对部分模式的估计和语义理解实现的通信,解决同步和压缩等复杂挑战。此外,如图 1 所示,通过管理与用户和环境感官相关的各种数据模态,LLM 可增强机器控制智能,从而提高远程操作的可靠性。
在最近的发展中,LLM 已经发展到可以处理文本以外的各种模式,包括音频、图像和视频。由此产生的多模态大语言模型(MLLMs)可以利用多种数据模态来模拟类似人类的感知,将视觉和听觉等感官整合在一起[8]。多模态大语言模型能够解释和响应更广泛的人类交流,促进更自然、更直观的交互,包括图像-文本理解(如 BLIP-2)、视频-文本理解(如 LLaMA-VID)和音频-文本理解(如 QwenAudio)。最近,MLLMs 的开发旨在实现任意多模态理解和生成(如 VisualChatGPT)。
在本文中,我们旨在为 LLM 与 IoS 技术的整合做好铺垫,通过开发案例研究来展示利用 LLM 的能力来提高沉浸式媒体通信的延迟性能所能带来的好处。特别是,我们将无人飞行器(UAV)的 360◦ 视频流视为一项语义通信任务。首先,我们采用对象检测和图像-文本字幕技术,从输入的 360◦ 帧中提取语义信息(文本)。随后,生成的文本信息被传输到边缘服务器。在边缘服务器中,利用 LLM 生成与 A-frame 兼容的代码,以便通过头戴式设备(HMD)上的三维(3D)虚拟对象显示相应的图像。最后,生成的代码被发送到接收器,以便在 HMD 上直接呈现三维虚拟内容。
本文的贡献概述如下:
-
将无人机 360◦ 视频流概念化为语义通信框架。
-
利用图像到文本字幕模型和生成式预训练变换器(GPT)解码器(仅 LLM)的强大功能,生成适合在用户 HMD 上显示的 A 帧代码。
-
根据语义通信框架各组成部分的带宽消耗和通信延迟,对拟议框架进行基准测试。
-
使用反向图像到文本的方法,评估系统生成的 3D 物体与捕获的 360◦ 视频图像相比的质量,然后通过 BERT 模型进行文本比较。
本文的其余部分安排如下。第二节介绍 IoS 并讨论其必要性。第三节概述了 MLLM 的发展及其在 IoS 中的应用。第四节介绍了一个案例研究,其中包括一个拟议的测试平台,并对其进行了实施和分析。最后,第七节强调了面临的挑战,并提出了未来的研究方向。
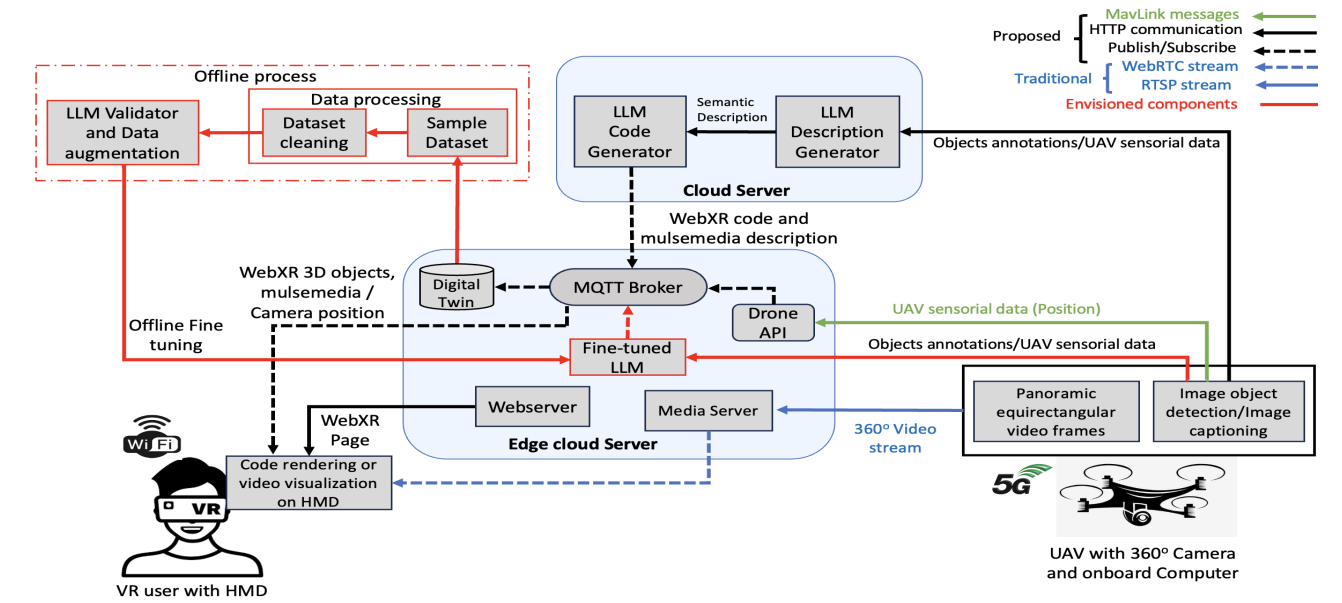
图 2:支持 GenAI 的沉浸式通信拟议架构

