

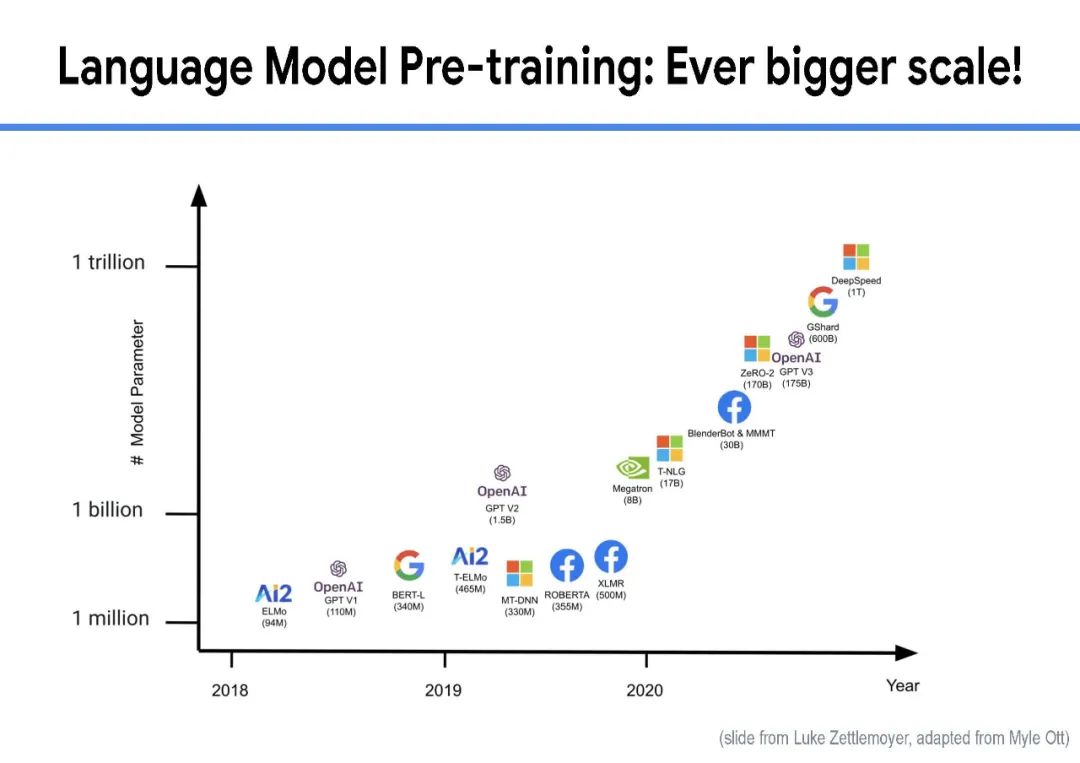
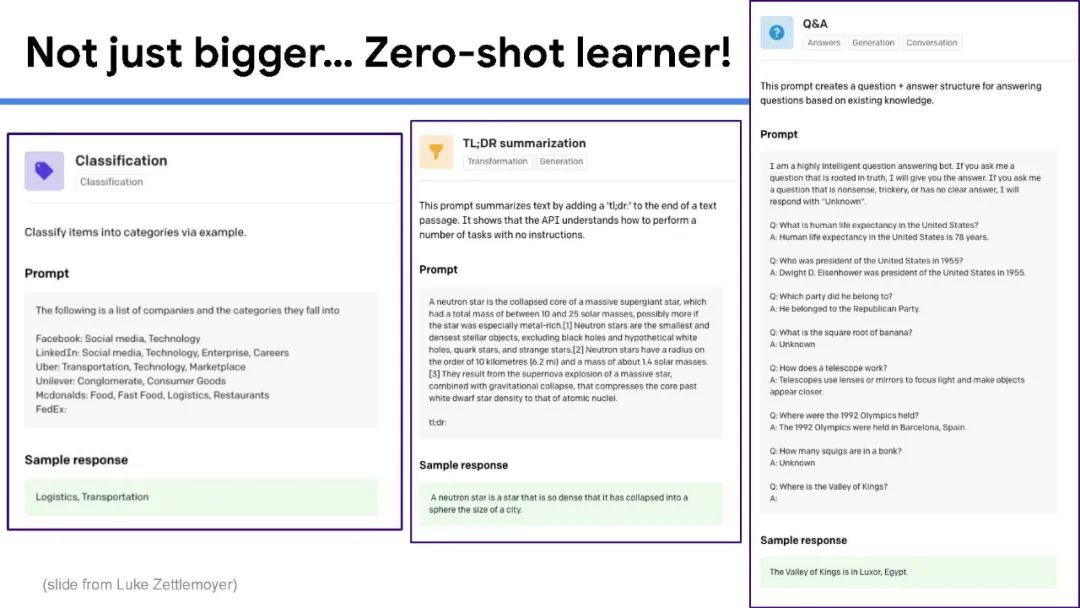
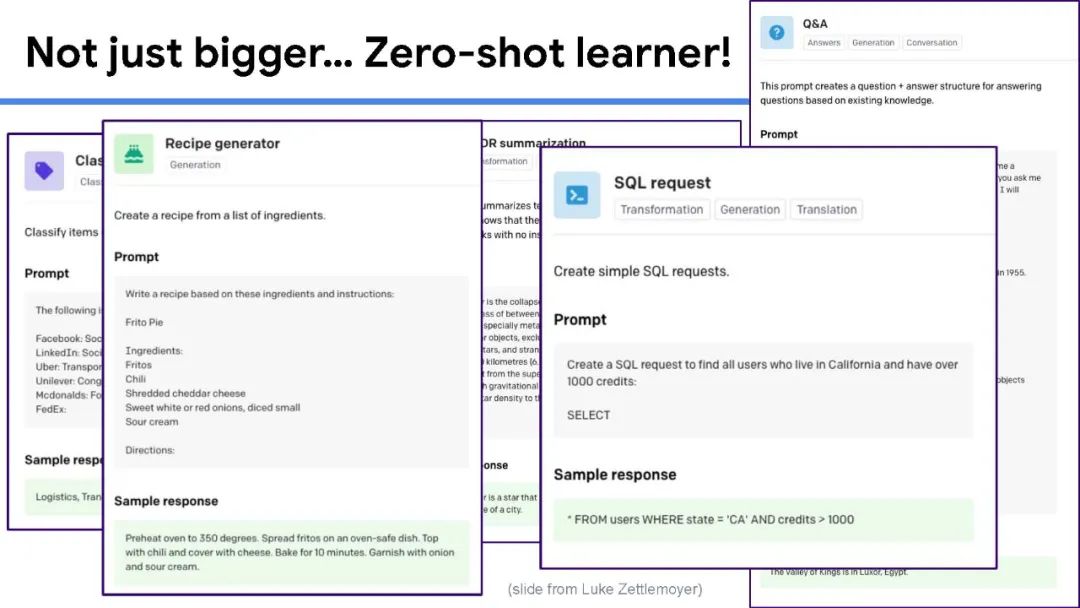
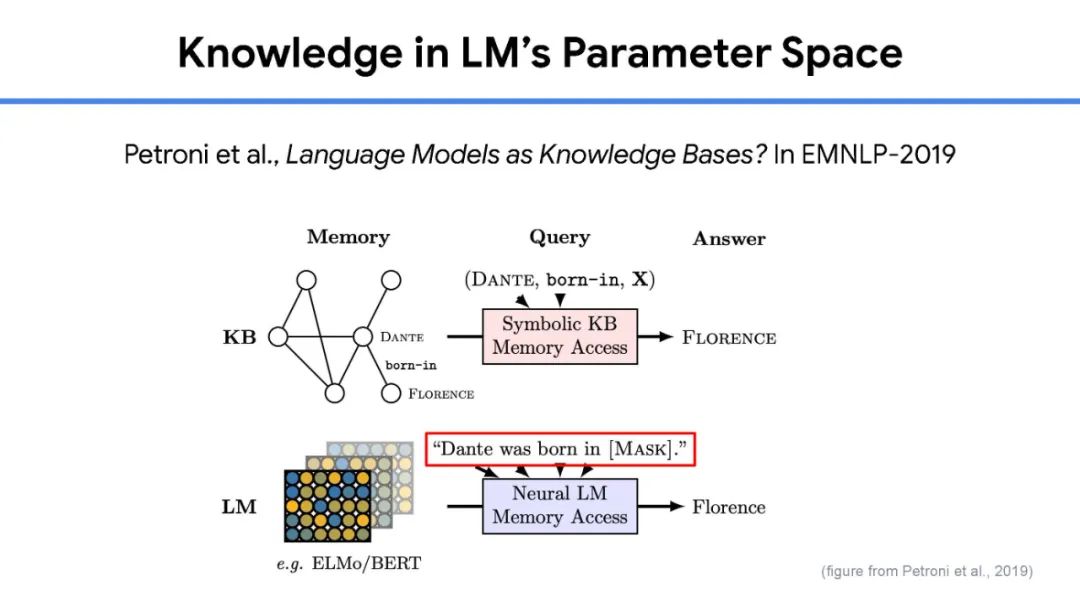
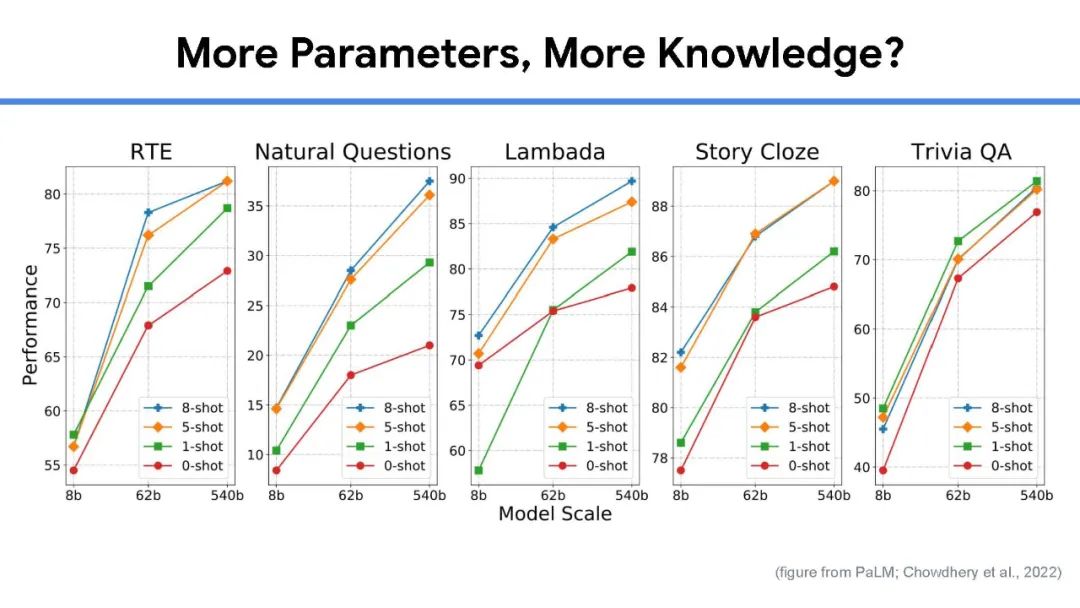
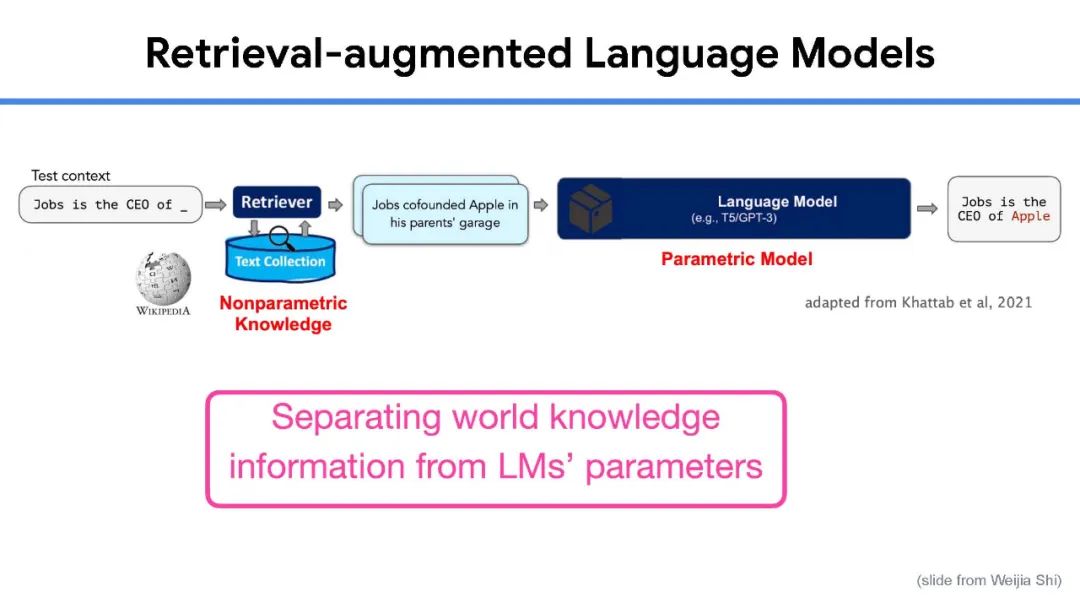
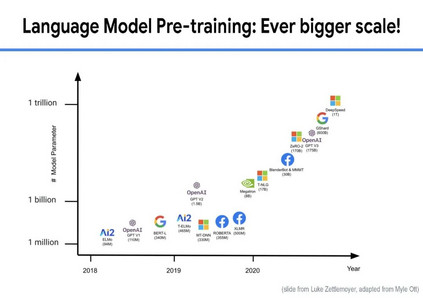
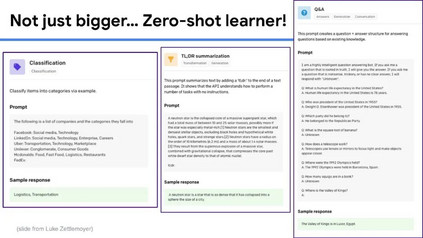
虽然大规模语言模型工作得非常好,但训练它们的成本很高,很难解释它们的预测,而且几乎不可能随着时间的推移保持最新。目前还不清楚我们什么时候可以相信他们的预测,而且目前的大型语言模型都不能回答关于当前主题的问题,例如COVID-19,因为用于训练的语料库是几年前创建的。为了开发具有更小、更简单和更有效的模型的下一代通用语言模型,我们相信信息检索是一个关键组件。在人与人之间以及与世界进行交互时,人类会挖掘许多不同形式的知识,包括世界知识(例如常识、最新的世界事实、热门新闻)和用户知识(例如对话记忆、社交互动、额外的上下文(例如位置等)。为了在AI应用程序中结合这种能力,信息检索提供了模型对可能包含此类知识的文档集合的访问(可能很大)。具体来说,完整的系统由一个小型的核心模型组成,可以通过检索轻松访问额外的、与任务相关的知识,并与当今最大的语言模型相媲美。在本次演讲中,我将首先对检索增强语言模型进行研究概述。然后,我将分享我们最近的一些工作,包括一个通过添加检索组件来改进任何语言模型的通用框架,以及一个检索增强的多模态模型,该模型可以生成质量更好的图像和标题。最后,我将通过讨论我们学到的一些经验教训和我们计划在不久的将来解决的问题来结束这次演讲。



成为VIP会员查看完整内容





相关内容
Arxiv
0+阅读 · 2023年4月5日
Arxiv
0+阅读 · 2023年4月3日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年4月5日
Arxiv
0+阅读 · 2023年4月3日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日