
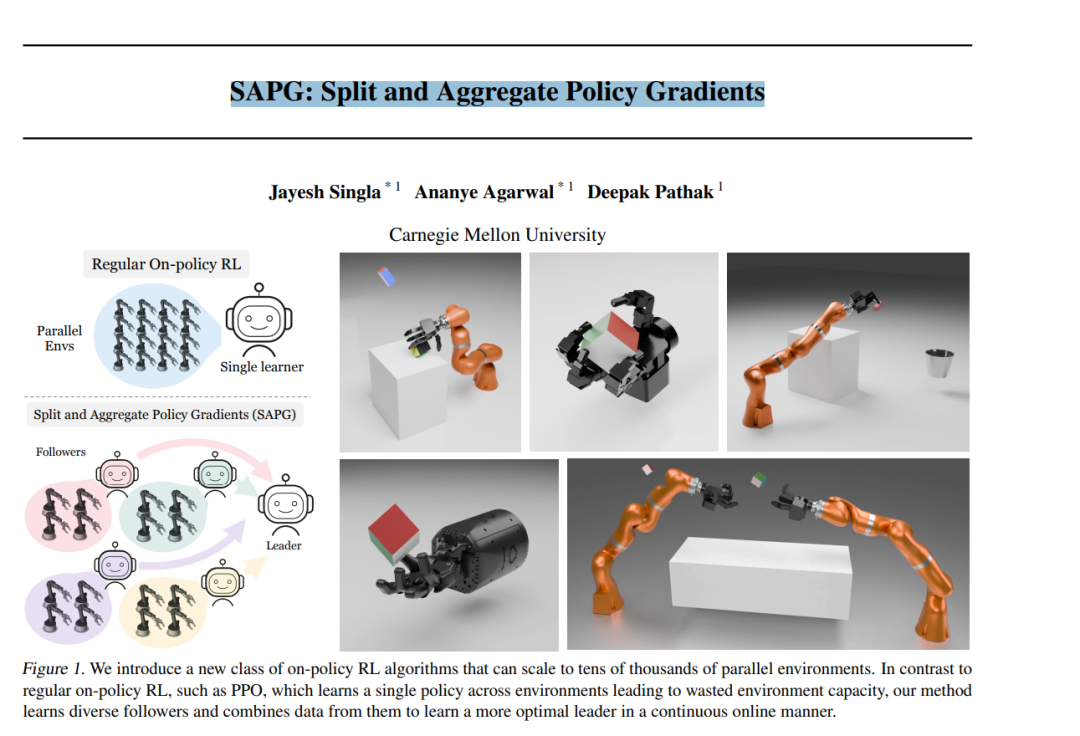
尽管极度样本效率低下,但基于策略的强化学习(即策略梯度)已成为解决决策问题的基本工具。随着基于GPU的模拟技术的最新进展,收集大量用于强化学习训练的数据的能力呈指数级增长。然而,我们展示了当前的强化学习方法(例如PPO)在并行环境的利用方面存在瓶颈,其性能在达到一定点后会饱和。为了解决这个问题,我们提出了一种新的基于策略的强化学习算法,能够通过将大规模环境分块并通过重要性采样将它们融合回去,来有效利用这些环境。我们称这种算法为SAPG。SAPG在各种具有挑战性的环境中表现出显著更高的性能,而在这些环境中,传统的PPO和其他强基线方法未能达到高性能表现。更多信息请访问:https://sapg-rl.github.io。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日