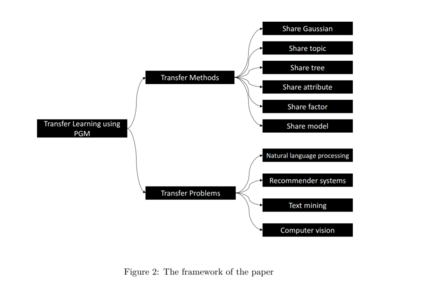
摘要
迁移学习是指从源领域提取可迁移知识并将其重用到目标领域的行为,已成为人工智能领域的研究热点。概率图模型(PGMs)作为一种建模复杂系统的强大工具,具有处理不确定性的能力和良好的可解释性。考虑到上述两个研究领域的成功,将PGMs应用于迁移学习似乎是很自然的。然而,尽管在文献中已经有一些优秀的迁移学习特异性PGMs,但PGMs在这一问题上的潜力仍然被严重低估。本文旨在通过以下几个方面促进迁移学习的知识迁移模型的发展:1)考察迁移学习的知识迁移模型的试点研究,即分析和总结现有的专门设计的知识迁移机制;2)讨论现有PGM成功应用于实际迁移问题的例子;3)利用PGM探讨迁移学习的几个潜在研究方向。
引言
迁移学习是从源领域中提取可迁移的知识,并在目标领域中重用该知识的行为,这是一种自然的人类现象,即使对于非常小的儿童(Brown & Kane, 1988)。形式定义如下(Pan & Yang, 2010):“给定源域DS = {XS, PS(X)}和目标域DT = {XT, PT (X)},迁移学习的目的是借助DS改进DT中的学习任务,其中X为特征空间,P(X)为数据分布。”当XS = XT时,为同质迁移学习;当XS= XT时,为异质迁移学习。需要注意的是,迁移学习可以被看作是前面提到的问题,也可以看作是解决这个问题的方法。一个经典的激励例子是产品评论的跨领域(如电影和计算机领域) 情感预测: 1) 在电影领域有大量的标签产品评论,因此可以训练一个分类器,并应用于该领域的预测; 2)新计算机的评论标签不足以训练分类器进行进一步的情感预测; 3) 一个简单的想法是直接来自电影领域的分类器应用到新电脑领域考虑两个域之间的相似之处(例如,人们倾向于使用类似的词语来表达他们的喜欢或不喜欢在不同的产品), 但它并不总是工作很可能导致负迁移(Weiss, Khoshgoftaar, & Wang, 2016). 因为它们在不同的上下文中存在差异(例如,在电影领域中,“触摸我的心”是褒义词,而在计算机领域中,“触摸板”是中义词)。如何结合源域和目标域提取可迁移知识是迁移学习的艺术。在文献中,有几个与迁移学习密切相关的概念误导了读者,如样本选择偏差、协变量转移、类别不平衡、领域适应和多任务学习。(Pan & Yang, 2010)的研究试图根据源域和目标域的设置来区分和组织它们,例如目标域中是否有标记数据。本文并没有明确区分它们,但我们认为它们都是迁移学习。对这些概念及其区别的进一步讨论可以在(Pan & Yang, 2010;Weiss et al., 2016)。识别、建模和利用两个领域之间可迁移的知识的能力不仅提高了具体现实问题的性能,而且在促进机器人在没有任何人类干预的情况下的自学习(像人类)方面迈出了重要的一步。想象一下这样的场景:一个智能机器人面临一个自己没有知识的新问题,它向其他类似领域的机器人寻求帮助,并向他们学习,问题就解决了。因此,我们认为迁移学习不仅在统计机器学习领域,而且在机器人甚至一般人工智能领域都有很好的前景。
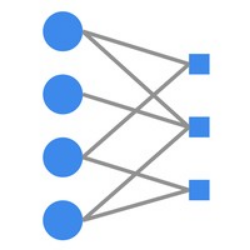
概率图模型(PGM) (Wainwright, Jordan等,2008;Koller & Friedman, 2009)是统计机器学习的一个重要分支,它是一个丰富的框架,用于通过概率分布或随机过程来建模(表达)来自领域的有限或无限个(可观察或潜在)变量之间的复杂交互作用。它的名字来自于它的结构——一个以随机变量为节点,以概率相关性为边的图,如图1所示。根据节点/变量之间的边缘类型(即有向或无向),概率图模型分为有向和无向两类。例如,隐马尔可夫模型(Rabiner, 1989)是一种有向图模型; 条件随机场(Lafferty, McCallum, & Pereira, 2001)是无向图模型的一个例子。将概率图模型应用于目标任务包括以下两个步骤: 1)模型设计和 2)模型推理。给定一个任务,第一步是分析问题的本质,然后设计一些变量及其关系来捕捉这种本质。换句话说,这一步是设计PGM的图结构,该结构应共同考虑观测数据和目标任务的附加知识。请注意,这个步骤没有确切的过程,因为它严重依赖于处理同一问题的不同人员的视图/理解。例如,在Latent Dirichlet Allocation模型(Blei, Ng, & Jordan, 2003)中,文档由满足Dirichlet或多项分布的随机变量建模,变量之间通过Dirichlet-多项关系连接;在Gamma-Poisson模型(Ogura, Amano, & Kondo, 2013)中,文档由满足Gamma或Poisson分布的随机变量建模,变量之间通过Gamma-Poisson关系连接。在不考虑具体任务的情况下,讨论优点和缺点通常是困难和毫无意义的。PGM的输出是给定观测数据的图模型定义的感兴趣的边际或关节后验分布。另外,从第一步开始的PGM实际上是一组模型,因为所设计的概率分布通常带有未知的参数,不同的参数设置会导致不同的模型。有了观测数据(图模型中的一些变量/节点的值是已知的),第二步是推断潜在变量的后验分布,并估计模型参数。对于一些稀疏图,有一个精确的算法来学习PGM: 结点树算法(Paskin & Lawrence, 2003; Wainwright et al., 2008)。但该算法不适用于任务复杂的复杂图模型。因此,一些近似算法被发展来解决这个问题:期望最大化(Dempster, Laird, & Rubin, 1977),拉普拉斯近似,期望传播(Minka, 2001),蒙特卡洛马尔可夫链(Neal, 1993),变分推理(Blei, Kucukelbir, & McAuliffe, 2017)。此外,设计的变量之间的概率相关性也可能不是固定的,而是从数据中学习的(所谓结构学习)。一个例子是贝叶斯网络,其中的网络结构(即变量之间的依赖关系)可以从数据中学习。由于其强大的建模能力和坚实的理论基础,概率图模型受到了分子生物学(Friedman, 2004)、文本挖掘(Blei et al., 2003)、自然语言处理(Sultan, Boyd-Graber, & Sumner, 2016) 和 计算机视觉(Gupta, Phung, & Venkatesh, 2012) 等多个领域研究者的关注。
与机器学习中的其他模型(如支持向量机)相比,概率图模型具有以下优点,这些优点可能有利于迁移学习: 1) 处理不确定性。不确定性几乎出现在任何现实世界的问题中,当然也出现在他们的观察(数据)中。例如,人们在编写关于特定主题的文档时可能会使用不同的词汇,所以我们在构建模型以揭示隐藏的主题时需要考虑这种不确定性。PGMs能够借助概率分布或随机过程很好地处理(模型)这种不确定性; 2) 处理缺失数据。丢失数据的一个典型例子是来自推荐系统,用户只对有限数量的项目进行评级,因此对其他项目的评级也会丢失。PGM可以通过潜在变量设计很好地处理这一问题(Mohan, Pearl, & Tian, 2013); 3) 可解释性。PGM由定义的概率分布(或随机过程)组成,因此人类专家可以评估其语义和属性,甚至将他们的知识纳入模型。通过PGM的结构,人们可以很容易地理解问题和领域; 4) 泛化能力。定向PGMs(也称为生成模型)具有很好的泛化能力,可以比较鉴别模型,特别是在数据数量有限的情况下(Ng & Jordan, 2002)。尽管在文献中已经发表了一些关于迁移学习的优秀研究,如: 综合研究(Pan & Yang, 2010;Weiss et al., 2016),应用,如强化学习(Taylor & Stone, 2009),协同过滤(Li, 2011),视觉分类(Shao, Zhu, & Li, 2015),人脸和物体识别(Patel, Gopalan, Li, & Chellappa, 2015),语音和语言处理(Wang & Zheng, 2015),活动识别(Cook, Feuz, & Krishnan, 2013),和方法论,如计算智能(Lu, Behbood, Hao, Zuo, Xue, & Zhang, 2015),在使用PGMs进行迁移学习方面没有一个具体的工作。本文综述了该领域的主要研究成果,总结了已有的迁移研究的基本方法,为今后在该领域的进一步研究奠定了基础。本文对迁移学习领域的研究人员进行了综述,并对迁移学习方法的应用进行了推广。本文还综述了已有的迁移学习理论在迁移学习中的成功应用,并促进了迁移学习理论的发展。本文假设读者已经具备迁移学习的基本知识。
本文的其余部分结构如下。第2节讨论了现有的最先进的方法使用的概率图模型迁移学习。第3节介绍了现实世界中使用概率图模型解决的迁移学习问题。最后,第四部分对本文进行了总结,并提出了进一步研究可能面临的挑战。