

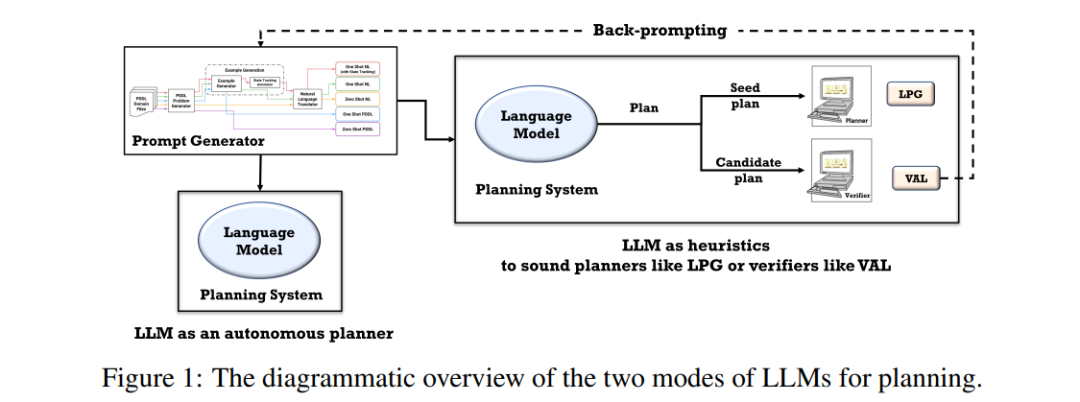
被大型语言模型(LLM)在通用网络语料库上培训所表现出来的新兴推理能力所吸引,我们在本文中着手研究了它们的规划能力。我们的目标是评估(1)LLM在常识性规划任务中自主生成规划的有效性;以及(2)LLM作为其他代理(AI规划器)在其规划任务中的启发性指导的潜力。我们通过生成一系列与国际规划竞赛中所用领域相似的实例进行了系统性的研究,并以两种不同的模式评估LLM:自主模式和启发式模式。我们的研究发现,LLM自主生成可执行规划的能力相当有限,最优模型(GPT-4)在各个领域的平均成功率约为12%。然而,启发式模式下的结果更加有前景。在启发式模式下,我们证明了LLM生成的规划能够改善底层健全规划器的搜索过程,并且还表明,外部验证器可以帮助对生成的规划提供反馈,并追溯提示LLM以更好地生成规划。
成为VIP会员查看完整内容
相关内容
专知会员服务
24+阅读 · 2019年11月20日
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日
Arxiv
83+阅读 · 2023年3月21日
相关主题

相关VIP内容
专知会员服务
24+阅读 · 2019年11月20日
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日
Arxiv
83+阅读 · 2023年3月21日