

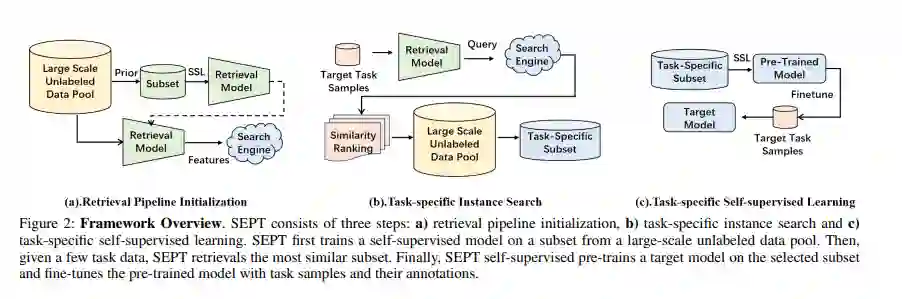
最近,自监督预训练范式在利用大规模无标记数据来提高下游任务性能方面显示出了巨大的潜力。然而,在现实场景中增加无标记预训练数据的规模,需要惊人的计算成本,并面临着未经策划的样本的挑战。为解决这些问题,本文从数据选择的角度构建了一个特定于任务的自监督预训练框架,基于一个简单的假设,对与目标任务分布相似的未标记样本进行预训练,可以带来实质性的性能提升。在该假设的支持下,通过引入数据选择的检索管道,提出了第一个可扩展和高效的视觉预训练(SEPT)的新框架。首先利用自监督预训练模型提取整个未标记数据集的特征,用于检索管道初始化;然后,针对特定的目标任务,基于每个目标实例的特征相似度,从无标记数据集中检索最相似的样本进行预训练;最后,使用选取的无标签样本对目标模型进行自监督预训练,实现目标数据微调。通过解耦预训练规模和目标任务的可用上游数据,SEPT实现了上游数据集的高可扩展性和预训练的高效性,从而实现了高模型架构灵活性。在各种下游任务上的结果表明,与ImageNet预训练相比,SEPT可以实现具有竞争力甚至更好的性能,同时将训练样本的大小减少一个量级,而不需要借助任何额外的注释。
成为VIP会员查看完整内容
相关内容
Arxiv
15+阅读 · 2020年2月28日

相关VIP内容
相关资讯