【速览】TNNLS 2022 | DualConv:用于轻量级深度神经网络的双卷积核
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
DualConv:用于轻量级深度神经网络的双卷积核
*通讯作者:陈俊颖(jychense@scut.edu.cn)
◆ ◆ ◆ ◆
卷积神经网络通常需要消耗大量的存储和计算资源,因此很难将其部署在嵌入式或移动设备中。本文提出一种高效简洁的新型并行卷积核(DualConv),采用分组卷积策略,在一组卷积滤波器(convolutional filter)中,对一组相同的输入特征映射图(feature map)通道同时做3×3卷积和1×1卷积,对其余通道仅做1×1卷积。DualConv能够在各种尺寸的卷积神经网络架构中部署,并可应用于图像分类、目标检测和语义分割等任务,与标准卷积核相比具有更低的计算量和参数量、以及不相上下的准确度。在CIFAR-10、CIFAR-100、ImageNet和PASCAL VOC等数据集上的大量实验结果表明,DualConv显著降低了深度神经网络的计算成本和参数量,同时在某些情况下获得比原始模型略高的精度。在CIFAR-100数据集上,DualConv能够将MobileNetV2的参数量减少54%且只有0.68%的准确度损失。而在不考虑神经网络计算量和参数量的情况下,DualConv能够将MobileNetV1在CIFAR-100数据集上的准确率提高4.11%。在目标检测任务中,DualConv大幅提高了YOLO-V3的检测速度,且将其在PASCAL VOC数据集上的平均准确度(mAP)提高4.4%。
DualConv的结构如图1所示,将N个DualConv卷积滤波器分为G组,每组N/G个卷积滤波器对M/G个输入特征映射图通道同时做3×3卷积和1×1卷积,而对剩下的(M-M/G)个通道只做1×1卷积。DualConv可以视为3×3组卷积和1×1点卷积的组合,因此可以很容易地集成到现有的深度神经网络架构中。
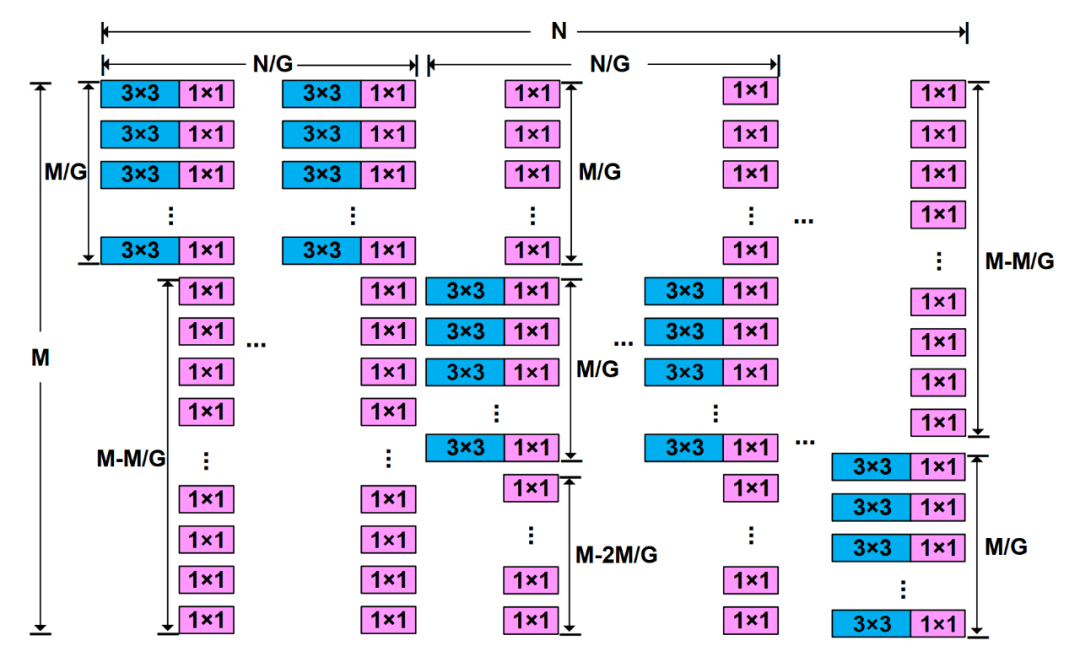
图 1 双卷积(DualConv)结构图
DualConv的主要贡献如下:
1.在组卷积基础上引入1×1点卷积,使输出特征映射图的每个通道都有完整的输入特征映射图信息,解决了组卷积中不同特征映射图通道组之间的信息交流不畅的问题。
2.通过并行卷积核的设计,解决了异构卷积破坏跨通道信息融合的连续性且不能完整保留原始输入特征映射图信息的问题,从而帮助更深的卷积层提取更有效的特征。
3.DualConv能够在保证神经网络准确度的同时极大地降低深度神经网络的计算量和参数量,有利于深度神经网络模型在嵌入式或移动设备中部署。
轻量级卷积核能够有效减少卷积神经网络的计算量和参数量,而不需要重新设计神经网络架构。近年来,一系列轻量级卷积核工作受到关注。深度可分离卷积(depthwise separable convolution)[1],如图2(b)所示,将标准卷积分解为深度卷积(depthwise convolution)和点卷积(pointwise convolution),其中k×k深度卷积用于特征提取,而1×1点卷积用于将深度卷积的输出进行通道维度的融合。组卷积(group convolution)[2],如图2(c)所示,将卷积滤波器与输入特征映射图通道都分为G组,每一组卷积滤波器只处理对应的输入特征映射图通道组,从而显著降低标准卷积的参数量和计算量。但是组卷积会阻碍不同特征映射图通道组之间的信息交流,这是因为不同的卷积滤波器组只从对应的输入特征映射图通道组提取信息。为了解决这个问题,ShuffleNet [3]采用通道混洗(channel shuffle)操作来加强不同输入特征映射图通道组之间的信息交流。异构卷积(heterogeneous convolution)[4],如图2(d)所示,在一个卷积滤波器中同时包含3×3卷积和1×1卷积。异构卷积滤波器内的卷积核以移位形式(shifted manner)排列(详见论文[4]的图3):在一个异构卷积滤波器中,M/P个3×3卷积核离散分布,并且与(M-M/P)个1×1卷积核交替排列。由于异构卷积破坏跨通道信息融合的连续性而且没有完整保留原始输入特征映射图信息,因此这样的设计会降低神经网络的准确度。
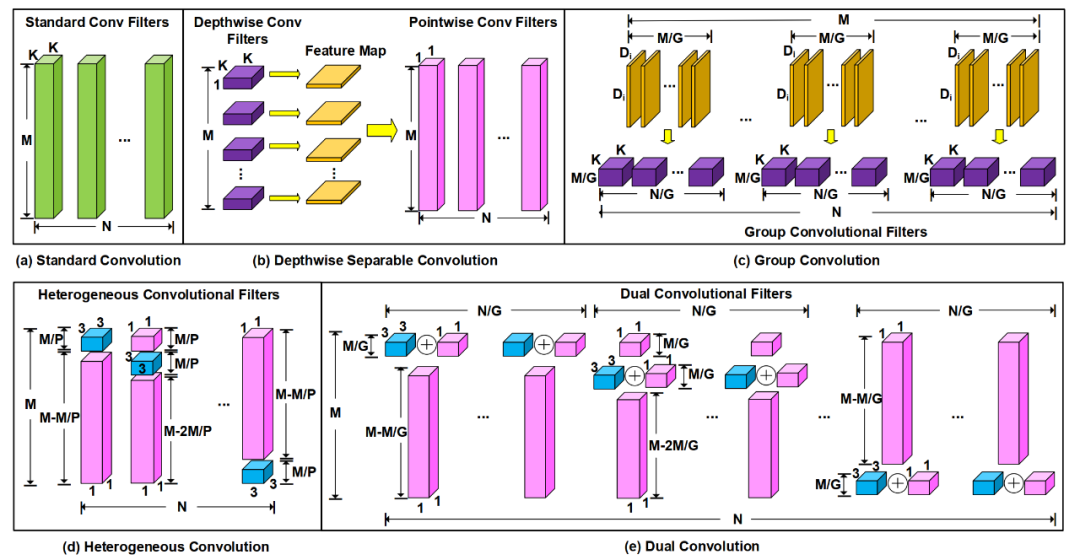
图 2 (a) 标准卷积、(b) 深度可分离卷积、(c) 组卷积、(d) 异构卷积、(e) 双卷积的卷积层结构图
如图2(e)所示,我们将N个DualConv卷积滤波器分为G组,每组N/G个卷积滤波器处理全部输入特征映射图通道,其中对M/G个输入特征映射图通道同时做3×3卷积和1×1卷积并且将卷积结果相加,而对剩下的(M-M/G)个通道只做1×1卷积。由于分组结构能够增强卷积滤波器在通道维度的块对角线稀疏性,具有高相关性的卷积滤波器能够以更结构化的方式学习[5],因此DualConv的卷积滤波器没有采用异构卷积的移位排列方式。DualConv可以看作是3×3组卷积和1×1点卷积的组合,它可以很容易地集成到现有的深度神经网络架构中。DualConv通过组卷积策略减少深度神经网络的计算量,并通过M个1×1点卷积来保留输入特征映射图的原始信息从而最大化不同卷积层之间的跨通道信息交流,因此DualConv并不需要通道混洗操作来进行跨通道信息融合。
假设输出特征映射图的大小为
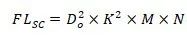
在DualConv中,给定组数G,K×K和1×1并行卷积核的数量是输入通道数的1/G,余下的(1-1/G)比例的卷积核为1×1卷积。因此并行卷积核的计算量为:
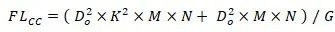
而余下的1×1卷积核的计算量为:
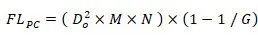
因此DualConv卷积层的总计算量为:
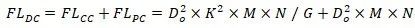
对比DualConv卷积层和标准卷积层的计算量可得计算量压缩比为:
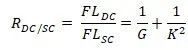
由上式可以看到,如果DualConv的卷积核大小K=3,当组数G很大时DualConv对比标准卷积的加速比可以达到8到9倍。
本文在CIFAR-10、CIFAR-100、ImageNet和Pascal VOC这四个数据集上将DualConv应用于主流深度神经网络架构中进行对比实验。
表 1 DualConv应用于VGG-16和ResNet-50在CIFAR-10数据集上的性能比较(VGG-16(ResNet-50)_Gα代表使用DualConv修改的VGG-16或ResNet-50网络,VGG-16_GC_Gα代表组卷积修改的VGG-16,VGG-16_HC_Pα代表异构卷积修改的VGG-16,其中α表示DualConv和组卷积的组数G或异构卷积的参数P。)
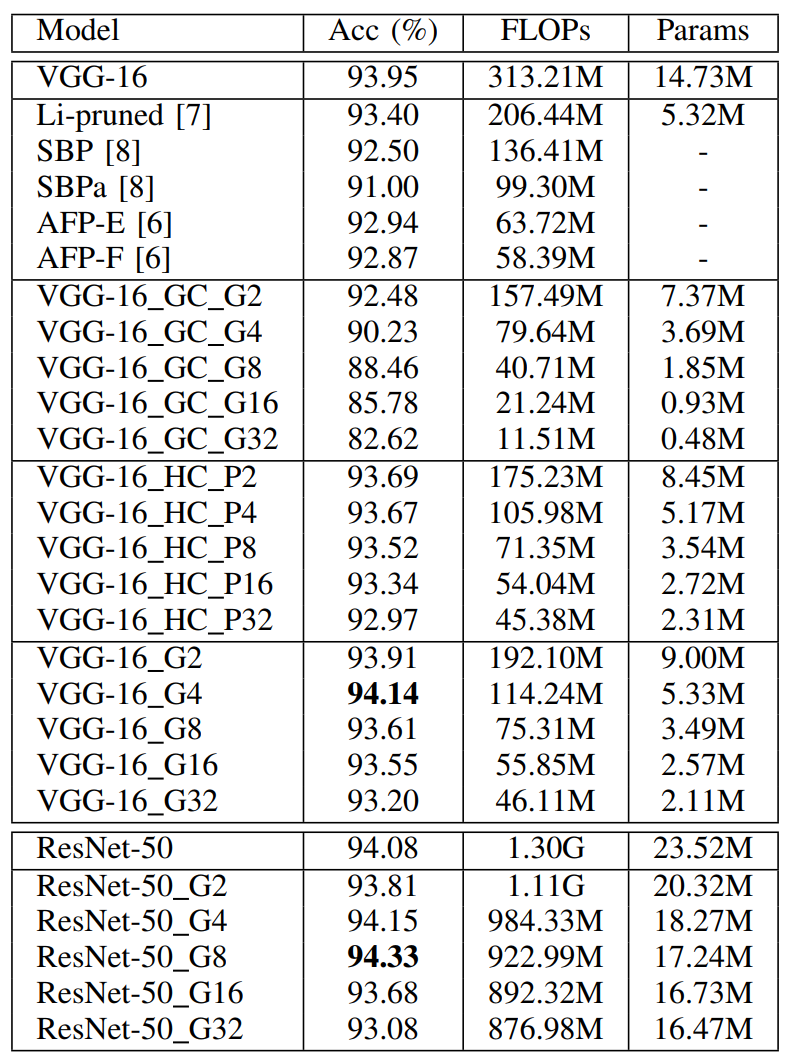
从表1我们可以看出,DualConv对比其他方法有更高的准确度。在加大组数G,进一步降低深度神经网络参数量和计算量的同时,只损失一点准确度性能。
表 2 DualConv应用于MobileNetV1和MobileNetV2在CIFAR-10数据集上的性能比较
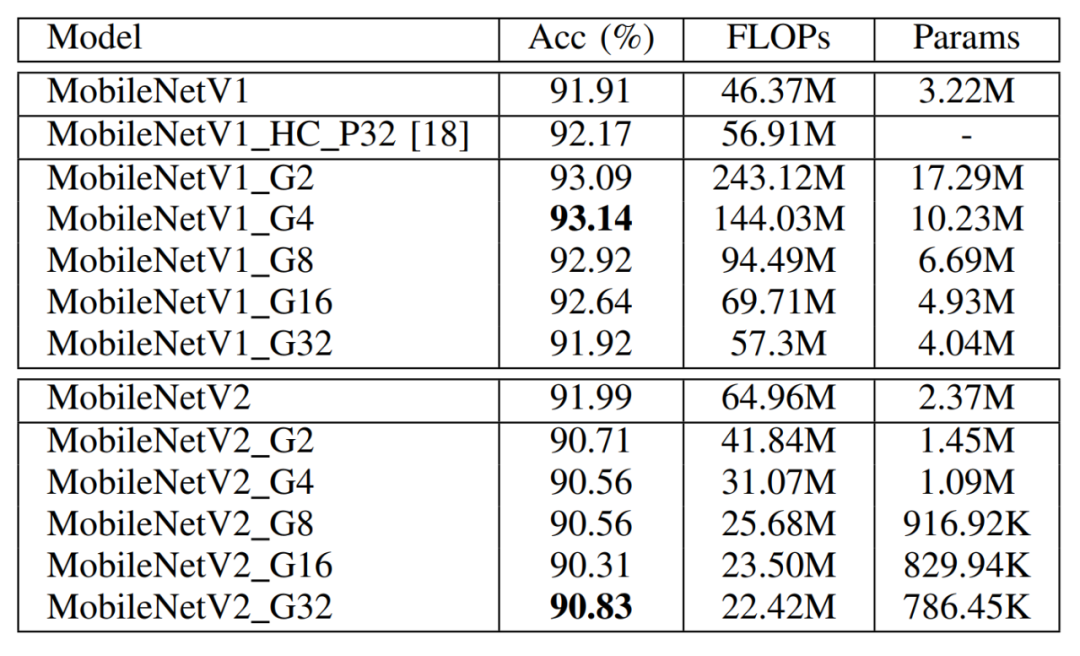
由表2可以看出,虽然DualConv在MobileNetV1网络上的替换策略会增加网络的计算量和参数量,但是能够提高1.23%的准确度。将DualConv应用于MobileNetV2网络,在组数G=32时能够将网络计算量参数量降低60%而只有1.16%的准确度损失。
表 3 DualConv应用于VGG-16和ResNet-50在CIFAR-100数据集上的性能比较
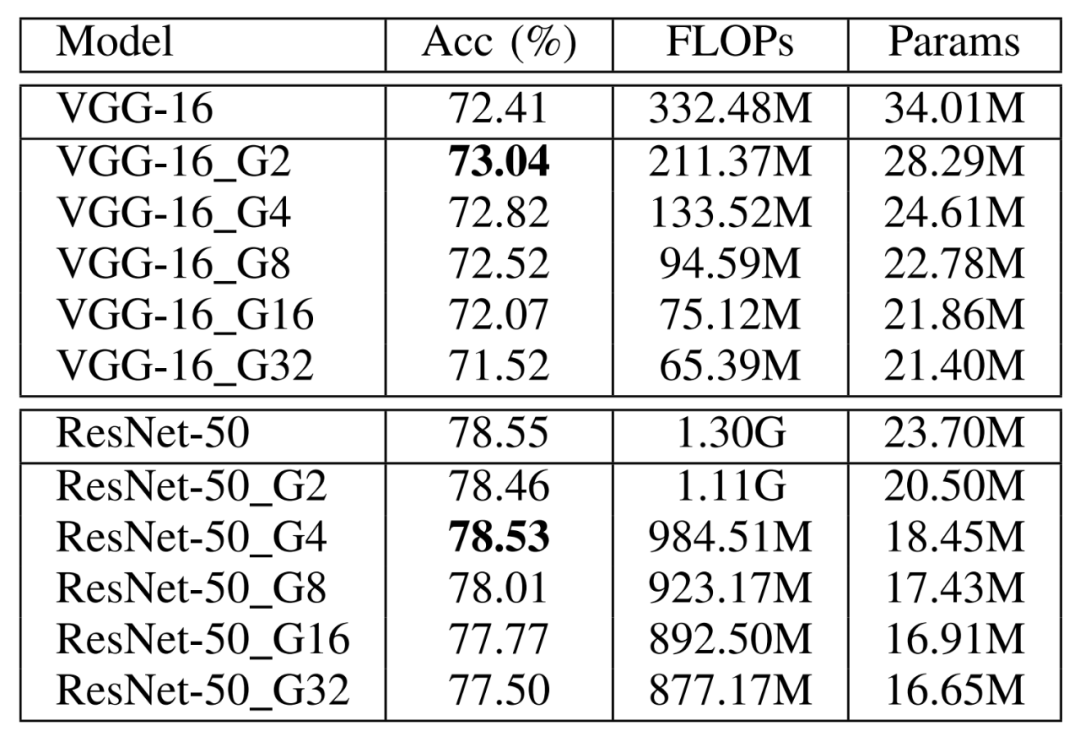
由表3可以看出,在CIFAR-100数据集上,DualConv不仅能够降低VGG-16的参数量和计算量,甚至可以提高VGG-16网络的准确度。
表 4 DualConv应用于MobileNetV1和MobileNetV2在CIFAR-100数据集上的性能比较
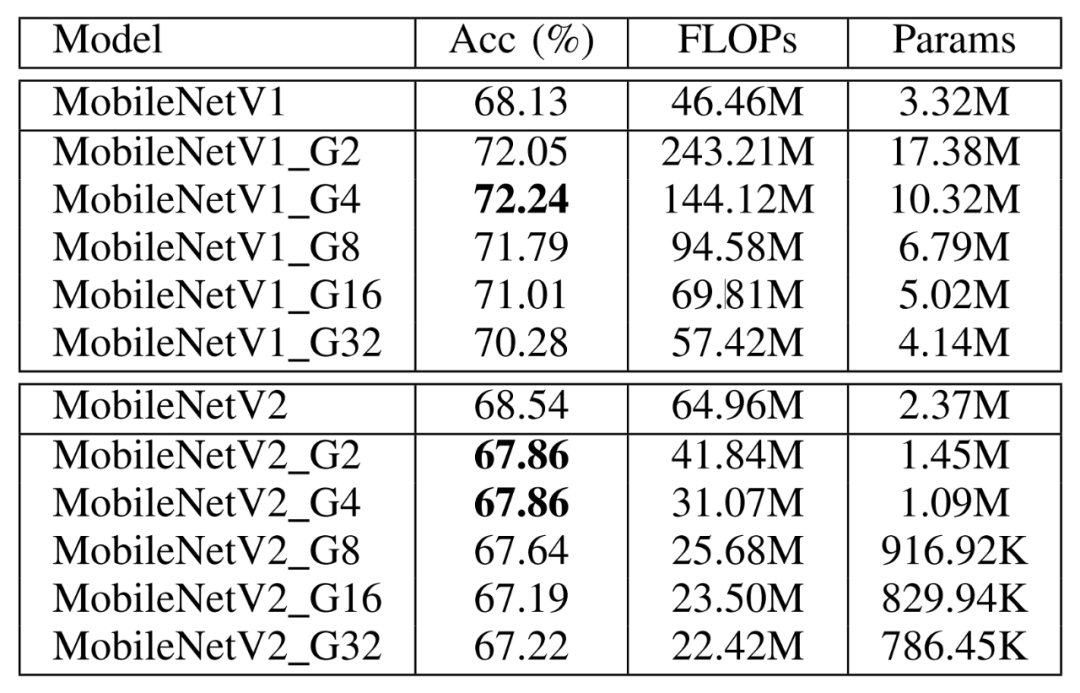
由表4可以看出,在CIFAR-100数据集上,当组数G=32时DualConv修改的MobileNetV1网络大小和原网络基本一致,但是提高了2.15%的准确度。当组数G=2或4时,DualConv能够显著降低MobileNetV2网络的计算量和参数量而只有0.68%的准确度损失。
表 5 DualConv应用于VGG-16和ResNet-50在ImageNet数据集上的性能比较(GTime代表GPU时间,CTime代表CPU时间,*代表在一个M40 GPU进行推理(批大小为32)。)
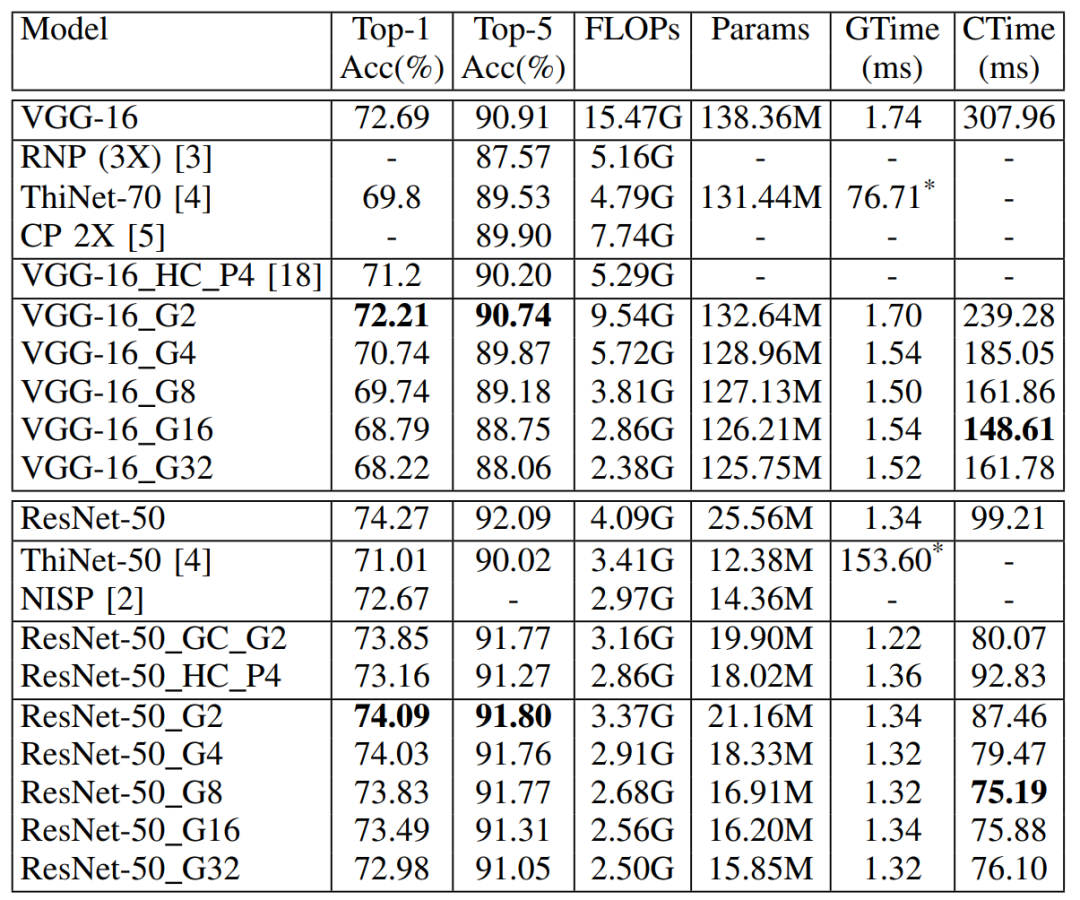
从表5可以看出,当G=2时,DualConv修改的VGG-16网络的计算代价比原网络降低38%,只有轻微的准确度损失(0.48%的Top-1准确度损失和0.17%的Top-5准确度损失);DualConv修改的ResNet-50网络在大幅度降低原网络计算代价和参数量的同时也只有轻微的准确度损失(0.18%的Top-1准确度损失和0.29%的Top-5准确度损失)。在推理时间方面,GPU线程同步带来的额外消耗导致GPU推理时间差别不明显,但是从CPU单线程推理时间可以看出,DualConv在保证准确度的同时能够显著降低深度神经网络的推理时间。
表 6 DualConv应用于MobileNetV1和MobileNetV2在ImageNet数据集上的性能比较
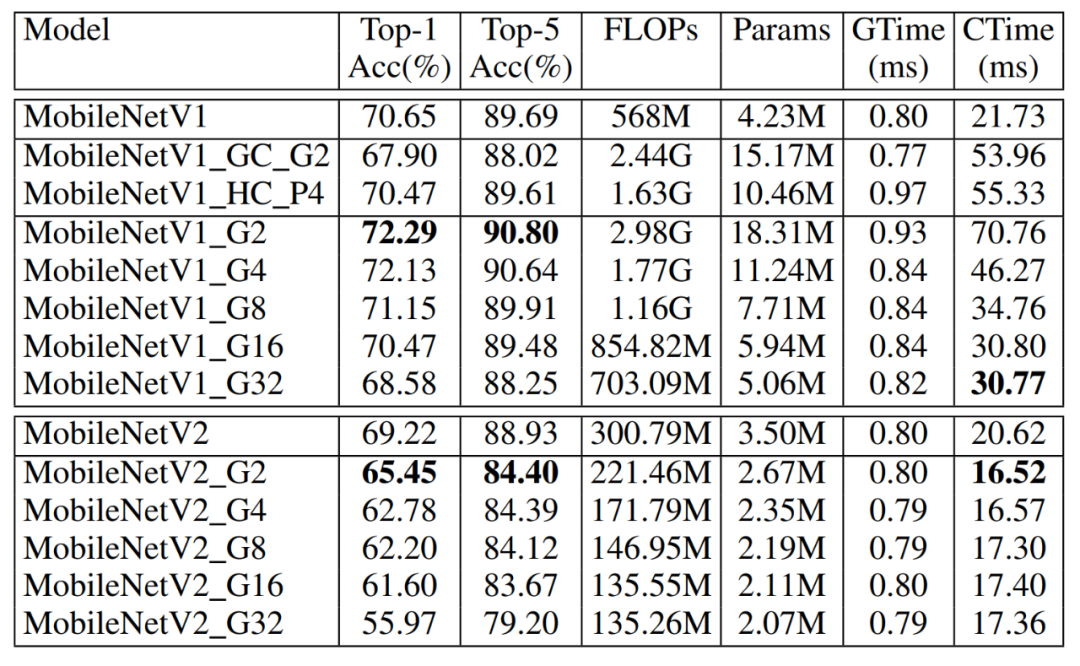
表6显示,DualConv能够降低MobileNetV2网络的推理时间。由于原MobileNetV2网络的反转残差结构将特征映射图激活两次,因此这可能是DualConv替换反转残差结构导致准确度降低的原因。图3展示了ResNet-50和MobileNetV1网络在ImageNet示例图像上的可视化结果。
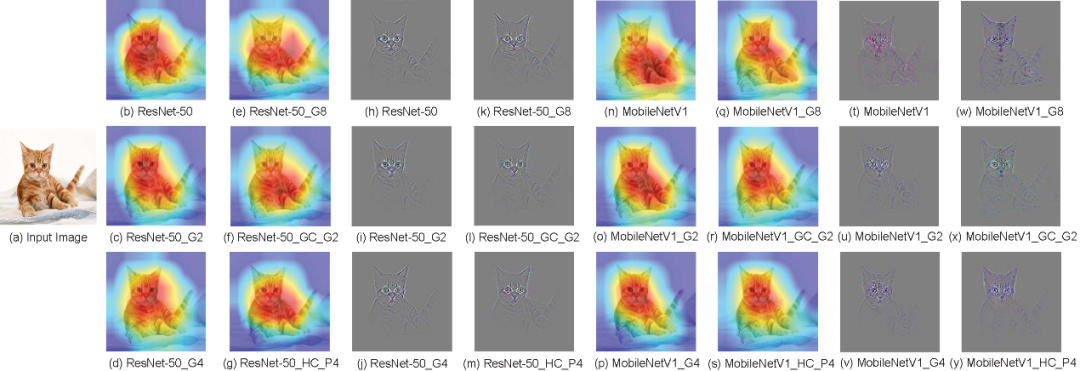
图 3 ResNet-50和MobileNetV1网络在ImageNet示例图像上的可视化结果
图3中,(a) 是原始输入图像,(b)∼(g) 是在ResNet-50网络上使用Grad-CAM方法得到的热力图,(h)∼(m) 是在ResNet-50网络上使用guided Grad-CAM方法得到的可视化结果,(n)∼(s) 是在MobileNetV1网络上使用Grad-CAM方法得到的热力图,(t)∼(y) 是在MobileNetV1网络上使用guided Grad-CAM方法得到的可视化结果。
由以上结果可以看出DualConv能够应用于标准深度神经网络架构和轻量级深度神经网络架构,且在各个图像分类数据集上有很强的泛化能力。为了验证DualConv可以泛化到不同的任务,我们将DualConv进一步应用于目标检测的YOLO-V3模型。
表7 DualConv应用于YOLO-V3在PASCAL VOC数据集上性能比较
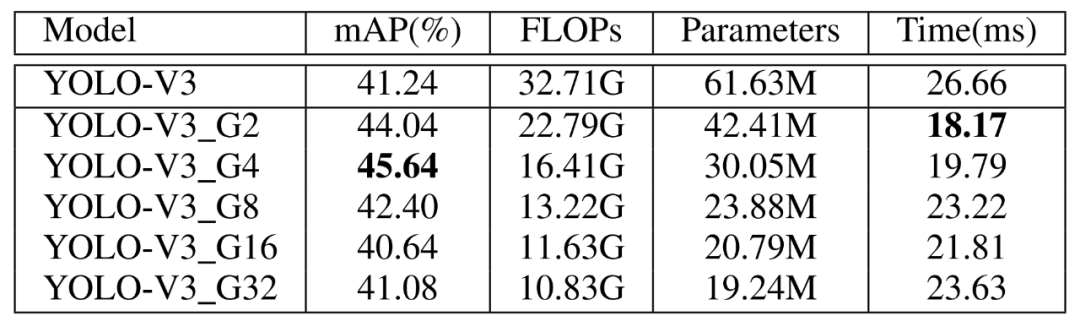
从表7中可以看出,DualConv应用于YOLO-V3模型中不仅能够提高模型的推理速度,当组数G=4时能够将算法的平均准确度提高4.4%。需要注意的是我们没有将YOLO-V3在大规模数据集上进行预训练,因此其准确度不能与有预训练的模型准确度进行对比。
本文提出的高效并行卷积核DualConv解决了组卷积和异构卷积中存在的问题,能够在显著降低网络计算量和参数量的同时保证神经网络的性能。在多个数据集和网络架构的实验表明,DualConv具有强大的泛化能力。未来我们将对DualConv进行网络架构搜索,从而找到更优的DualConv网络架构。
[1] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convo lutional neural networks for mobile vision applications,” 2017, arXiv:1704.04861.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proceedings of Annual Conference on Neural Information Processing Systems, 2012, pp. 1097–1105.
[3] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6848–6856.
[4] P. Singh, V. K. Verma, P. Rai, and V. P. Namboodiri, “HetConv: Heterogeneous kernel-based convolutions for deep CNNs,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4835–4844.
[5] Y. Ioannou, D. Robertson, R. Cipolla, and A. Criminisi, “Deep roots: Improving CNN efficiency with hierarchical filter groups,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5977–5986.




