18篇CVPR 2022 中科院自动化所新作速览!

导读 | CVPR是计算机视觉的世界三大顶会之一,2022年将在美国新奥尔良召开。本届会议自动化所共有35篇论文录用,我们将通过上下两期推文对相关研究进行简要介绍(排名不分先后),欢迎大家一起交流讨论。
01. UniVIP:一个统一的视觉自监督预训练框架
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
在视觉领域中,如何充分利用大量的无标签视觉数据,构建一个高效的通用视觉自监督预训练模型,有效降低下游任务数据标注量,在使用少量带标签数据甚至不使用数据微调即可获得超越全监督模型的性能,具有非常重要的研究和应用价值。
然而,当前流行的自监督方法往往存在语义一致性问题,即仅对单目标图像有效(如ImageNet),并且忽略了场景和实例之间的相关性,以及场景中实例的语义差异。为了解决上述问题,我们提出了一种统一的自监督视觉预训练方法UniVIP,这是一种新颖的自监督框架,用于在单中心对象或多目标数据集上学习通用视觉表示。该框架考虑了三个层次的表示学习:1)场景-场景的相似性,2)场景-实例的相关性,3)实例-实例的区分。在学习过程中,我们采用最优传输算法来自动测量实例的区分度。
大量实验表明,在多目标数据集 COCO 上预训练的 UniVIP,在图像分类、半监督学习、目标检测和分割等各种下游任务上实现了最先进的性能。此外,我们的方法还可以利用 ImageNet 等单中心对象数据集,并且在线性评估中使用相同的预训练 epoch时优于BYOL 2.5%,并且在 COCO 数据集上超越了当前的自监督目标检测方法,证明了它的通用性和潜力。
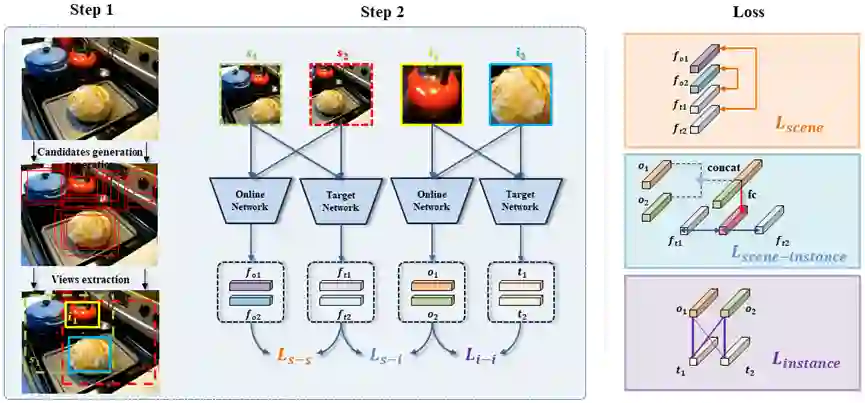
图. UniVIP框架图
作者:Zhaowen Li, Yousong Zhu, Yang Fan, Wei Li, Chaoyang Zhao, Yingying Chen, Zhiyang Chen, Jiahao Xie, Liwei Wu, Rui Zhao, Ming Tang, Jinqiao Wang
02. C2AM损失:为长尾目标检测任务追求更好的决策边界
C2AM Loss: Chasing a Better Decision Boundary for Long-Tail Object Detection
对于长尾目标检测任务来说,线性分类器中不同类别对应的参数向量的模值呈现一个极度不均衡的分布。这种分类器参数模值的分布不均会产生病态的分类边界(下图(a)),使得分类器参数模值较小的类别有接近于零的精度。余弦分类器可以避免由于分类器参数模值分布不均导致的病态的分类边界,但是其分类边界位于两个类别对应分类器参数向量的角分线上(下图(b)),没有考虑到类别的特性。
直觉上说,样本丰富度比较小的类别在分类空间中应该占据较小的区域。为了使网络为尾部类别学习到一个更加紧凑和本质的特征表示,我们提出了一种类别感知的角度间隔损失(Category-Aware Angular Margin Loss,C2AM Loss),通过加入与类别相关的自适应的角度间隔来对不同类别间的分类边界进行调整。具体的公式如式(1)(2)所示。
该方法对比基线方法有显著的性能提升(4.9%~5.2% APm),并且在LVIS数据集上超越了当前的长尾目标检测算法,实现了同期的最好性能。
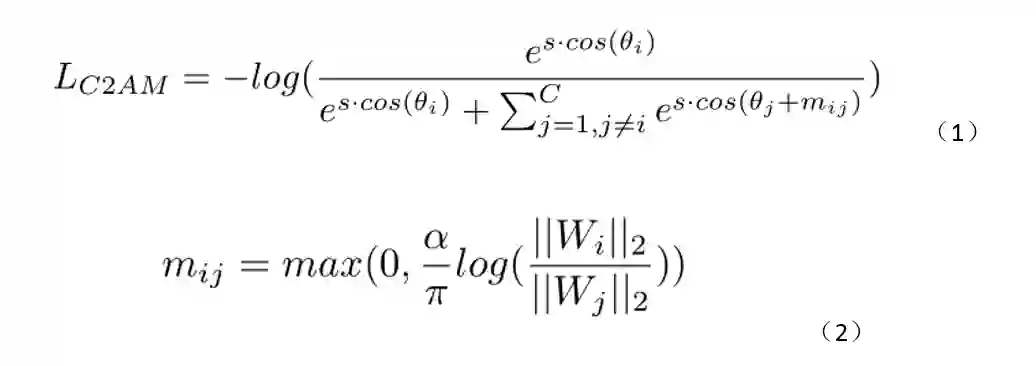
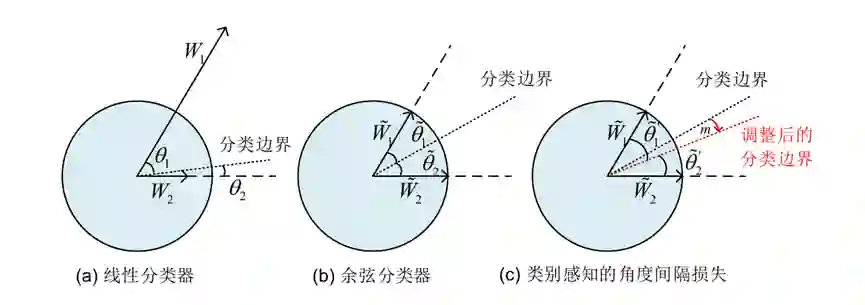
图. 不同条件下的分类边界示意图
作者:Tong Wang, Yousong Zhu, Yingying Chen, Chaoyang Zhao, Bin Yu, Jinqiao Wang, Ming Tang
03. APRIL:寻找视觉Transformer隐私泄露的关键弱点
APRIL: Finding the Achilles' Heel on Privacy Leakage for Vision Transformers
联邦学习作为一种数据隔绝的分布式训练框架能够避免数据隐私的直接泄露。然而,梯度泄露攻击 (gradient leakage)作为一种隐私攻击方法,能够从卷积神经网络或全连接网络的梯度中恢复数据的隐私信息。论文面向基于注意力机制的模型结构,分析了注意力模块固有的隐私缺陷,提出了针对注意力模块的闭式解攻击和针对Transformer的基于优化的隐私攻击方法APRIL。APRIL相比于已有的攻击方法能够在基于注意力结构的模型上获得更好的隐私攻击效果。论文还提出了针对APRIL攻击的防御手段,为面向隐私保护的模型结构设计提供了启发。
作者:Jiahao Lu, Xi Sheryl Zhang. Tianli Zhao, Xiangyu He, Jian Cheng
04. 基于本地正则化和稀疏化差分隐私的联邦学习
Differentially Private Federated Learning with Local Regularization and Sparsification
用户级差分隐私能够为联邦学习中任一用户的数据提供可认证的隐私保证。然而,现有的确保用户级差分隐私的方法都以严重损害模型精度为代价。论文研究了造成这种损害的原因,发现解决这个问题的关键是在执行保证差分隐私的操作之前,自然地限制本地权重更新的范数。基于这一观察,论文提出了有界局部更新正则化和局部更新稀疏化两种技术,以达到在不牺牲隐私的前提下提高模型精度的目标,对框架的收敛性和隐私性进行了理论分析。大量的实验表明,该框架显著地改善了隐私与精度之间的权衡。
作者:Anda Cheng, Peisong Wang, Xi Sheryl Zhang, Jian Cheng
05. MixFormer:跨窗口与维度的特征融合
MixFormer: Mixing Features across Windows and Dimensions
基于局部窗口的自注意力(local-window Self-attention)可以广泛应用在多个视觉任务上,然而它在应用的过程中面临两个问题:(1)感受野受限;(2)通道维度上的建模能力较弱。这是因为该方法在没有重叠的局部窗口上做自注意力操作并且在通道维度共享参数导致的。论文提出了一种通用模型MixFormer,旨在解决上述问题。首先,MixFormer基于平行分支设计(parallel design),将局部自注意力(local-window Self-attention)与通道分离卷积(depth-wise Convolution)进行结合,融合了局部窗口的信息,扩大了感受野;其次,MixFormer根据不同分支上操作共享参数的维度不同,在平行分支之间,MixFormer提出双向交互模块(bi-directional interaction),融合不同维度信息,增强模型在各个维度的建模能力。基于以上两点,MixFormer作为一个通用的模型,在图像分类、目标检测、实例分割、语义分割、人体关键点检测、长尾实例分割等多个视觉任务上都取得了SOTA的结果。
作者:Qiang Chen, Qiman Wu, Jian Wang, Qinghao Hu, Tao Hu, Errui Ding, Jian Cheng, Jingdong Wang
06. 基于粗粒度和细粒度特征匹配的视频描述评估
EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching
当前,视频描述的评价方式主要基于参考文本和候选描述之间的文本比较。忽略了视频描述任务的特性,可能导致有偏差的评估。因此,我们提出了 EMScore(Embedding Matching-based score),这是一种专用于视频描述的新颖的无参考评价指标,其直接度量视频和候选描述之间的相似度。实验表明 EMScore 具有更高的人类相关性和更低的参考依赖性。
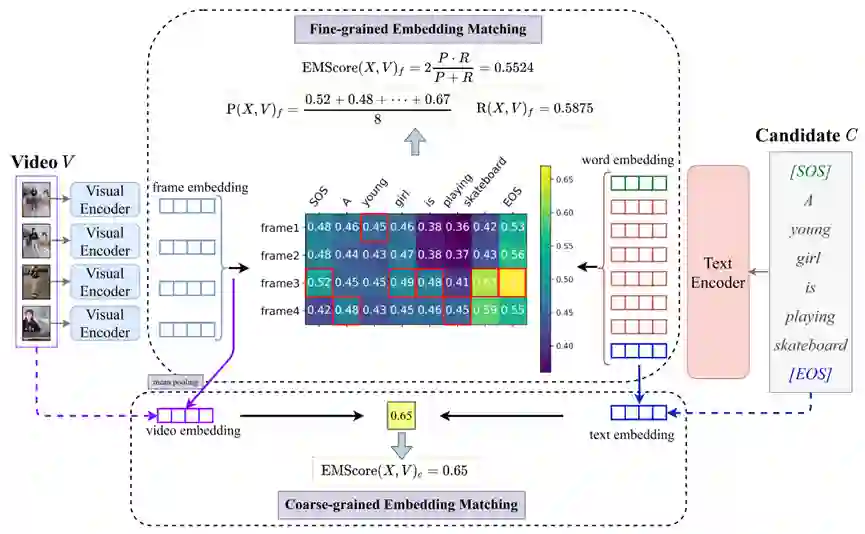
作者:Yaya Shi, Xu Yang, Haiyang Xu, Chunfeng Yuan, Bing Li, Weiming Hu, Zheng-Jun Zha
07. 基于视觉-语言验证和迭代推理的视觉定位
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
近年来,从跨模态模型中进行知识蒸馏使得开放词汇检测任务取得了快速进展。然而,我们发现用单阶段检测器进行知识蒸馏所达到的效果远不如双阶段检测器,我们分析了产生这种差异的原因是双阶段方法中类别无关的物体候选覆盖了未见类别,使得它在蒸馏时能学到未见类别的语义信息,而单阶段方法中所定义的正样本只包含已知类别,缺失了对新类别的学习。
为了弥补单阶段方法因缺少类别无关物体候选的这种固有缺陷,我们提出了一种对未见类别物体进行隐式学习的弱监督方法。该方法通过caption与特征图之间的跨模态注意力机制来进行语言到视觉的全局级知识蒸馏。凭借以上方案,我们显著超过了过去最好的开放词汇单阶段检测器。
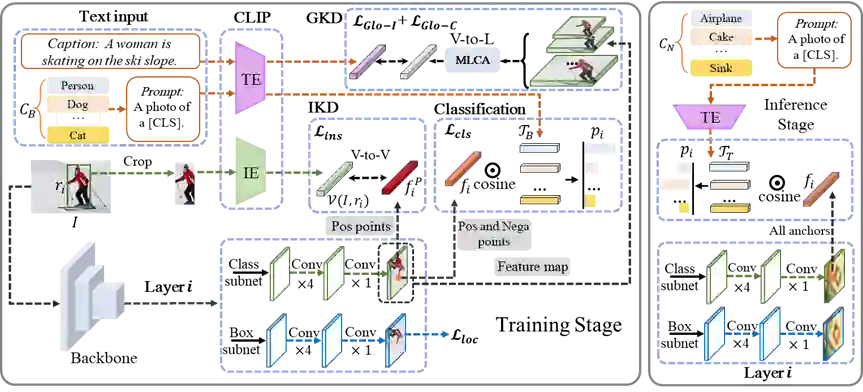
作者:Li Yang, Yan Xu, Chunfeng Yuan*, Wei Liu, Bing Li, Weiming Hu
08. 基于层次化视觉语言知识蒸馏的开放词汇单阶段检测
Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning
本文提出了一个基于transformer的框架,通过建立文本关联的判别性特征和多阶段跨模态推理来实现准确的视觉定位(visual grounding)。具体来说,我们设计了一个视觉-语言验证模块(visual-linguistic verification module),使视觉特征关注于文本描述相关的区域,并抑制其它无关区域。同时我们还设计了一个语言指导的特征编码器(language-guided feature encoder)来聚合目标的视觉上下文,提高其特征辨别性。为了从建立的视觉特征中检索出目标,我们进一步提出了一种多阶段的跨模态解码器(multi-stage cross-modal decoder)来迭代推理图像和语言之间的相关性,从而准确定位目标。我们在RefCOCO、RefCOCO+和 RefCOCOg数据集上进行了实验,并取得了state-of-the-art的性能。
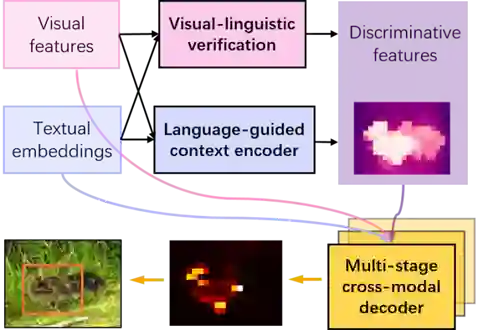
作者:Zongyang Ma, Guan Luo, Jin Gao, Liang Li, Yuxin Chen, Shaoru Wang, Congxuan Zhang, and Weiming Hu
09. 基于Transformer的图象风格化
StyTr2: Image Style Transfer with Transformers
本文提出了一种基于变压器(Transformer)的图像风格迁移方法,即StyTr2,将输入图像的长期依赖关系引入到风格化中。与用于其它视觉任务的Transformer不同,本文设计的StyTr2包含两个不同的Transformer编码器,分别为内容和风格图片生成具有不同域特征的序列。在编码器之后,采用多层Transformer解码器,根据风格序列对内容序列进行风格化。此外,本文分析了现有位置编码方法的不足,提出了内容感知的位置编码,该方法具有尺度不变特性,更适合于图像风格化任务。与基于CNN和基于流的最新方法相比,定性和定量实验均证明了StyTr2的有效性。
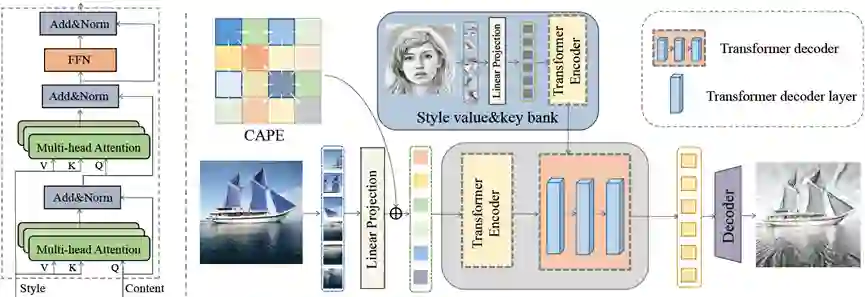
图. 网络结构

图. 风格化结果比较
作者:Yingying Deng, Fan Tang, Weiming Dong, Chongyang Ma, Xingjia Pan, Lei Wang, Changsheng Xu
代码已开源:https://github.com/diyiiyiii/StyTR-2
10. 基于细粒度时序对比学习的弱监督行为定位
Fine-grained Temporal Contrastive Learning forWeakly-supervised Temporal Action Localization
目前,弱监督视频行为定位方法主要遵循于通过优化视频级分类目标来实现定位的方式。这些方法大多忽略了视频之间丰富的时序对比关系,因此在分类学习和分类-定位自适应的过程中面临着极大的模糊性。本文认为通过考虑上下文的序列到序列对比可以为弱监督时序行为定位提供本质的归纳偏置并帮助识别连续的行为片段。因此,如图1所示,本文在一个可导的动态规划框架下,设计了包括细粒度序列距离对比和最长公共子序列对比在内的两个互补的对比目标函数。在多个主流的基准数据集上的实验结果表明本文方法取得了显著的效果。
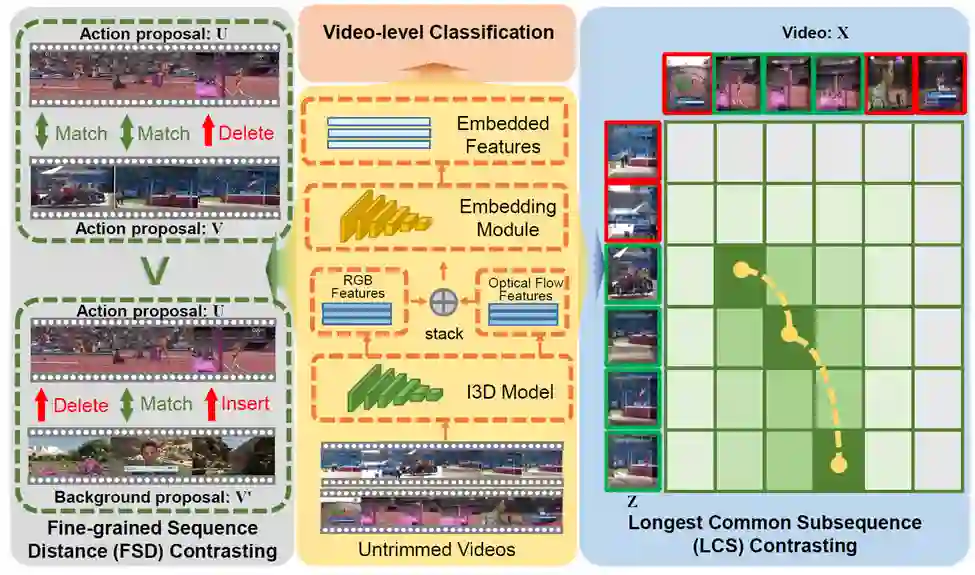
图. 基于细粒度时序对比学习的弱监督行为定位方法框架
作者:Junyu Gao, Mengyuan Chen, Changsheng Xu
11. AME:超参数优化中的注意力和记忆增强
AME: Attention and Memory Enhancement in Hyper-Parameter Optimization
深度神经网络的训练受制于敏感的超参数和不及时的性能评估反馈。针对这两个难点,在深度强化学习的框架下,本文提出了一种高效的并行超参数优化模型,命名为AME。从技术上讲,本文开发了一种注意力和记忆增强结构,能够精准搜索嵌入到巨大搜索空间中的高性能配置。具体地,该结构应用了多头注意力机制和记忆机制,以增强神经网络捕捉不同超参数配置间的短期和长期关系的能力。在AME的优化过程中,本文采用了概念直观但功能强大的Bootstrap策略来解决由于性能评估反馈不及时而导致的样本数量不足的问题。最后,在图像分类、目标检测、语义分割这三个视觉任务上进行实验,证明了AME的有效性。
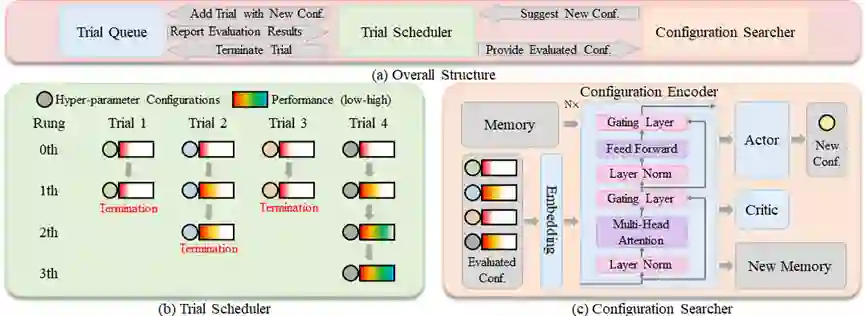
图. 模型整体结构
作者:Nuo Xu, Jianlong Xing, Xing Nie, Shiming Xiang, Chunhong Pan
12. 视觉提示调优
Vision Prompt Tuning
在计算机视觉中,微调是广泛采用的将预训练视觉模型适应于下游任务的方法。然而,由于这类方法多采用低效的全局参数更新策略,以及严重依赖于高质量的下游数据,在实践中部署非常具有挑战性。最近,基于prompt的方法采用任务特定的提示以使下游任务适应预训练模型,极大地提高了许多自然语言下游任务的性能。在本工作中,我们将这种显著的迁移能力扩展到视觉模型中,作为微调的替代方案。为此,我们提出了视觉提示调整(VPT),这是一种参数高效的视觉调优范式,可将冻结的视觉模型适应到下游数据。VPT 的关键是基于提示的调优,即只学习与输入图像拼接的特定于任务的视觉提示,并冻结预训练模型。通过这种方式,VPT只需训练少量的额外参数即可产生轻量级、鲁棒的下游模型。实验证明我们的方法在大量的下游视觉数据集上优于当前的微调方法,包括图像损坏、对抗性示例、长尾分布和OOD问题等。
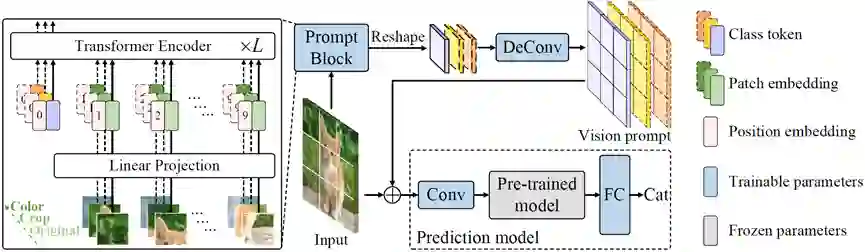
作者:Xing Nie, Gaofeng Meng, Jianlong Chang, Chunlei Huo, Shiming Xiang, Qi Tian, Zhaoxiang Zhang, Chunhong Pan
13. 基于架构增长的连续驾驶场景的连续立体匹配
Continual Stereo Matching of Continuous Driving Scenes with Growing Architecture
深度立体匹配模型近年来在驾驶场景中取得了先进的性能,但是其部署在未见过的场景时性能会严重下降。尽管最近的研究工作通过连续的在线自适应缓解了这个问题,但这种设定在模型推理时仍然需要不断进行梯度更新,并且很难应对快速变化的场景。为了应对这些挑战,本文提出了连续立体匹配问题,旨在让模型能够不断地学习新场景,同时克服遗忘之前学习的场景,并且在模型部署时能连续地预测视差。本文通过引入可复用架构增长(RAG)框架来实现此目标。RAG利用基于特定任务的神经单元搜索和网络架构增长来连续地学习新场景。在增长时,通过重用之前的神经单元来保持较高的复用率,同时获得良好的性能。本文进一步引入了一个场景路由模块,以在推理时自适应地选择适用于特定场景的架构路径。实验结果表明,本文提出的方法在各种具有挑战性的天气和道路环境中都优于此前最先进的方法。
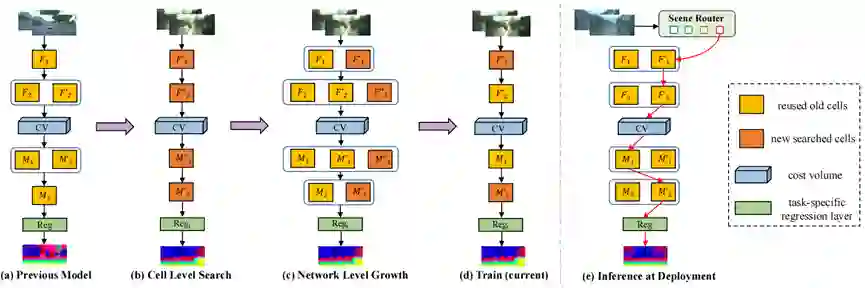
图. 可复用架构增长(RAG)框架示意图
作者:Chenghao Zhang, Kun Tian, Bin Fan, Gaofeng Meng, Zhaoxiang Zhang, Chunhong Pan
14. 基于层次解析胶囊网络的无监督人脸部件发现
HP-Capsule: Unsupervised Face Part Discovery by Hierarchical Parsing Capsule Network
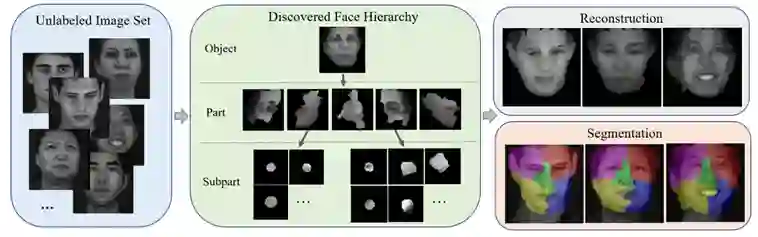
图. 层级解析胶囊网络的简要说明
胶囊网络旨在通过一组部件以及部件之间的关系来表征物体,这对视觉感知过程提供了指导。尽管最近的工作证明了胶囊网络在简单对象(如数字)上的成功,但对具有同源结构的人脸的探索仍然不足。
在本文中,我们提出了一种层级解析胶囊网络(HP-Capsule),用于无监督的人脸部件发现。在浏览没有标签的大规模人脸图像时,网络首先使用一组可解释的子部分胶囊对经常观察到的模式进行编码。然后,通过基于Transformer 的解析模块 (TPM) 将子部分胶囊组装成部件级胶囊,以学习它们之间的组合关系。在训练过程中,随着人脸层次结构的逐步构建和细化,部件胶囊自适应地对具有语义一致性的人脸部分进行编码。 HP-Capsule 将胶囊网络的应用从数字扩展到人脸,并向前迈出了一步,展示了神经网络如何在没有人工干预的情况下理解同源对象。
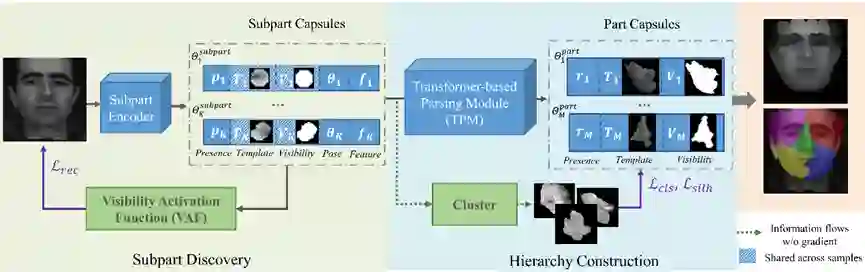
图. HP-Capsule模型结构示意
作者:Chang Yu, Xiangyu Zhu, Xiaomei Zhang, Zidu Wang, Zhaoxiang Zhang, Zhen Lei
15. 长尾视觉数据识别的嵌套式协同学习方法
Nested Collaborative Learning for Long-Tailed Visual Recognition
近年来,长尾分布数据的视觉识别问题受到了越来越多的关注。通过大量的实验,我们发现在相同的训练设置,不同的模型初始化下,长尾数据训练出的模型表现出相当大的差异,这体现出了长尾学习中巨大的不确定性。为了减轻这种不确定性,我们提出了一种多专家网络的嵌套式的协同学习方法(NCL),它由两个部分组成,即嵌套个体学习(NIL)和嵌套平衡在线蒸馏(NBOD),前者着重于单个专家网络的学习,后者则帮助多个专家网络传递学到的知识,协同学习。NIL和NBOD都在嵌套的关系中学习,即基于所有类别的全局注意力学习和基于难类别的局部注意力学习。这样的嵌套关系来自于我们提出的简洁有效的难类别挖掘模块(HCM)。对于网络的输出分数,HCM仅选择部分拥有高分数的难类别作为网络训练的负类别,这样便构建出了嵌套关系中的局部注意力。通过NCL,网络的学习彼此嵌套、互补,这样不仅有利于网络捕捉到全局且鲁棒的特征,还提升了网络对更细粒度信息的区分能力。除此之外,自监督也被应用到其中,加强特征的学习。该方法在长尾数据库CIFAR-10/100-LT, Places-LT, ImageNet-LT和 iNaturalist 2018上都取得了目前最好的性能。
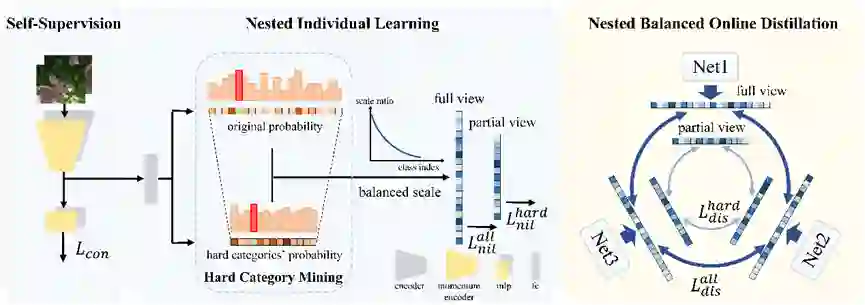
作者:Jun Li, Zichang Tan, Jun Wan, Zhen Lei, Guodong Guo
16. 基于时空解耦与重耦的RGB-D动作识别
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
在行为识别领域,虽然当前的一些基于RGB-D模态的动作识别方法可以取得显著效果,但是他们都是建立在时空紧密耦合架构的基础上进行的时空信息建模。因此,这些方法主要存在以下三个问题:(1)由于时空建模过程的紧密耦合,导致在一些小数据集上面临一定的优化困难;(2)网络中包含的大量与分类无关的边缘冗余信息可能会误导分类器做出错误的决策;(3)视频多模态信息之间缺乏有效的时空交互导致后验融合机制不能充分发挥其作用。所以在本文中,我们提出了一种有效建模时空信息的解耦与重耦合机制以及一种新颖的RGB-D多模态时空信息交互策略。具体来讲,我们将多模态时空信息建模过程分成三个子任务:(1)通过解耦时空建模网络实现高质量维度无关的时间和空间表征学习。(2)重新耦合这些解耦的时空表征以重新建立强时空依赖。(3)引入一种新的跨模态时空信息交互方案和自适应后验融合机制(CAPF)来深度融合RGB-D多模态时空信息。通过充分利用以上技术,可以实现更加鲁棒的时空表征学习。
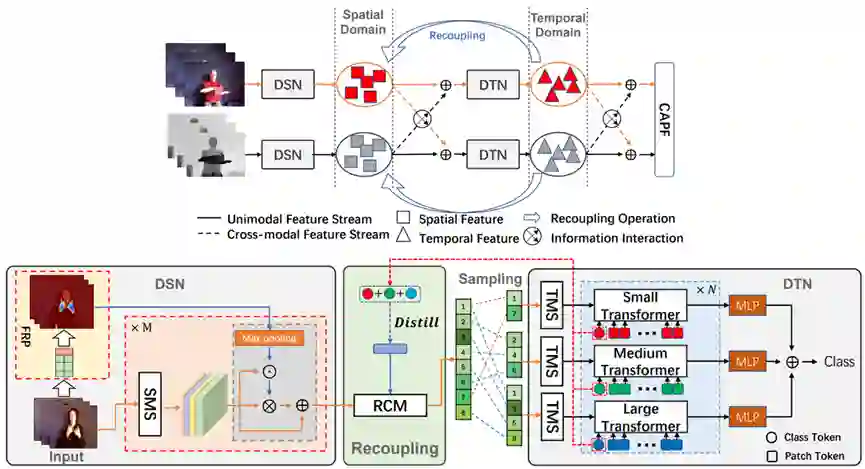
图. 基于解耦与重耦合机制的多模态时空表征学习网络架构
作者:Benjia Zhou, Pichao Wang, Jun Wan, Yanyan Liang, Fan Wang, Du Zhang, Zhen Lei, Hao Li, Rong Jin
17. 基于灵活模态Transformer的人脸防伪
FM-ViT: Flexible Modal Vision Transformers for Face Anti-Spoofing
目前基于多模态的人脸防伪算法存在两点不足:(1)基于多模态融合的方法要求提供与训练过程一致的模态样本,严重限制了算法的部署场景;(2)由于卷积操作挖掘视觉线索的挑战,基于ConvNet的模型对新出现的高保真攻击样本表现不佳。在本文工作中,我们提出了一基于纯Transformer的框架,称为灵活模态的Transformer(FM-ViT),用于人脸防伪任务,以借助多模态信息灵活地提升对任何单一模态攻击的识别性能。为了实现该目的,FM-ViT首先为每种模态保留一个特定的分支,以学习不同的模态信息。同时引入跨模态Transformer块(CMTB),由两个级联的注意力模块组成,分别称为Multi-headed Mutual-Attention(MMA)和Fusion-Attention(MFA),分别用于引导每个分支学习潜在的和模态无关的活性特征。
具体来说,如图1(a)所示,FM-ViT建立在多个ViT分支上,由token化模块、Transformer编码器和分类头组成。一个完整的Transformer编码器包含K个“阶段”。其中每个“阶段”由M个标准Transformer块(STB)和一个跨模态Transformer块(CMTB)堆叠。在每个“阶段”中,CMTB共享权值(用红色双箭头线显示),并接收之前多模态STBs的输出作为输入(用虚线显示)。如图1(b)所示,CMTB由两个级联的MMA和MFA组成。STBs与CMTB构成Transformer编码器的一个“阶段”。如图1(c)所示,MMA计算所有模态的相关图,以挖掘任意模态分支中潜在patch tokens;MFA为任意模态分支融合其他分支的模态信息,指导当前分支学习模态无关的活性特征。
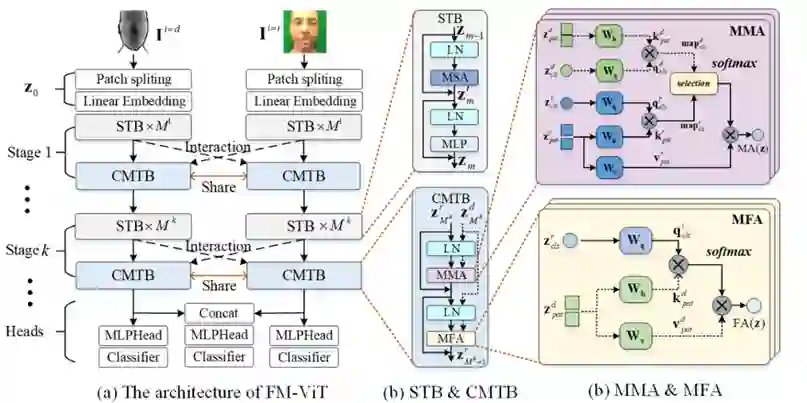
图. 一种基于灵活模态的人脸防伪方法示意图
作者:Ajian Liu, Zichang Tan, Jun Wan, Yanyan Liang, Zhen Lei, Guodong Guo, Stan Z. Li
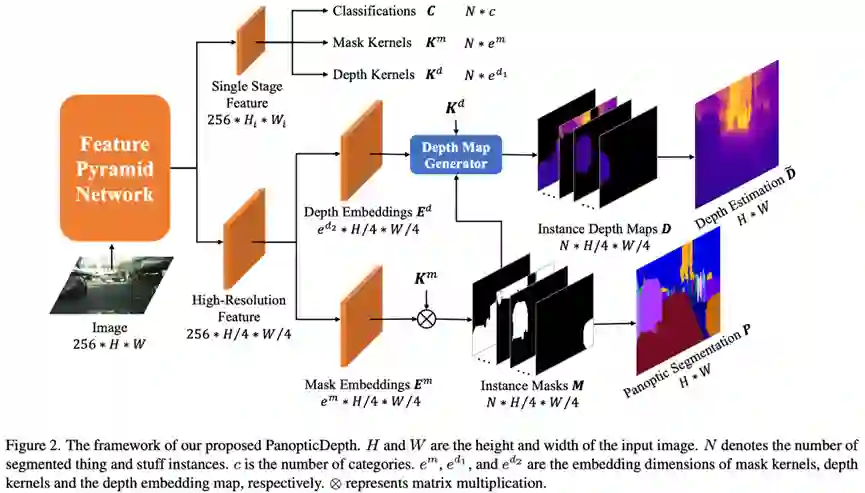
18. 基于实例深度估计的统一深度感知全景分割
PanopticDepth: Per-Instance Depth Estimation for Unified Depth-Aware Panoptic Segmentation
深度感知全景分割旨在从单幅图像的重建3D语义场景。现有方法直接对全景分割模型添加密集预测式单目深度估计分支解决此问题,在深度估计中仅考虑了像素级底层特征,缺乏对实例级几何信息的利用,实例掩码和深度估计方式的不统一也导致多任务间信息交互的不足。为克服这些限制,本工作探索了实例掩码和深度估计的联合建模问题,提出了更加统一的深度感知全景分割方法。该方法将对全图的深度估计分解至各个实例分别学习预测,并在模型推理阶段根据实例掩码组合在一起。同时,为了缓解不同实例间深度分布范围差异过大导致的实例间共享特征难以学习的问题,本工作将实例深度图进一步解耦为归一化实例深度图、实例深度缩放系数和实例深度偏移系数,并同时使用像素级和实例级监督信息指导深度估计的学习,通过减少搜索空间实现了算法性能的提升。实验结果表明,本工作所提出的方法在多个数据集上实现了相对基准方法更优的性能,尤其是显著提升了在前景物体上的掩码和深度估计性能,验证了方法的有效性。
作者:Naiyu Gao, Fei He, Jian Jia, Yanhu Shan, Haoyang Zhang, Xin Zhao, Kaiqi Huang

▲ CVPR 2022 | 自动化所新作速览!(上)
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2022” 就可以获取《【CVPR 2022】论文解读、代码、数据集等 》专知下载链接





