AAAI 2022 | 自动化所新作速览!

导读 | 在国际人工智能顶级会议AAAI 2022中,自动化所共有21篇论文被收录,本文将对部分论文进行简要梳理介绍,与各位共同交流领域前沿进展。
01
基于再查询机制的一体化多目标跟踪算法
One More Check: Making “Fake Background” Be Tracked Again
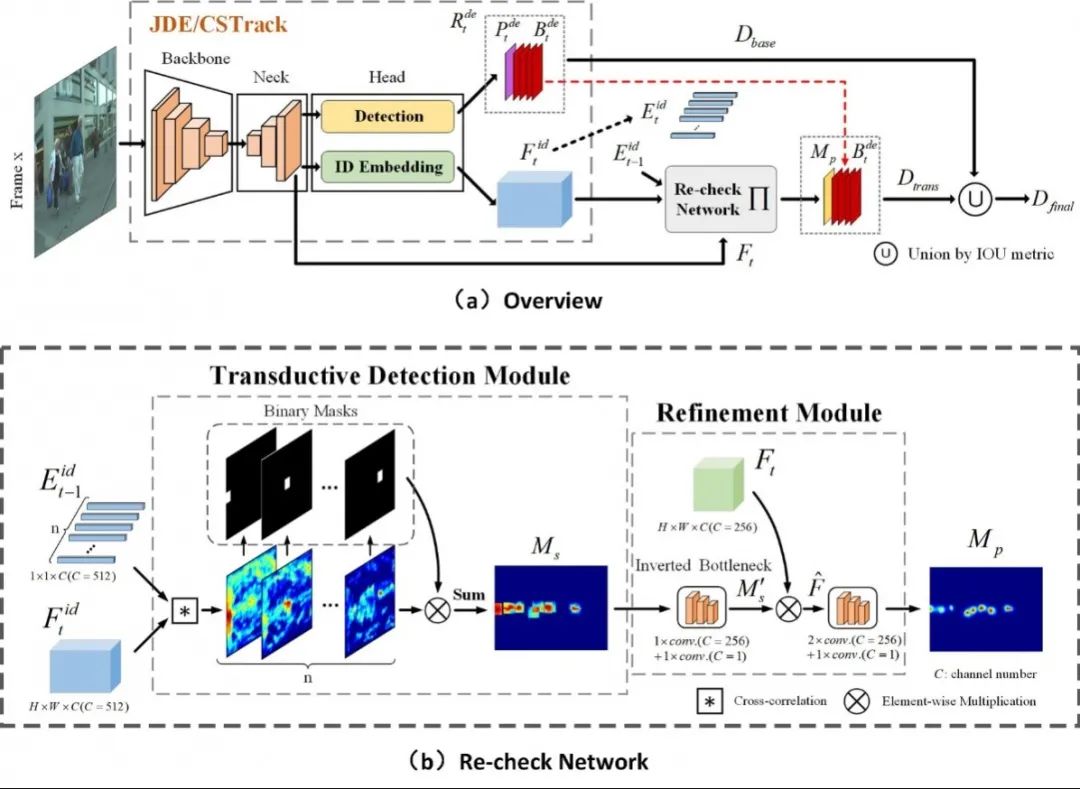
近年来,将检测和ReID统一到一个网络之中来完成多目标跟踪的方法取得了巨大的突破,且引起了研究人员的广泛关注。然而当前的一体化跟踪器仅依赖于单帧图片进行目标检测,在遇到一些现实场景的干扰,如运动模糊、目标相互遮挡时,往往容易失效。一旦检测方法因为特征的不可靠而将当前帧的目标错判成背景时,难免会破坏目标所对应的轨迹的连贯性。
在本文中,我们提出了一个再查询网络来召回被错分为“假背景”的目标框。该再查询网络创新性地将ID向量的功能从匹配扩展到运动预测,从而实现以较小的计算开销将已有目标的轨迹有效地传播到当前帧。而通过ID向量为媒介进行时序信息传播,所生成的迁移信息有效地防止了模型过度依赖于检测结果。因此,再查询网络有助于一体化方法召回“假背景”同时修复破碎的轨迹。
基于已有的一体化方法CSTrack,本文构建了一个新颖且高性能的一体化跟踪器,其在MOT16和MOT17两个基准上分别取得了巨大的增益,即相比于CSTrack,MOTA分数从70.7/70.6提高到76.4/76.3。此外,它还取得了新SOTA的MOTA和IDF1性能。
其代码已开源在:
https://github.com/JudasDie/SOTS
作者:Chao Liang , Zhipeng Zhang , Xue Zhou, Bing Li, Weiming Hu
02
从目标中学习: 用于小样本语义分割的双原型网络
Learning from the Target: Dual Prototype Network for Few Shot Semantic Segmentation
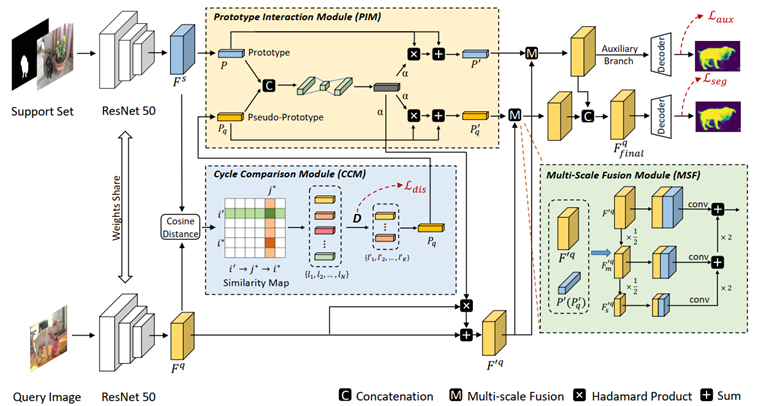
由于标注样本的稀缺,支持集和查询集之间的样本差异(目标的外观,尺寸,视角等)成为小样本语义分割的主要难点。现有的基于原型的方法大多只从支持集特征中挖掘原型,而忽略了利用来自查询集样本的信息,因此无法解决这个由样本间差异带来的痛点。
在本文中,我们提出了一种双原型网络 (DPNet),它从一个新颖的角度来处理小样本语义分割问题,即在从支持集中提取原型的基础上,进一步提出了从查询图像中提取可靠的前景信息作为伪原型。
为了实现这一目的,我们设计了循环比较模块,通过两次匹配过程筛选出符合要求的前景查询特征,并利用这些前景特征生成伪原型。然后根据原型与伪原型之间的内在关联,利用原型交互模块对原型与伪原型的信息进行交互整合。最后,引入一个多尺度融合模块,在原型(伪原型)与查询特征的密集比较过程中引入上下文信息,以获得更好的分割结果。
在两个标准数据集 (PASCAL-5i, COCO-20i)上进行的大量实验表明,我们的方法取得了优越的性能,证明了提出方法的有效性。
作者:Binjie Mao,Xinbang Zhang,Lingfeng Wang,Qian Zhang, Shiming Xiang, Chunhong Pan
DPNet的网络框架图
03
基于模态特定信息增强的多模态行人重识别
Interact, Embed, and EnlargE (IEEE): Boosting Modality-specific Representations for Multi-Modal Person Re-identification
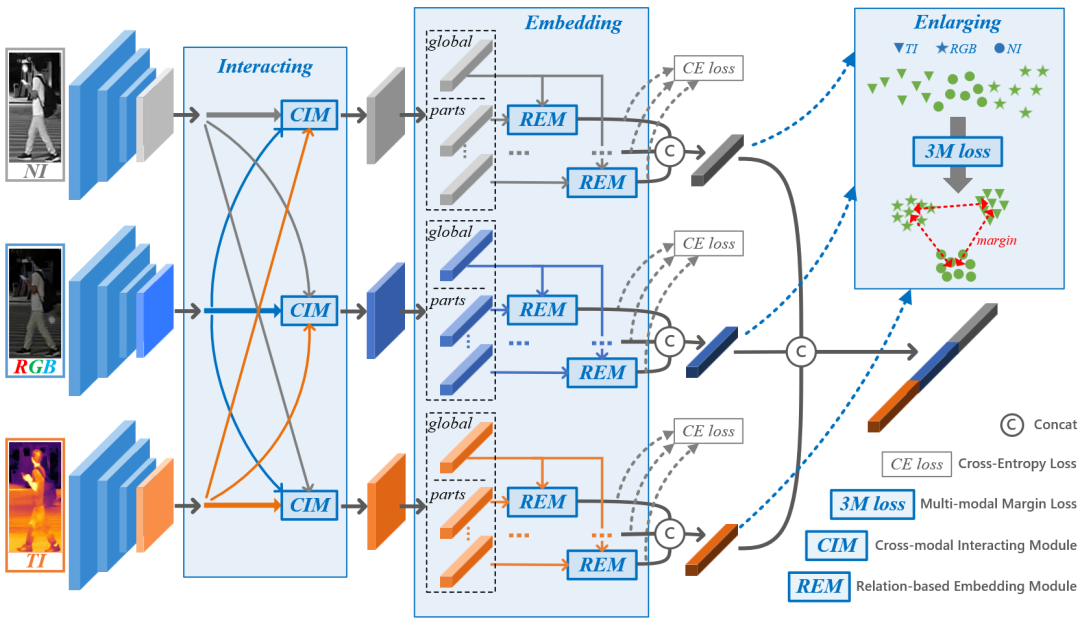
多模态行人重识别通过引入模态互补信息来辅助传统的单模态重识别任务。现有的多模态方法在融合不同模态特征的过程中忽略模态特异信息的重要性。为此,我们提出了一种新方法来增强多模态行人重识别的模态特定信息表示 (IEEE) :交互 (Interact) 、嵌入 (Embed) 和扩大 (EnlargE) 。
首先,提出了一种新颖的跨模态交互模块,用于在特征提取阶段在不同模态之间交换有用的信息。其次,提出了一种基于关系的嵌入模块,通过将全局特征嵌入到细粒度的局部信息中来增强模态特异特征的丰富度。最后,提出了一种新颖的多模态边界损失,通过扩大类内不同模态的差异来迫使网络学习每种模态的模态特定信息。在真实的和构建的行人重识别数据集上优越性验证了所提出方法的有效性。
作者:Zi Wang, Chenglong Li, Aihua Zheng, Ran He, Jin Tang
04
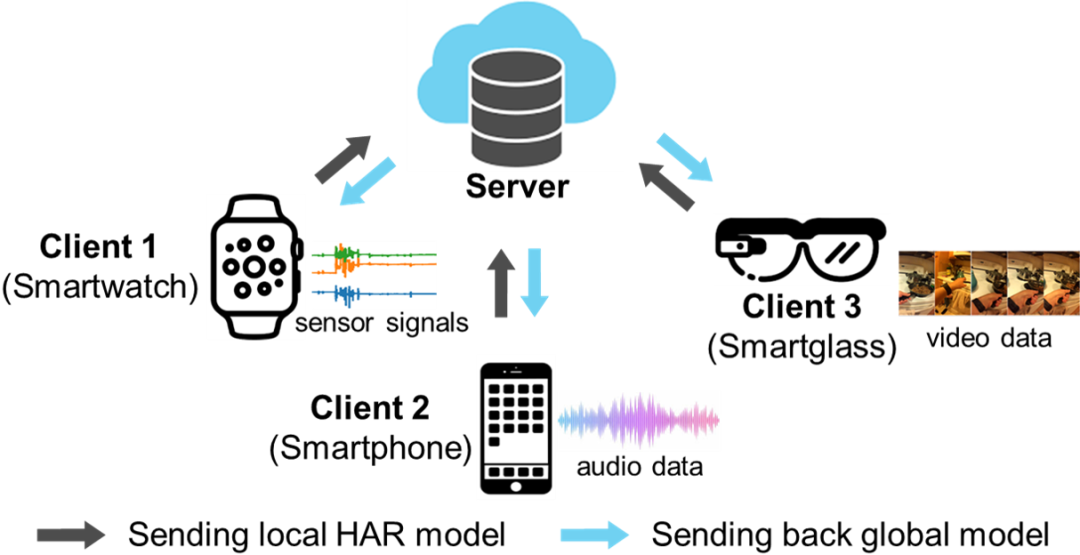
面向人体活动识别的跨模态联邦学习
Cross-Modal Federated Human Activity Recognition via Modality-Agnostic and Modality-Specific Representation Learning
为了在更多本地客户端上进行人体活动识别,我们提出一个新的面向人体活动识别的跨模态联邦学习任务。为了解决这一新问题,我们提出一种特征解纠缠的活动识别网络(FDARN),模型由共有特征编码器、私有特征编码器、模态判别器、共享活动分类器和私有活动分类器五个模块组成。
共有特征编码器的目标是协同学习不同客户端样本的模态无关特征;私有特征编码器旨在学习不能在客户端之间共享的模态独有特征;模态鉴别器的作用是以对抗学习的方式指导共有特征编码器和私有特征编码器的参数学习。
通过采用球面模态判别损失的去中心化优化,我们提出的方法可以综合利用模态无关的客户端共享特征以及模态特有的判别特征,因此可以得到在不同客户端上具有更强泛化能力的模型。在四个数据集上的实验结果充分表明了该方法的有效性。
作者:Xiaoshan Yang, Baochen Xiong, Yi Huang, Changsheng Xu
05
Evo-ViT:基于快速-慢速双流更新的视觉Transformer动态加速策略
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
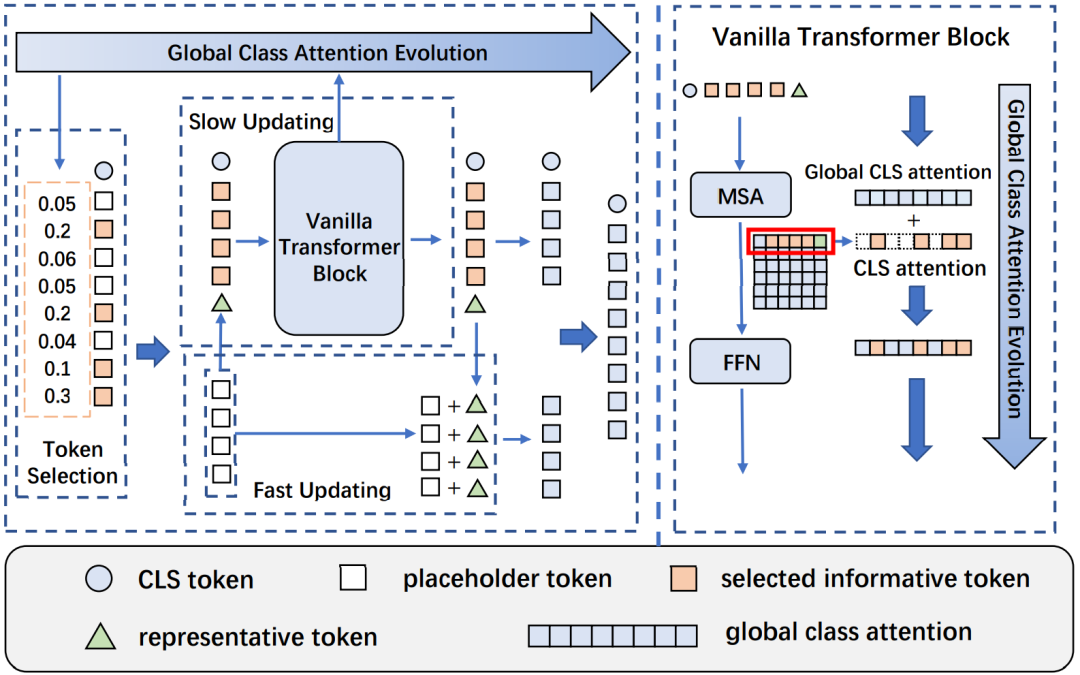
视觉Transformer通过自注意力机制捕获长程视觉依赖的能力使其在各种计算机视觉任务中显示出巨大的潜力,但是长程感受野同样带来了巨大的计算开销,特别是对于高分辨率视觉任务。为了能够在尽量保持原有模型准确率的前提下,降低模型计算复杂度,从而使得视觉 Transformer成为一种更加通用、高效、低廉的解决框架,目前工作分为基于空间结构先验的结构化压缩和非结构化特征裁剪两个主流方向。其中,非结构化的特征裁剪破坏了二维空间结构,使得这类裁剪方法不能适用于基于空间结构先验的结构化压缩的模型,而目前主流的先进视觉Transformer都应用了结构化压缩。此外,直接裁剪带来的不完整的信息流使得目前的特征裁剪方法无法直接训练得到很好的效果,而要依赖于未裁剪的预训练模型。
为了解决这些问题,我们提出了快速-慢速双流标识更新策略,在保持了完整空间结构的同时给高信息量标识和低信息量标识分配不同的计算通道,从而在不改变网络结构的情况下,以极低的精度损失大幅提升直筒状和金字塔压缩型的Transformer模型推理性能。不同于以往方法需要依靠外部的可学习网络来对每一层的标识进行选择,我们进一步提出了基于Transformer原生的全局类注意力的标识选择策略来增强层间的通信联系,从而使得我们的方法可以在稳定标识选择的同时去除了外部可学习参数带来的直接训练难的问题。
该算法能够在保证分类准确率损失较小的情况下,大幅提升各种结构Transformer的推理速度,如在ImageNet-1K数据集下,Evo-ViT可以提升DeiT-S 60%推理速度的同时仅仅损失0.4%的精度。
作者:Yifan Xu, Zhijie Zhang, Mengdan Zhang, Kekai Sheng, Ke Li, Weiming Dong, Liqing Zhang, Changsheng Xu, Xing Sun
06
基于图卷积网络及热力图回归的3D人脸关键点检测
Learning to detect 3D facial landmarks via heatmap regression with Graph Convolutional Network
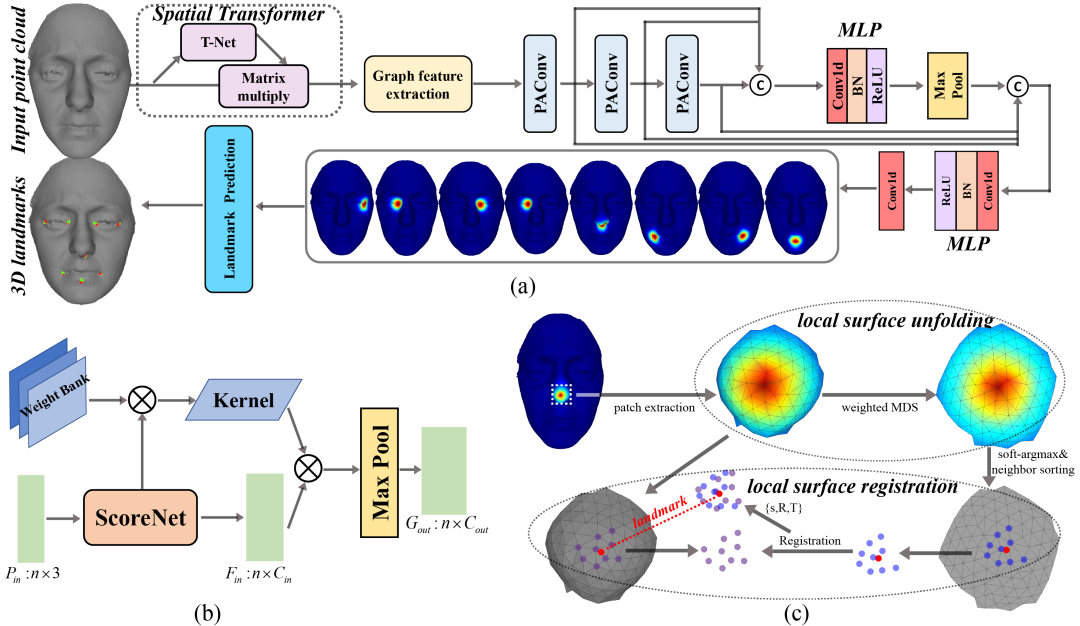
三维人脸关键点检测广泛应用于人脸配准、人脸形状分析、人脸识别等多个研究领域。现有的关键点检测方法大多涉及传统特征和三维人脸模型(3DMM),其性能受限于手工制作的中间表征量。
本文提出了一种新的三维人脸关键点检测的方法,该方法利用精心设计的图卷积网络,直接从三维点云中定位关键点的坐标。热力图是三维人脸上每个地标距离的高斯函数,图卷积网络在构建的三维热力图的帮助下可以自适应学习几何特征,用于三维人脸关键点检测。在此基础上,我们进一步探索了局部曲面展开与曲面配准模块,从3D热力图中直接回归3D坐标。
实验证明,该方法在BU-3DFE和FRGC数据集上的关键点定位精度和稳定性明显优于现有方法,并在最近的大规模数据集FaceScape上取得了较高的检测精度。
作者:YuanWang, Min Cao, Zhenfeng Fan, Silong Peng
07
基于因果关联及混杂因子传递解耦物理动力学的反事实预测
Deconfounding Physical Dynamics with Global Causal Relation and Confounder Transmission for Counterfactual Prediction
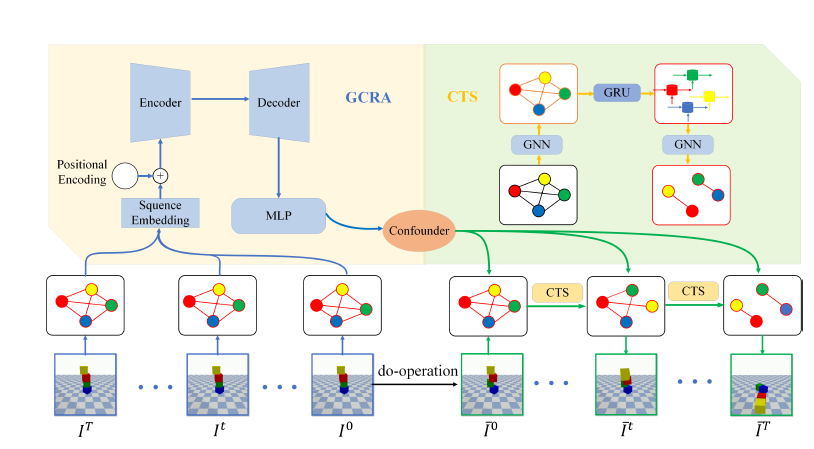
发现潜在的因果关系是推理周围环境和预测物理世界未来状态的基础能力。基于视觉输入的反事实预测根据过去未出现的情况推断未来状态,是因果关系任务中的重要组成部分。
本文研究了物理动力学中的混杂影响因子,包括质量、摩擦系数等,建立干预变量和未来状态之间的关联关系,进而提出了一种包含全局因果关系注意力(GCRA)和混杂因子传输结构(CTS)的神经网络框架。GCRA寻找不同变量之间的潜在因果关联,通过捕获空域和时序信息来估计混杂因子。CTS以残差的方式整合和传输学习到的混杂因子,在反事实预测过程中,通过编码对网络中对象位置进行约束。
实验证明,在混杂因子真实值未知的情况下,本文的方法能够充分学习并利用混杂因子形成的约束,在相关数据集的预测任务上取得了目前最优的性能,并可以较好地泛化到新的环境,实现良好的预测精度。
作者:Zongzhao Li, Xiangyu Zhu, Zhen Lei(Corresponding author), Zhaoxiang Zhang
08
基于多相机系统的全局运动平均算法
MMA: Multi-camera Based Global Motion Averaging
为了实现三维场景的完全感知,在自动驾驶汽车和智能机器人等设备中通常会安装多相机系统以观察周围360度的场景。基于多相机之间刚性固定的约束,我们提出了一种全局式的多相机运动平均算法,以实现全自动的大规模场景快速鲁棒建模和多相机标定。
首先,根据拍摄相机的不同将图像分为参考图像和非参考图像,进而将场景图中的边划分成四类。针对每一类边上的多相机相对极几何约束,我们进行了重新的推导和展示。基于相对旋转和绝对旋转之间的约束,我们提出了一种基于多相机的旋转平均算法,并通过一种两阶段(L1+IRLS)的方式对它进行求解。基于相对平移和绝对位置之间的约束,我们提出了一种基于多相机的平移平均算法,通过求解L1范数下的优化方程获得所有的摄像机位姿。
我们在公开的自动驾驶数据集和多组自采的多相机数据集上进行了广泛的测试和对比,显示我们的建模精度和鲁棒性要远远好于传统方法。
作者:Hainan Cui, Shuhan Shen

09
基于解耦的属性特征的鲁棒的行人属性识别
Learning Disentangled Attribute Representations for Robust Pedestrian Attribute Recognition
尽管学界已经提出了各种行人属性识别的方法,但大多数研究都遵循相同的特征学习机制,即学习一个共享的行人图像特征来对多个属性进行分类。然而,这种机制导致了推理阶段的低可信度预测和模型的非稳健性。
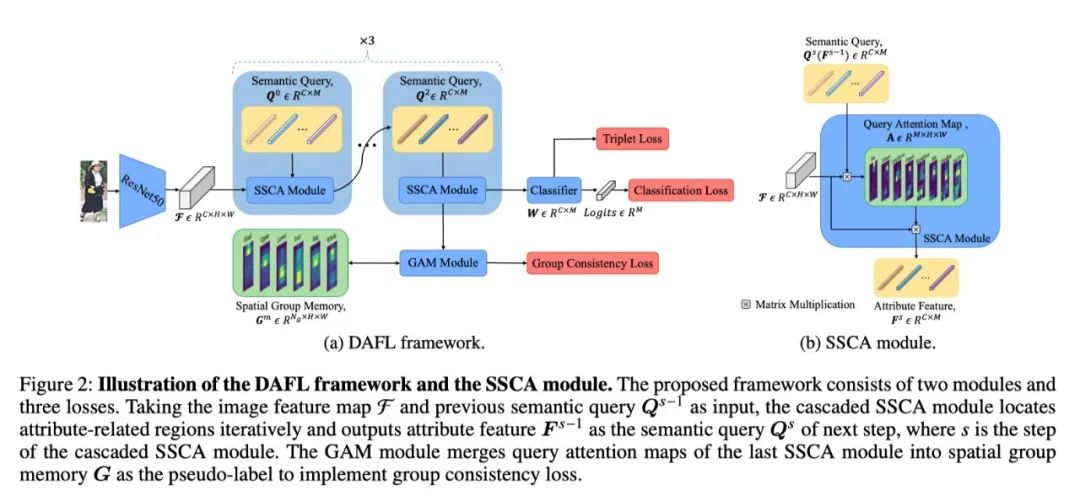
在本文中,我们研究了为什么会出现这种情况。我们从数学上发现,核心原因是在最小化分类损失的情况下,最佳共享特征不能同时与多个分类器保持高相似度。此外,这种特征学习机制忽略了不同属性之间的空间和语义区别。
为了解决这些局限性,我们提出了一个新颖的分离属性特征学习(DAFL)框架,为每个属性学习一个分离的特征,该框架利用了属性的语义和空间特征。该框架主要由可学习的语义查询、级联式语义空间交叉注意(SSCA)模块和群体注意合并(GAM)模块组成。具体来说,基于可学习语义查询,级联式SSCA模块迭代地增强了属性相关区域的空间定位,并将区域特征聚合为多个分解的属性特征,用于分类和更新可学习语义查询。GAM模块根据空间分布将属性分成小组,并利用可靠的小组注意力来监督查询注意力图。在PETA、RAPv1、PA100k和RAPv2上的实验表明,所提出的方法与最先进的方法相比表现良好。
作者:Jian Jia, Naiyu Gao, Fei He, Xiaotang Chen, Kaiqi Huang
10
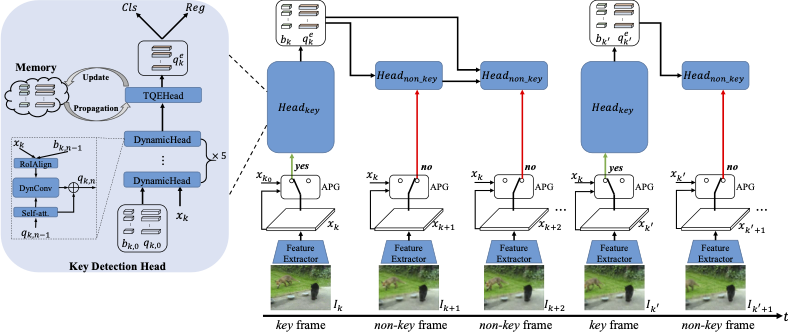
基于对象查询传播的高性能视频物体检测
QueryProp: Object Query Propagation for High-Performance Video Object Detection
视频物体检测旨找出视频每一帧中包含物体的位置和类别,是一个重要且具有挑战性的任务。传统方法主要聚焦于设计图像级别或者物体框级别的相邻帧信息传播方法,以利用视频时序信息来提升检测器。本文认为,通过更有效和高效的特征传播框架,视频物体检测器可以在准确性和速度方面获得提升。
为此,本文研究了对象级特征传播,并提出了一种用于高性能视频物体检测的对象查询传播(QueryProp)框架。提出的QueryProp包含两种传播策略:1)对象查询从稀疏关键帧传播至密集非关键帧,以减少对非关键帧的冗余计算;2)对象查询从之前的关键帧传播至当前关键帧,以建模时间上下文来提升特征表示。
为了进一步提升查询传播的质量,我们设计了自适应传播门以实现灵活的关键帧选择。我们在视频物体检测的大规模数据集 ImageNet VID 上进行了大量实验。QueryProp 与当前最先进的方法实现了可比的准确性,并在准确性/速度之间取得了不错的平衡。
作者:Fei He, Naiyu Gao, Jian Jia, Xin Zhao, Kaiqi Huang
11
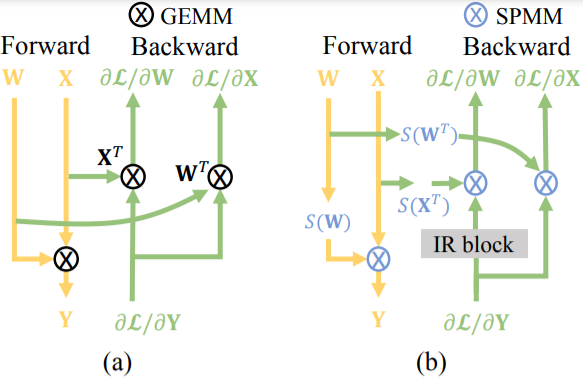
基于空间相似性的完全稀疏训练加速
Towards Fully Sparse Training: Information Restoration with Spatial Similarity
英伟达安培架构发布的2:4结构化稀疏模式,要求连续的四个值至少包含两个零元素,可以使得矩阵乘法的计算吞吐量翻倍。最近的工作主要集中在通过2:4稀疏性来提高推理速度,而忽视了其在训练加速方面的潜力,因为反向传播占据了大约70%的训练时间。然而,与推理阶段不同,由于需要保持梯度的保真度并减少在线执行2:4稀疏的额外开销,用结构化剪枝来提高训练速度是不容易的。
本文首次提出了完全稀疏训练,其中"完全"是指在保持精度的同时,对前向和后向传播的所有矩阵乘法进行结构化修剪。为此,我们从显著性分析开始,研究不同的稀疏对象对结构化修剪的敏感性。基于对激活的空间相似性的观察,我们提出用固定的2:4掩码来修剪激活。此外,我们还提出了一个信息恢复模块来恢复丢失的信息,该模块可以通过有效的梯度移位操作来实现。对准确性和效率的评估表明,在具有挑战性的大规模分类和检测任务中,我们可以实现2倍的训练加速,而准确性的下降可以忽略不计。
作者:Weixiang Xu, Xiangyu He, Ke Cheng, Peisong Wang, Jian Cheng
12
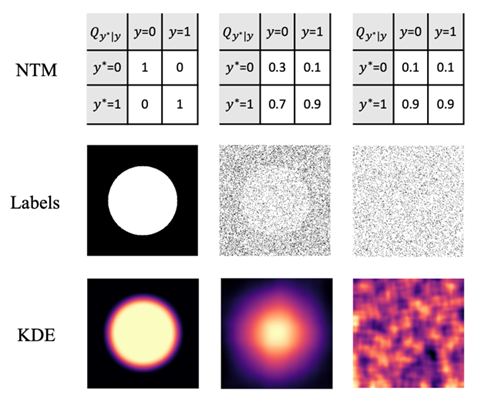
通过学习深度神经网络在语义分割中学习噪声标签的元结构
Deep Neural Networks Learn Meta-Structures from Noisy Labels in Semantic Segmentatio
关于深度神经网络(DNN)如何从带噪标签中进行学习,大部分研究聚焦于图像分类而不是语义分割。迄今为止,我们对于深度神经网络在噪声分割标签下的学习行为仍然知之甚少。
在本研究中,为填补这一空白,我们研究了生物显微图像的二类语义分割和自然场景图像下的多类语义分割。通过从干净标签中随机抽样一小部分(例如10%)或随机翻转一大部分(例如90%)像素标签,我们合成了信噪比极低的噪声标签。当使用这些低信噪比标签训练DNN时,我们发现模型的分割性能几乎没有下降。这表明DNN在基于监督学习的语义分割中是从标签中学习语义类别的结构信息,而不仅仅是像素信息。我们将上述标签中隐含的结构信息称为元结构。当我们对标签中的元结构进行不同程度的扰动,我们发现模型的分割性能出现不同程度的下降。而当我们在标签中融入元结构时,可以极大提高基于无监督学习的二类语义分割模型的性能。我们将元结构在数学上定义为点集的空间分布函数,并在理论上和实验中证明该数学模型可以很好的解释我们在本研究中观察到的深度神经网络的学习行为。
作者:Yaoru Luo, Guole Liu, Yuanhao Guo, Ge Yang
01
基于参数分化的多语言神经机器翻译
Parameter Differentiation based Multilingual Neural Machine Translation
多语言神经机器翻译旨在通过一个共享的模型同时处理多个语言的翻译,并通过共享的参数实现不同语言之间的知识迁移。但是,模型中哪些参数需要共享,哪些参数是语言独有的,仍是一个开放性问题。目前,通常的做法是启发式地设计或者搜索语言特定地模块,但很难找到一个最优的参数共享策略。
在本文中,我们提出一个新颖的基于参数分化的方法,该方法允许模型在训练的过程中决定哪些参数应该是语言特定的。受到细胞分化的启发,在我们的方法中,每个通用的参数都可以动态分化为语言特定的参数。我们进一步将参数分化准则定义为任务间梯度相似性。如果一个参数上不同任务的梯度出现冲突,那么这个参数更有可能分化为语言特定的类型。在多语言数据集上的实验表明我们的方法相比于基线方法取得了较大的提升。分析实验进一步揭示了我们的方法生成的参数共享策略和语言学特征的相似性具有紧密的关系。
作者:Qian Wang, Jiajun Zhang
02
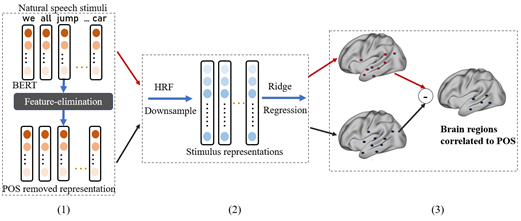
基于特征消除方法的大脑词汇语法表征研究
Probing Word Syntactic Representations in the Brain by a Feature Elimination Method
神经影像研究发现大脑在理解语言时,多个脑区与语义和语法处理相关。然而,现有的方法不能探索词性和依存关系等细粒度词汇语法特征的神经基础。
本文提出了一种新的框架来研究不同词汇语法特征在大脑中的表征。为了分离不同句法特征,我们提出了一种特征消除方法——均值向量零空间投影(MVNP),来消除词向量中的某一特征。然后,我们分别将消除某一特征的词向量和原始词向量与大脑成像数据联系起来,以探索大脑如何表示被消除的特征。本文首次在同一实验中同时研究了多个细粒度语法特征的皮层表征,并提出了多个脑区在语法处理分工中的可能贡献。这些发现表明,语法信息处理的大脑基础可能比经典研究所涉及的更为广泛。
作者:Xiaohan Zhang, Shaonan Wang, Nan Lin, Jiajun Zhang, Chengqing Zong
01
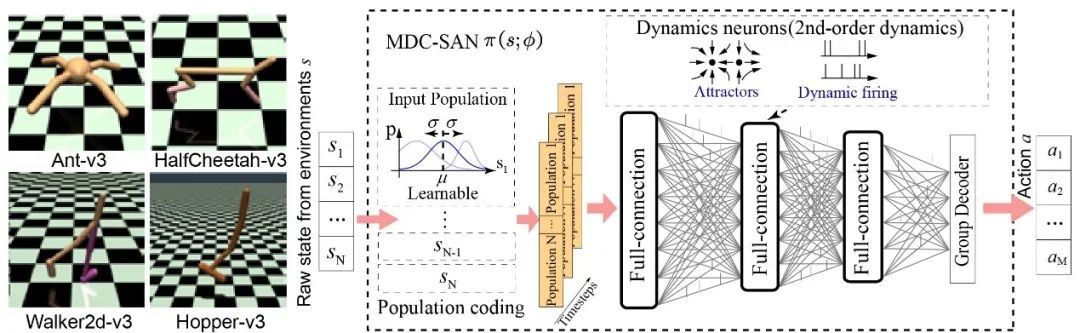
多尺度动态编码助力脉冲网络实现高效强化学习
Multi-scale Dynamic Coding improved Spiking Actor Network for Reinforcement Learning
在深度神经网络(DNN)的帮助下,深度强化学习 (DRL) 在许多复杂任务上取得了巨大成功,如游戏任务和机器人控制任务。DNN被认为只是部分受到了大脑结构和功能的启发,与之相比,脉冲神经网络 (Spiking Neural Network,SNN) 考虑了更多的生物细节,包括具有复杂动力学的脉冲神经元和生物合理的可塑性学习方法。
受生物大脑中细胞集群(Cell Assembly)高效计算的启发,我们提出了一种多尺度动态编码方法来提升脉冲人工网络(MDC-SAN)模型,并应用于强化学习以实现高效决策。多尺度表现为网络尺度的群体编码和神经元尺度的动态神经元编码(包含二阶神经元动力学),可以帮助SNN形成更加强大的时空状态空间表示。大量实验结果表明,我们的 MDC-SAN 在 OpenAI Gym的四个连续控制任务上取得了相比无编码SNN和相同参数下DNN更好的性能。
我们认为这是一次从生物高效编码角度探讨网络性能提升的有效尝试,就像在生物网络中一样,前期的复杂化信息编码可以让后期的智能决策变得更简单。
作者:Duzhen Zhang, Tielin Zhang, Shuncheng Jia, Bo Xu
详细解读
点击即可查看
AAAI 2022 | 多尺度动态编码助力脉冲网络实现高效强化学习
02
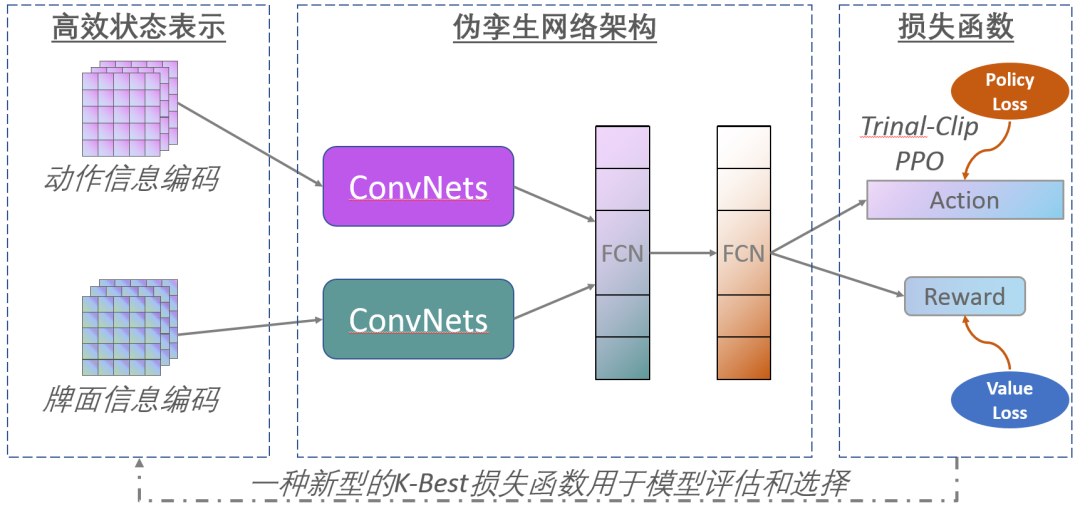
AlphaHoldem: 端到端强化学习驱动的高性能两人无限注扑克人工智能
AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Poker via End-to-End Reinforcement Learning
无限注德州扑克(HUNL)是一个典型的不完美信息博弈。之前的代表性工作如DeepStack和Libratus严重依赖于反事实遗憾最小化(CFR)算法及其变体来求解。然而,由于CFR迭代的计算成本高昂,使得后续研究人员很难在HUNL中学习CFR模型,并将该算法应用于其他实际问题。
在这项工作中,我们提出了一个高性能和轻量级的德州扑克人工智能AlphaHoldem。AlphaHolddem是一种端到端的自学习强化学习框架,采用了一种伪孪生网络结构,通过将学习到的模型与不同的历史版本进行对打,直接从输入状态信息学习到输出的动作。
文章的主要技术贡献包括一种新的手牌和投注信息的状态表示、一种多任务的自我游戏训练损失函数,以及一种新的模型评估和选择度量来生成最终的模型。在10万手扑克的研究中,AlphaHoldem只用了三天的训练就击败了Slumbot和DeepStack。与此同时,AlphaHoldem只使用一个CPU核心进行每个决策仅需要4毫秒,比DeepStack快1000多倍。我们将提供一个在线开放测试平台,以促进在这个方向上的进一步研究。
作者:Enmin Zhao, Renye Yan, Jinqiu Li, Kai Li, Junliang Xing
详细解读
点击即可查看
人类专业玩家水平!自动化所研发轻量型德州扑克AI程序AlphaHoldem
03
AutoCFR:通过学习设计反事实后悔值最小化算法
AutoCFR: Learning to Design Counterfactual Regret Minimization Algorithms
反事实遗憾最小化(Counterfactual Regret Minimization, CFR)算法是最常用的近似求解两人零和不完美信息博弈的算法。近年来,人们提出了一系列新的CFR变体如CFR+、Lienar CFR、DCFR,显著提高了朴素CFR算法的收敛速度。然而,这些新的变体大多是由研究人员基于不同的动机通过反复试错来手工设计的,通常需要花费大量和时间精力和洞察力。
这项工作提出采用演化学习来元学习新的CFR算法,从而减轻人工设计算法的负担。我们首先设计了一种丰富的搜素语言来表示现有的手工设计的CFR变体。然后我们利用可扩展的演化算法以及一系列加速技术,在这种语言所定义的算法的组合空间中进行高效地搜索。学习到的新的CFR算法可以泛化到训练期间没有见过的新的不完美信息博弈游戏下,并与现有的的最先进的CFR变体表现相当或更好。
作者:Hang Xu, Kai Li, Haobo Fu, Qiang Fu, Junliang Xing

04
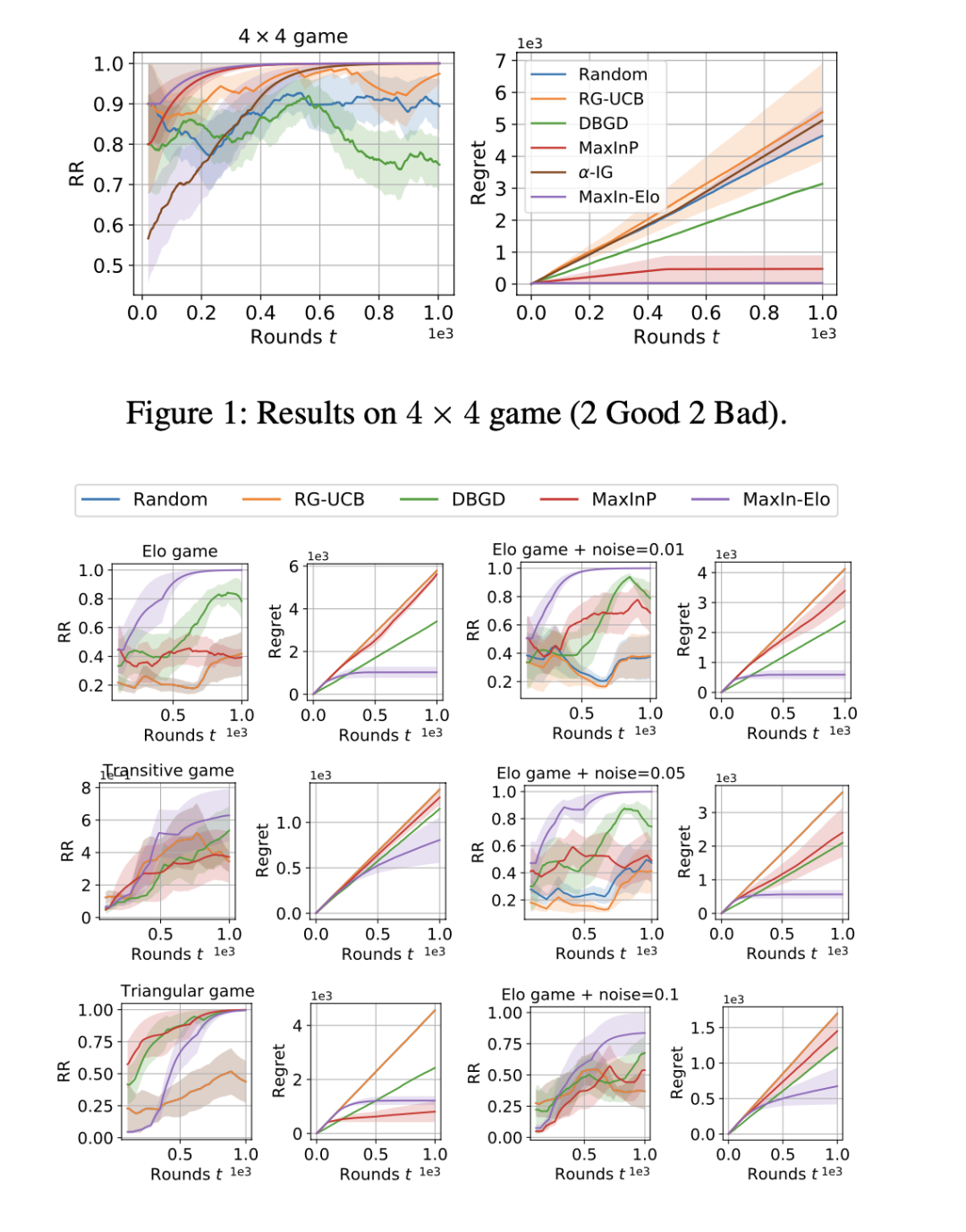
基于对战老虎机方法学习顶级Elo评级
Learning to Identify Top Elo Ratings as A Dueling Bandits Problem
Elo 评分系统被广泛用于评估(国际象棋)游戏和体育竞技中玩家的技能。最近,它还被集成到机器学习算法中,用于评估计算机化的 AI 智能体的性能。然而,准确估计 Elo 等级分(对于顶级玩家)通常需要较多轮比赛,而采集多轮对战信息的代价可能是昂贵的。
在本文中,为了尽量减少比较次数并提高 Elo 评估的样本效率(针对顶级玩家),我们提出了一种高效的在线匹配调度算法。具体来说,我们通过对战老虎机(dueling bandits)框架识别和匹配顶级玩家,并根据 Elo 基于梯度的更新方式来设计老虎机算法。我们表明,与传统的需要 O(t) 时间的最大似然估计相比,我们能够将每步内存和时间复杂度降低到常数。我们的算法有一个遗憾(regret)保证 O ̃(√T) (O ̃忽略对数因子),与比赛轮数是次线性相关。并且算法已经被扩展到处理非传递性游戏的多维 Elo 评级。实验结果证明我们的方法在各种游戏任务上实现了较优的收敛速度和时间效率。
作者:Xue Yan, Yali Du, Binxin Ru, Jun Wang, Haifeng Zhang, Xu Chen
05
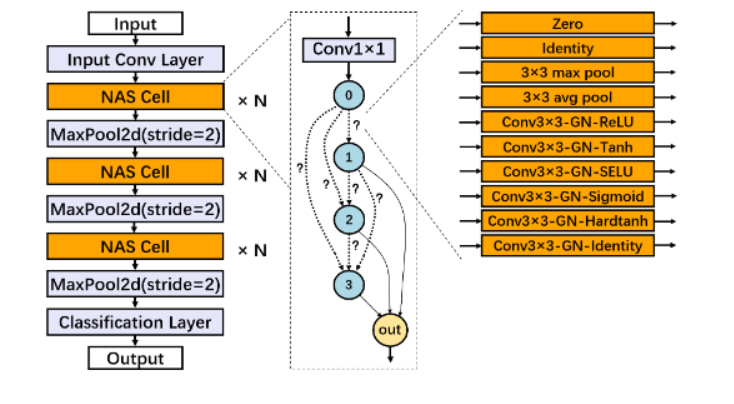
DPNAS:面向差分隐私深度学习的神经网络结构搜索
DPNAS:Neural Architecture Search for Deep Learning with Differential Privacy
在保证有意义的差分隐私(DP)条件下训练深度神经网络(DNN)通常会严重降低模型的精度。在本文中我们指出,在面向隐私保护的深度学习中,DNN的拓扑结构对训练得到的模型精度有显著影响,而这种影响在以前的研究中基本未被探索。
鉴于这一缺失,我们提出了第一个面向隐私保护深度学习的神经网络设计框架DPNAS。该框架采用神经网络架构搜索来自动设计隐私保护深度学习模型。为了将隐私保护学习方法与网络架构搜索相结合,我们精心设计了一个新的搜索空间,并提出了一种基于DP的候选模型训练方法。我们通过实验证明了所提出框架的有效性。搜索得到的模型DPNASNet实现了最先进的隐私/效用权衡,例如,在(ϵ,δ)=(3,1×10^-5)的隐私预算下,我们的模型在MNIST上的测试准确率为98.57%,在FashionMNIST上的测试准确率为88.09%,在CIFAR-10上的测试准确率为68.33%。此外,通过研究生成的网络结构,我们提供了一些关于隐私保护学习友好的DNN的有趣发现,这可以为满足差分隐私的深度学习模型设计提供新的思路。
作者:Anda Cheng, Jiaxing Wang, Xi Sheryl Zhang, Qiang Chen, Peisong Wang, Jian Cheng
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。



