
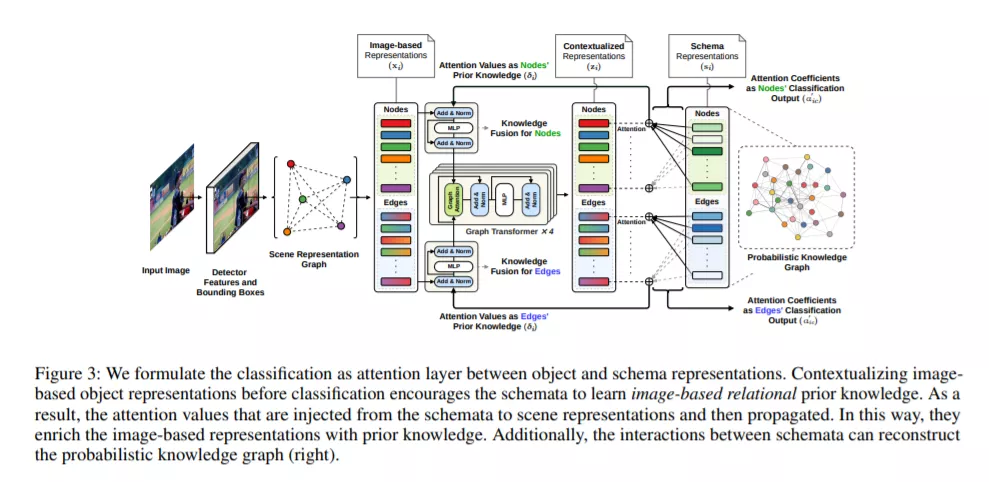
在场景图分类的一个主要挑战是,物体的外观和关系可以明显不同于另一幅图像。以前的工作通过对图像中所有物体的关系推理,或将先验知识纳入分类来解决这个问题。与之前的工作不同,我们不考虑感知和先验知识的分离模型。相反,我们采用多任务学习方法,其中分类被实现为一个注意力层。这允许先验知识在感知模型中出现和传播。通过使模型也代表先验,我们实现了归纳偏差。我们表明,我们的模型可以准确地生成常识性知识,并且将这些知识迭代注入到场景表示中可以显著提高分类性能。此外,我们的模型可以根据作为三元组的外部知识进行微调。当与自监督学习相结合时,这将获得仅对1%的带注释的图像进行准确的预测。
成为VIP会员查看完整内容
相关内容
Arxiv
7+阅读 · 2019年6月14日
相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年6月14日