大型语言模型(LLMs),如ChatGPT和LLaMA,正因其强大的文本编解码能力和新发现的突现能力(例如,推理)在自然语言处理领域创造重大进展。虽然LLMs主要设计用于处理纯文本,但在许多现实世界场景中,文本数据与图形(例如,学术网络和电子商务网络)形式的丰富结构信息相关联,或者图形数据与丰富的文本信息(例如,带有描述的分子)配对。此外,尽管LLMs已展示其基于纯文本的推理能力,但是否可以将此能力泛化到图形场景(即基于图的推理)尚未得到充分探索。在本文中,我们提供了关于图上大型语言模型的场景和技术的系统综述。我们首先将采用图上LLMs的潜在场景归纳为三类,即纯图,文本丰富的图,以及与文本配对的图。然后,我们讨论了在图上使用LLMs的详细技术,包括将LLM作为预测器、编码器和对齐器,并比较了不同模型类别的优缺点。此外,我们还提到了这些方法的实际应用,并总结了开源代码和基准数据集。最后,我们总结了这一快速发展领域未来的潜在研究方向。相关源码可以在此处找到:https://github.com/PeterGriffinJin/Awesome-Language-Model-on-Graphs。https://www.zhuanzhi.ai/paper/4361cf9d534dbfbd91be3d22f7ebc742
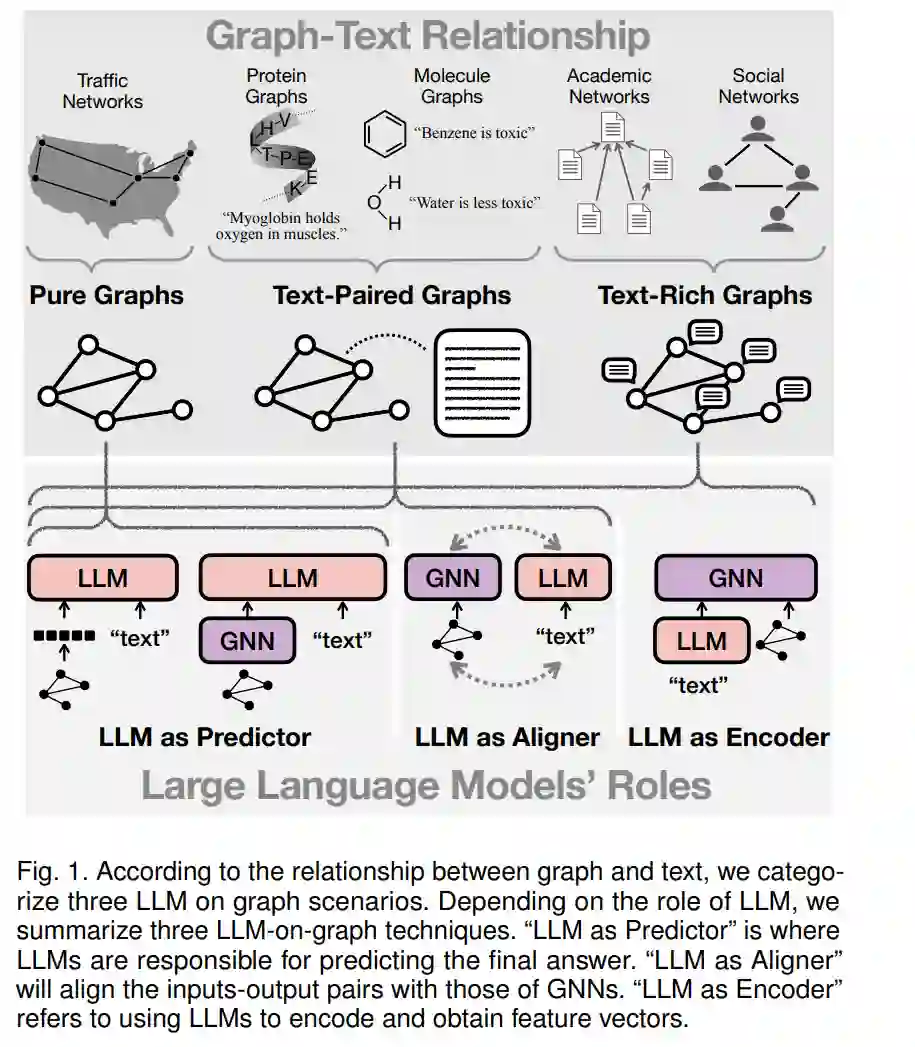
大型语言模型(LLMs)(例如,BERT [22]、T5 [30]、LLaMA [119])经过在非常大的文本语料库上的预训练,已被证明在解决自然语言处理(NLP)任务方面非常强大,包括问题回答 [1]、文本生成 [2] 和文档理解 [3]。早期的LLMs(例如,BERT [22]、RoBERTa [23])采用仅编码器架构,并主要应用于文本表示学习 [4] 和自然语言理解 [3]。近年来,越来越多的关注被放在了仅解码器架构 [119] 或编码器-解码器架构 [30] 上。随着模型规模的扩大,这样的LLMs也展示了推理能力甚至更先进的突现能力 [5],展现了对人工通用智能(AGI)的强大潜力。 虽然LLMs广泛应用于处理纯文本,但越来越多的应用场景中,文本数据与以图形形式呈现的结构信息相关联。如图1所示,在学术网络中,论文(带有标题和描述)和作者(带有个人简介文本)通过作者关系相互连接。理解这些图上作者/论文的文本信息以及作者-论文结构信息可以有助于更先进的作者/论文建模和精准的合作推荐;在科学领域,分子以图形表示,并通常与描述其基本信息的文本(例如,毒性)配对。同时建模分子结构(图)和相关的丰富知识(文本)对于更深入的分子理解非常重要。由于LLMs主要用于建模顺序排列的文本,上述场景提出了新的挑战,即如何使LLMs能够编码图上的结构信息。此外,由于LLMs已展示了其卓越的基于文本的推理能力,探索它们是否有潜力解决纯图上的基本图推理问题是有前景的。这些图推理任务包括推断连通性 [6]、最短路径 [7] 和子图匹配 [8]。最近,扩展LLMs用于基于图的应用(如图1所总结)引起了越来越多的兴趣。根据图1所呈现的图与文本之间的关系,应用场景可以归类为纯图、文本丰富的图和与文本配对的图。根据LLMs的角色及其与图神经网络(GNNs)的交互方式,图上LLMs的技术可以分为将LLMs作为任务预测器(LLM as Predictor)、将LLMs作为GNNs的特征编码器(LLM as Encoder)以及将LLMs与GNNs对齐(LLM as Aligner)。 目前探索LLMs与图交叉点的综述文献数量有限。关于图上的深度学习,Wu et al. [17] 提供了图神经网络(GNNs)的全面概述,详细阐述了循环图神经网络、卷积图神经网络、图自编码器和时空图神经网络。Liu et al. [18] 讨论了图上的预训练基础模型,包括它们的骨干架构、预训练方法和适应技术。Pan et al. [19] 回顾了LLMs与知识图谱(KGs)之间的联系,特别是KGs如何增强LLMs的训练和推理,以及LLMs如何促进KG的构建和推理。总而言之,现有的综述要么更多地关注GNNs而非LLMs,要么未能从系统的视角提供它们在图1中所示的各种图场景中的应用。我们的论文提供了关于图上LLMs的全面综述,旨在帮助计算机科学和机器学习社区以外的不同背景的广泛研究人员进入这个快速发展的领域。
**分类与框架 **
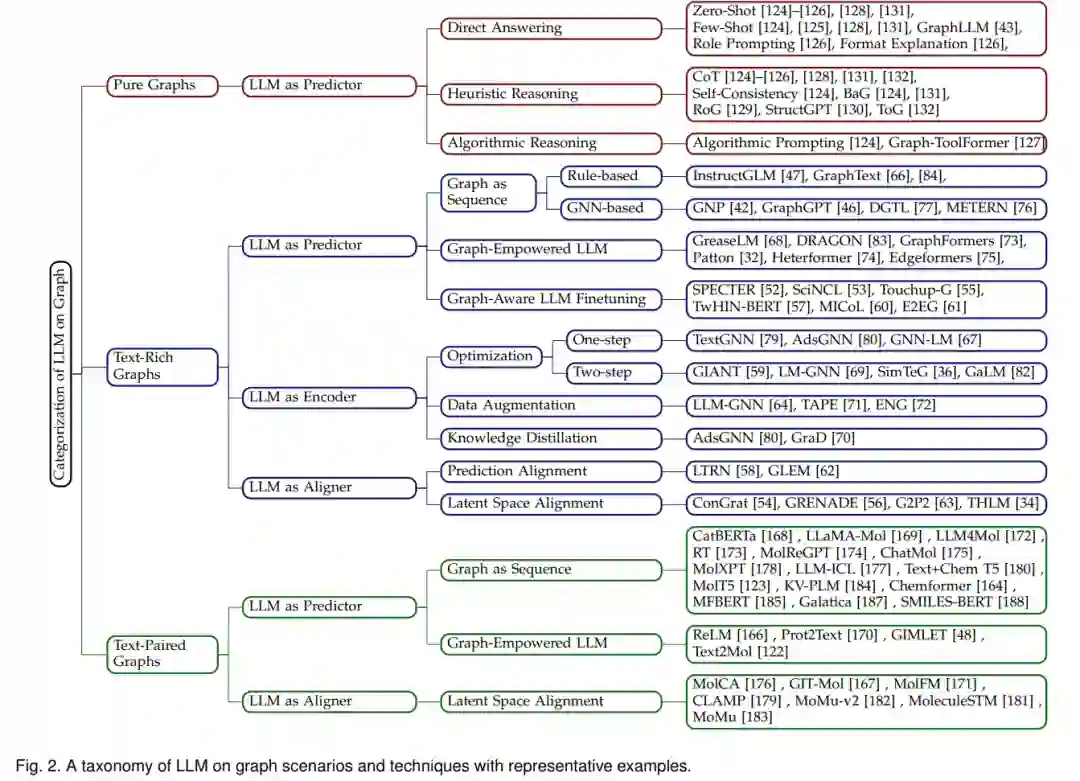
在本节中,我们首先介绍我们对可以采用语言模型的图场景的分类。然后我们讨论图上LLMs技术的分类。最后,我们总结了图上语言模型的训练与推理框架。 1 语言模型的图场景分类
纯图(无文本信息)是指没有文本信息或没有语义丰富文本信息的图。这类图的例子包括交通图和电力传输图。这些图通常作为测试大型语言模型图推理能力(解决图论问题)的背景,或作为知识来源以增强大型语言模型(减轻幻觉现象)。 文本丰富的图是指节点或边与语义丰富的文本信息相关联的图。这类图也被称为文本丰富的网络 [32]、带文本属性的图 [62]、文本图 [73] 或文本边网络 [75]。现实世界中的例子包括学术网络、电子商务网络、社交网络和法律案例网络。在这些图上,人们对学习具有文本信息和结构信息的节点或边的表示感兴趣 [73] [75]。 与文本配对的图是指文本描述定义在整个图结构上的图。这类图包括分子或蛋白质,其中节点代表原子,边代表化学键。文本描述可以是分子标题或蛋白质文本特征。尽管图结构是影响分子属性的最重要因素,但分子的文本描述可以作为补充知识来源,帮助理解分子 [148]。图场景可以在图1中找到。 **2 图上LLM技术的分类 **
根据LLMs的角色以及解决图相关问题的最终组件,我们将图上LLM技术分类为三个主要类别: LLM作为预测器。这类方法将LLM作为输出表示或预测的最终组件。它可以通过GNNs增强,并可以根据图信息如何注入LLM进行分类:1)图作为序列:这种方法不对LLM架构做任何改变,但通过将“图标记序列”作为输入使其意识到图结构。“图标记序列”可以是图的自然语言描述或由图编码器输出的隐藏表示。2)增强图的LLM:这种方法修改了LLM基础模型(即变压器)的架构,并使其能够在其架构内进行联合文本和图编码。3)图感知LLM微调:这种方法不对LLMs的输入或LLM架构做任何改变,但只是在图的监督下对LLMs进行微调。 LLM作为编码器。这种方法主要用于节点或边与文本信息相关联的图(解决节点级或边级任务)。GNNs是最终组件,我们采用LLM作为初始文本编码器。具体来说,首先利用LLMs对与节点/边相关的文本进行编码。LLMs输出的特征向量然后作为输入嵌入用于GNNs进行图结构编码。GNNs输出的嵌入被采用为下游任务的最终节点/边表示。然而,这些方法存在收敛问题、稀疏数据问题和效率问题,我们从优化、数据增强和知识蒸馏的角度总结了解决方案。 LLM作为对齐器。这类方法将LLMs作为文本编码组件,并将它们与作为图结构编码组件的GNNs对齐。LLMs和GNNs一起作为任务解决的最终组件。具体来说,LLMs和GNNs之间的对齐可以分为1)预测对齐,其中从一种模态生成的伪标签用于在另一种模态上进行迭代学习训练,和2)潜空间对齐,其中采用对比学习将LLMs生成的文本嵌入和GNNs生成的图嵌入对齐。 **3 使用LLMs的训练与推理框架 **
在图上应用语言模型有两种典型的训练和推理范式:1) 预训练-然后微调:通常用于中等规模的大型语言模型;以及 2) 预训练-然后提示:通常用于大规模的大型语言模型。 预训练指的是使用无监督目标训练语言模型,以初始化它们具备下游任务的语言理解和推理能力。纯文本的典型预训练目标包括掩蔽语言建模 [22]、自回归因果语言建模 [25]、损坏-重构语言建模 [29] 和文本到文本转换建模 [30]。在图领域扩展时,语言模型预训练策略包括文档关系预测 [31]、网络上下文化掩蔽语言建模 [32]、对比性社交预测 [33] 和上下文图预测 [34]。 微调是指使用标记数据训练语言模型以进行下游任务。语言模型微调方法可进一步分类为完全微调、高效微调和指令调整。 * 完全微调意味着更新语言模型内的所有参数。这是最常用的微调方法,可以充分激发语言模型对下游任务的潜力,但可能会导致重大计算负担 [37] 和过拟合问题 [36]。 * 高效微调是指仅微调语言模型内的一部分参数。纯文本的高效调整方法包括提示调整 [38]、前缀调整 [39]、适配器 [40] 和LoRA [41]。特别为图数据设计的高效语言模型微调方法包括图神经提示 [42] 和增强图的前缀 [43]。 * 指令调整指的是使用下游任务指令微调语言模型 [44] [45],以鼓励模型在推理中对未见任务的泛化。这是一个与完全微调和高效微调正交的概念,换句话说,人们可以同时选择完全微调和高效微调进行指令调整。指令调整在图领域用于节点分类 [46]、链接预测 [47] 和图级任务 [48]。 提示是一种在不更新模型参数的情况下应用语言模型解决下游任务的技术。需要将测试样本制定成自然语言序列,并让语言模型直接根据上下文演示进行推理。这是一种特别适用于大规模自回归语言模型的技术。除了直接提示,后续工作提出了思维链提示 [49]、思维树提示 [50] 和思维图提示 [51]。 在接下来的章节中,我们将遵循第3节的分类,并讨论每个图场景的详细方法论。
**结论 **
在本文中,我们提供了关于图上大型语言模型的全面综述。我们首先对可以采用语言模型的图场景进行分类,并总结了图上大型语言模型的技术。然后,我们对每个场景内的方法进行了彻底的审查、分析和比较。此外,我们总结了可用的数据集、开源代码库和多种应用。最后,我们提出了图上大型语言模型的未来发展方向。