

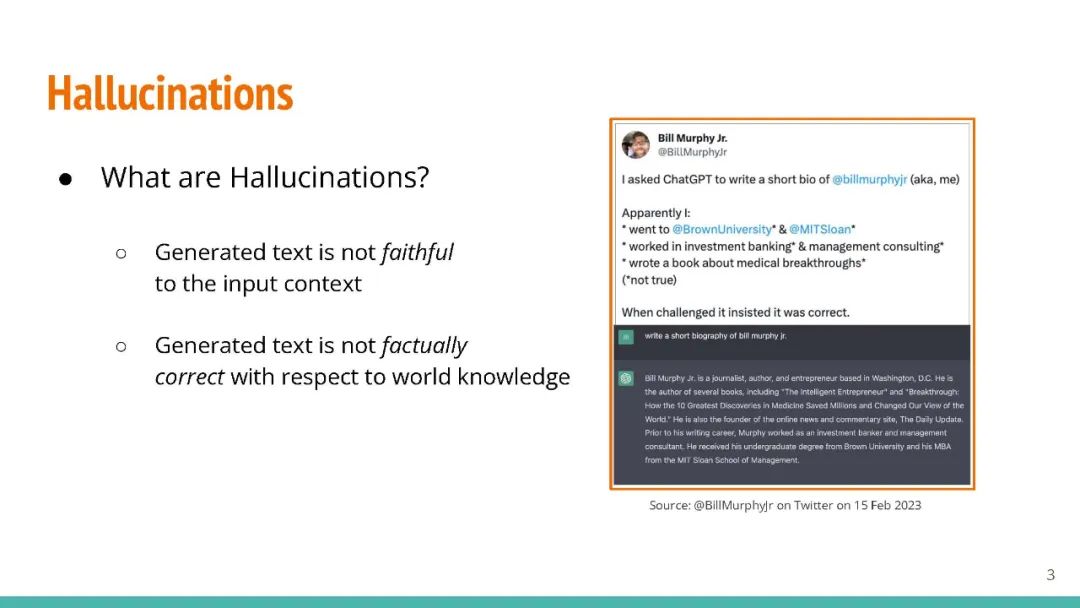
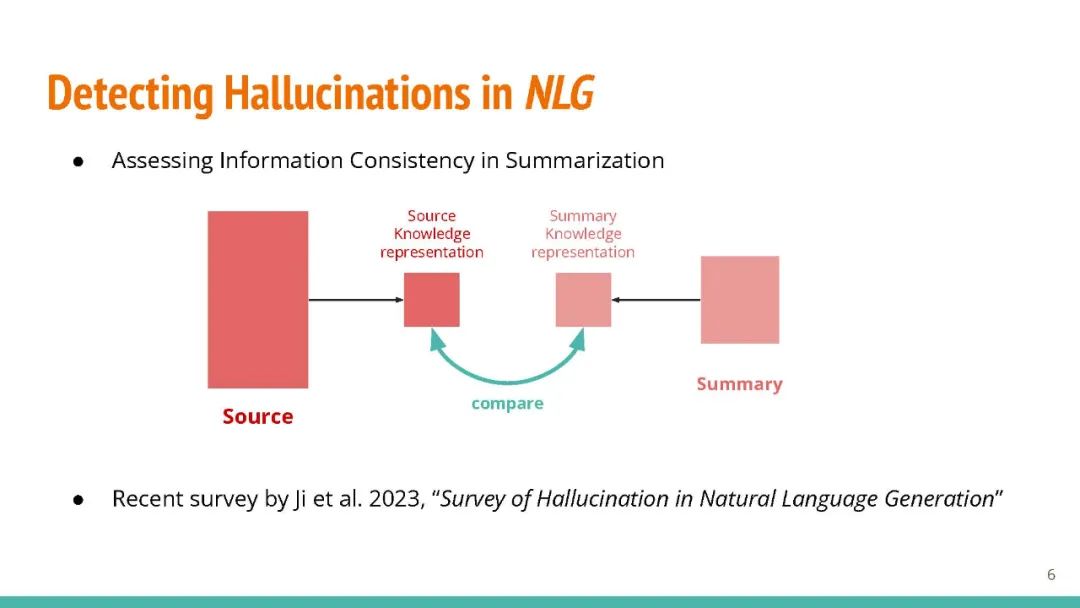
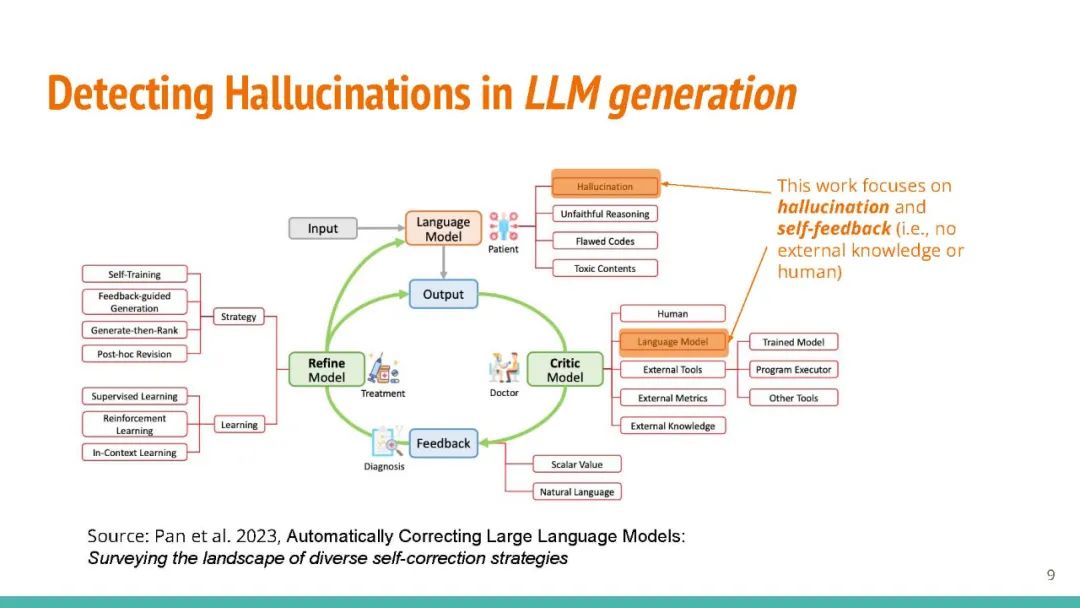
生成型大型语言模型(LLMs)如 GPT-3 能够为各种用户提示生成流畅的响应。但是,LLMs 有时会产生错误的事实,这可能会损害人们对它们输出的信任。现有的事实检查方法要么需要访问输出概率分布(这对于如 ChatGPT 这样的系统可能不可用),要么需要通过复杂的模块接口外部数据库。在这项工作中,我们提出了 "SelfCheckGPT",一个简单的基于抽样的方法,可用于在不需要外部数据库的情况下对黑盒模型进行事实检查。SelfCheckGPT 的核心思想是,如果LLM知道某个概念,抽样的响应很可能会类似并包含一致的事实。但对于错误的事实,随机抽样的响应可能会有所不同并互相矛盾。我们使用 GPT-3 生成 WikiBio 数据集中的个人文章,并手动注释生成的文章的事实性。我们证明 SelfCheckGPT 可以:i) 检测非事实性和事实性的句子;以及 ii) 根据事实性对文章进行排名。我们将我们的方法与几种基线方法进行比较,结果显示在句子错误检测中,我们的方法的 AUC-PR 分数与灰盒方法相当或更好,而 SelfCheckGPT 在文章事实性评估方面表现最佳。





成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年10月5日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月5日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日