

https://www.zhuanzhi.ai/paper/aca24bad3f6b66886c4586eb24df3602
大型语言模型(LLM)通常在大量数据上进行预训练,并包含大量参数。这些模型不仅在各种任务上表现出显著提升的性能,还展示了较小模型所缺乏的新兴能力。LLMs[1]由于其理解、推理及生成人类语言的卓越能力,在人工智能领域内获得了极大关注。为了提升LLM回应的丰富性和说服力,最近的研究[2, 3, 4]探讨了将LLM转化为遵循指令的模型。例如,斯坦福Alpaca[2]通过利用OpenAI的InstructGPT模型[6]生成的指令示例,对Llama[5]进行微调,使其成为一个遵循指令的模型。与Alpaca和Vicuna[2]采用的完全微调方法不同,Llama-Adapter[7]在冻结的Llama中引入了零初始化注意力的轻量级适配器,实现了参数高效的微调并注入了多模态知识。尽管取得了重大进步,但上述方法在处理更高级的多模态信息时仍面临挑战,例如GPT-4[8]中所涉及的视觉理解任务。实际上,我们对世界的感知是通过视觉、声音、触觉和味觉等多样化感官丰富的。这些感官经常相互作用,视觉使用文本,文本使用视觉来增强理解。随着社交媒体的发展,人们表达观点的方式经常涉及多种模态。这就要求LLMs能够理解多模态数据,这就是所谓的多模态大型语言模型(MLLM)。它们利用大型语言模型(LLM)的强大能力作为核心组件,来处理多种多模态任务。MLLM的显著新兴能力,如从图像生成叙事和无需OCR进行数学推理,是传统方法中罕见的。这表明了实现人工通用智能的潜在路径。随着多模态模型的迅速发展,它们更适合具有多模态信息交互的真实世界场景,扩大了大型多模态模型的应用前景,并产生了更迫切的研究需求。
然而,当MLLM在处理多模态间的语义差距时表现不佳,可能会导致错误的生成,包括错觉,对社会构成潜在风险甚至可能造成伤害。不当的模态对齐方法可能需要更多参数,但性能提升有限,导致高昂的计算和使用成本。因此,选择合适的模态对齐方法很重要。本综述旨在探索为LLM设计的模态对齐方法及其在该领域内的现有能力。实施模态对齐使LLM能够解决环境问题,提高可访问性,并在部署中促进包容性。然而,将大型模型的能力转移到多模态场景的方法尚不明确。尽管Yin等人[10]专注于将多模态信息融入到LLM的微调技术中,如指令学习或思维链,但在调查数据中不同模态间的差异方面缺乏关注。另一方面,已有许多努力将LLM与人类行为和价值观进行对齐。然而,“与什么对齐”的根本问题仍然没有得到充分解决。因此,[11]和Shen等人[12]提出了一项关于LLM对齐目标的综述。不过,这些努力更倾向于对齐技术,确保这些模型展示与人类价值观一致的行为。由于LLM和MLLM都处于发展的初期阶段,现有的多模态对齐方法呈现出广泛的差异,研究方向目前处于探索和实验阶段。因此,需要组织关于多模态信息对齐的各种现有研究方法。在MLLM时代仍处于萌芽阶段,我们旨在不断更新本综述,以激发更多研究兴趣。
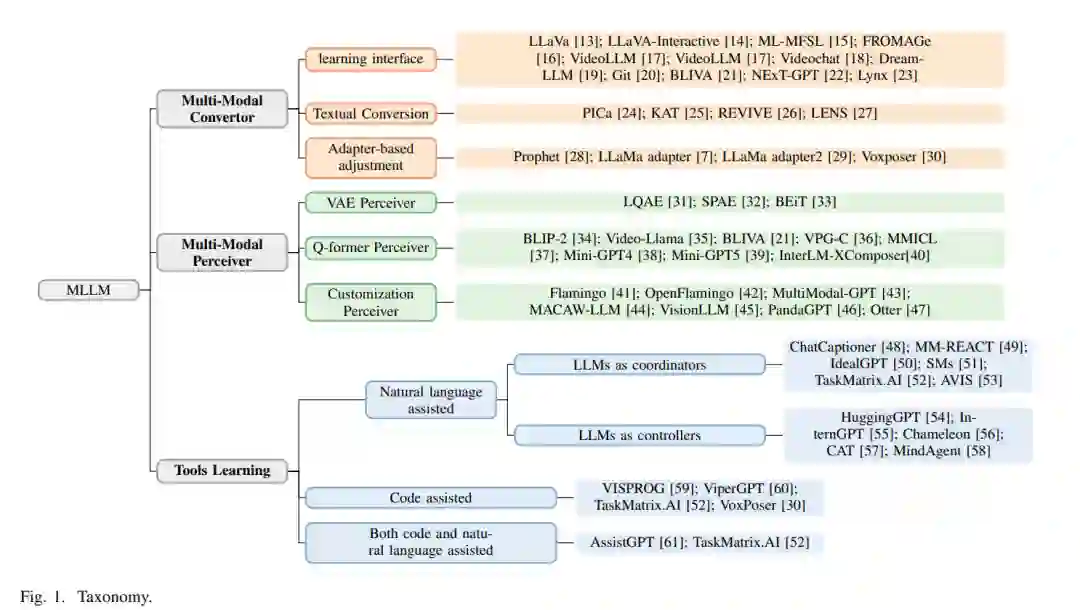
从互补性角度来看,单模态LLM和视觉模型同时相互迈进,最终催生了MLLM这一新领域。本质上,MLLM指的是具备接收和推理多模态信息能力的基于LLM的模型。总之,探索单模态LLM如何适应多模态数据,以及如何有效地将视觉模型与单模态LLM集成,具有重要价值。具体来说,我们将MLLM分为四种结构类型,每种类型从不同角度解决模态间的差异。(1)多模态转换器。转换器促进将多模态信息转化为LLM能理解或学习的对象,利用LLM的能力学习这些转换后的对象。(2)多模态感知器。这些方法专注于设计与LLM接口的多模态感知器,主要是为了增强对多模态信息的感知能力。(3)工具辅助。鼓励使用工具将不同模态转换为统一的模态,主要是文本,最终完成多模态任务。(4)数据驱动。数据驱动方法旨在通过让LLM在特定数据集上学习,赋予它与特定数据集相关的能力。例如,在点云数据集上学习使模型能够理解点云。
我们的主要贡献如下。
• 我们强调了在多模态大型语言模型中弥合模态差距的方法的重要性,并提供了第一个关于多模态信息对齐的综合性综述。 • 我们涵盖了弥合模态差距的四种方法:多模态转换器、多模态感知器、工具辅助和数据驱动方法,并为每种方法提供定义,并追踪它们的发展路径。 • 通过阐明MLLM中多模态信息对齐的不同方法,我们讨论了主要挑战和可能的未来研究方向。
概述****我们根据处理多模态特征的方法将这些方法分为四组。因此,本文将最近的代表性MLLM分为四类: (1)将LLM作为多模态特征的直接处理器; (2)利用多模态感知器的MLLM来处理多模态特征; (3)将LLM作为处理多模态特征的工具; (4)在特定格式的数据上学习,赋予LLM适应额外模态的能力。请注意,这四种技术相对独立,可以组合使用。因此,我们对一个概念的阐述也可能涉及其他概念。
我们根据这四个主要类别组织了综述,并依次介绍它们。我们首先详细介绍将LLM作为多模态特征的直接处理器的MLLM,以揭示当LLM作为直接处理器时如何适应多模态性。接着,我们介绍利用多模态感知器处理多模态特征的MLLM,主要关注如何创新多模态感知机制,使LLM能够理解多模态信息。另一项重要技术是辅助LLM,这通常涉及四种辅助技术。最后,我们以总结和潜在的研究方向结束我们的综述。
多模态转换器
鉴于语言模型(LLM)的显著能力,处理多模态任务最直接的方法是将多模态特征直接输入到LLM中,让它学习和理解这些多模态特征。然而,由于LLM主要在通用文本上进行训练和学习,因此在处理多模态特征时存在不可避免的语义差距。直接注入这些特征可能导致严重的幻觉和偏离事实的答案生成。因此,当代研究人员通常努力将多模态特征,如图像特征,映射到与语言相一致的特征空间中,旨在提高多模态语言模型(MLLM)的性能。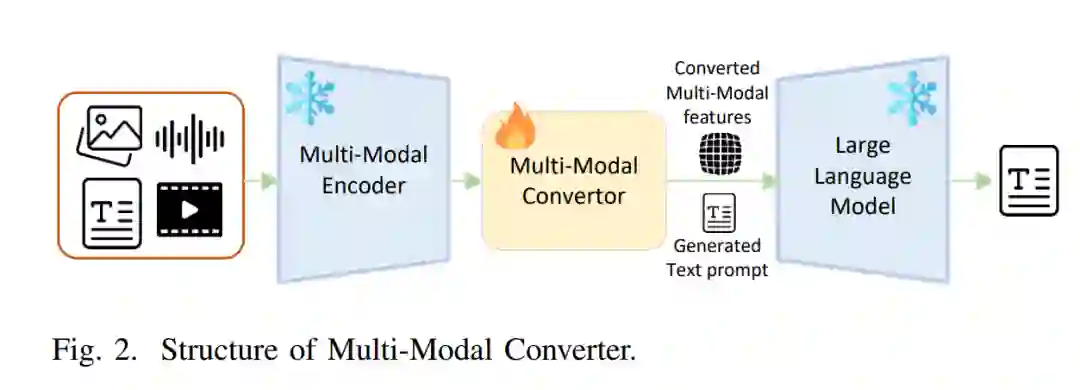
**数据驱动的MLLM **大规模模型的快速发展在很大程度上依赖于使用广泛的数据集进行训练。包括多模态模型在内的传统大型模型主要建立在通用数据集之上,这些数据集通常来源于互联网上的未标注文本[82]。虽然这些数据集涵盖了广泛的领域,但这些模型更倾向于通用能力。然而,当面对更复杂的多模态信息时,如医学图像[64]或生物分子的结构[83],与这些模态相关的数据较少。因此,模型缺乏对这些特定领域的训练和认知,导致性能不佳,甚至无法理解这些模态。结论研究[84]表明,随着训练参数和数据量的增加,模型表现出可预测的性能改进、更高的样本利用率,甚至不可预测的能力。这些不可预测的能力在较小的模型中不常见,但在LLM中已经出现。因此,越来越多的研究人员正在采用数据驱动策略,收集或构建特定领域的数据,并将其作为训练和微调模型的基础,以赋予它们对多模态信息的额外理解能力。实验表明,不改变模型结构,改变训练数据的重点可以赋予大型模型不同的能力[65, 66, 85, 86, 87, 88]。