

大型语言模型(LLMs)的出现标志着自然语言处理(NLP)领域的一次重大突破,带来了在文本理解和生成方面的显著进步。然而,与这些进步同时,LLMs表现出一种关键的倾向:产生幻觉,导致生成的内容与现实世界事实或用户输入不一致。这一现象对它们的实际部署提出了重大挑战,并引发了对LLMs在现实世界场景中可靠性的关注,这吸引了越来越多的注意力来检测和减轻这些幻觉。在这篇综述中,我们旨在提供一个关于LLM幻觉最新进展的全面而深入的概览。我们首先提出LLM幻觉的一个创新性分类,然后深入探讨导致幻觉的因素。随后,我们呈现了一份幻觉检测方法和基准的综合概览。此外,相应地介绍了旨在减轻幻觉的代表性方法。最后,我们分析了凸显当前限制的挑战,并提出了开放性问题,旨在勾勒出LLMs中幻觉未来研究的路径。
最近,大型语言模型(LLMs)(OpenAI, 2022; Google, 2023; Touvron et al., 2023; Penedo et al., 2023; Zhao et al., 2023b)的出现引领了自然语言处理(NLP)领域的范式转变,实现了在语言理解(Hendrycks et al., 2021; Huang et al., 2023c)、生成(Zhang et al., 2023f; Zhu et al., 2023b)和推理(Wei et al., 2022; Kojima et al., 2022; Qiao et al., 2022; Yu et al., 2023a; Chu et al., 2023)方面前所未有的进步。然而,随着LLMs的快速发展,出现了一个令人关注的趋势,即它们倾向于产生幻觉(Bang et al., 2023; Guerreiro et al., 2023b),导致内容看似合理但事实上缺乏支持。当前对幻觉的定义与先前的研究(Ji et al., 2023a)一致,将其描述为生成的内容既无意义又不忠于提供的源内容。这些幻觉进一步被分类为内在幻觉和外在幻觉,取决于与源内容的矛盾性。尽管这种分类在各种自然语言生成(NLG)任务中是共享的,但任务特定的变体确实存在。由于LLMs在不同NLG任务中表现出非凡的多功能性和卓越性能(Bubeck et al., 2023; Bang et al., 2023),尤其是在开放域应用中,它们的多功能性相比于任务特定模型更加放大了幻觉的潜力。在LLMs中,幻觉的范围包括了更广泛和更全面的概念,主要集中在事实错误上。鉴于LLM时代的演进,有必要调整现有的幻觉分类,增强其适用性和适应性。
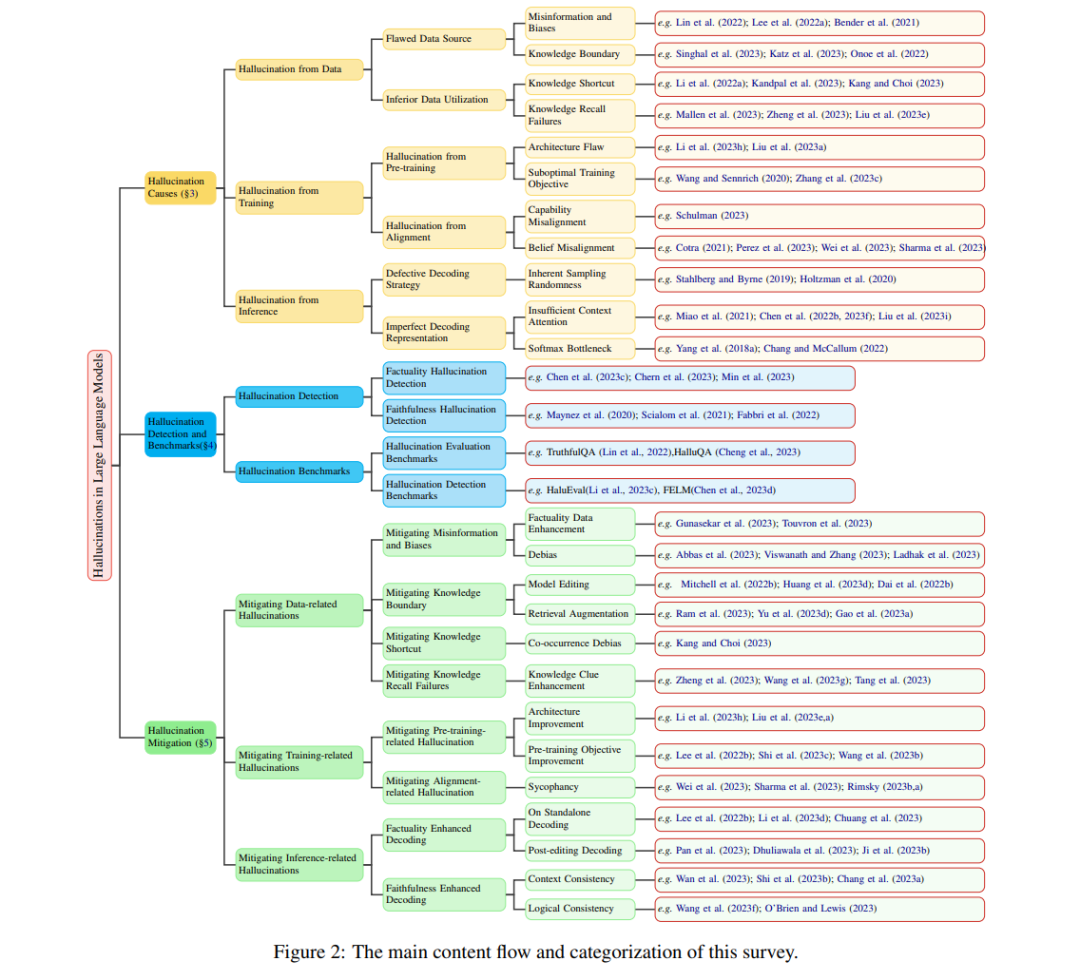
在这篇综述中,我们重新定义了幻觉的分类,为LLM应用提供了一个更为量身定做的框架。我们将幻觉分为两大类:事实性幻觉和忠实性幻觉。事实性幻觉强调生成内容与可验证的现实世界事实之间的差异,通常表现为事实上的不一致或捏造。例如,如图1(a)所示,当询问第一个登月的人时,模型可能断言是查尔斯·林德伯格在1951年。而事实上,第一个登月的人是尼尔·阿姆斯特朗,在1969年的阿波罗11号任务中。另一方面,忠实性幻觉指的是生成内容与用户指令或输入提供的上下文的偏离,以及生成内容内的自我一致性。如图1(b)所示,当要求总结一篇新闻文章时,模型不准确地将以色列和哈马斯之间的冲突实际发生日期从2023年10月改为2006年10月。关于事实性,我们进一步根据可验证来源的存在将其划分为两个子类别:事实不一致和事实捏造。对于忠实性,我们强调从用户的角度解决不一致性,将其分类为指令不一致、上下文不一致和逻辑不一致,从而更好地与LLMs的当前使用情况相对应。
至于幻觉的潜在原因,虽然在NLG任务的背景下进行了研究,但在尖端LLMs中呈现出独特的挑战,值得深入调查。我们的深入分析专门针对LLMs中幻觉的独特起源,涵盖了从数据、训练到推理阶段的一系列贡献因素。在这个框架内,我们指出了潜在的数据相关原因,如有缺陷的来源和次优的利用,低劣的训练策略可能在预训练和对齐过程中诱发幻觉,以及源于解码策略的随机性和推理过程中不完美表现的问题。此外,我们全面概述了专门为检测LLMs中的幻觉而设计的有效检测方法,以及与LLM幻觉相关的详尽基准概览,作为适当的测试平台,以评估LLMs生成的幻觉的程度和检测方法的有效性。此外,我们详细介绍了为减轻已识别的幻觉原因而量身定制的全面策略。
通过这篇全面的综述,我们旨在为LLMs领域的发展做出贡献,并提供有价值的见解,加深对LLMs中幻觉机会和挑战的理解。这项探索不仅增强了我们对当前LLMs局限性的理解,还为未来的研究和更鲁棒、可信赖的LLMs的发展提供了必要的指导。
与现有综述相比。随着对可靠生成AI的需求日益增长,LLM幻觉作为一个主要挑战脱颖而出,导致了许多关于其最新进展的综述(Ji et al., 2023a; Rawte et al., 2023; Liu et al., 2023h; Zhang et al., 2023g; Wang et al., 2023c)。虽然这些作品从不同角度探讨了LLM幻觉,并提供了有价值的见解,但区分我们当前综述的独特方面和全面性是至关重要的。(Ji et al., 2023a)主要阐明了预训练语言模型在NLG任务领域中的幻觉,将LLMs排除在他们的讨论范围之外。(Liu et al., 2023h)从更广阔的视角讨论了LLMs的可信度,而(Wang et al., 2023c)深入探讨了LLM事实性。相比之下,我们的综述聚焦于LLM可信度中的一系列挑战,涵盖事实性方面,并进一步扩展了话语范围,包括与忠实性相关的幻觉。据我们所知,与我们的综述最为一致的是(Zhang et al., 2023g),它概述了LLM幻觉现象的分类、评估基准和减轻策略。尽管如此,我们的综述在分类和组织结构上都有所区别。我们提出了幻觉的分层和细粒度分类。在结构上,我们通过追溯到LLMs的能力来剖析LLM幻觉的原因。更为相关的是,我们的减轻策略与潜在原因密切相关,确保了一种连贯和有针对性的方法。
本综述的组织结构。在本文中,我们提出了关于LLMs中幻觉的最新发展的全面综述。我们首先定义LLMs并构建幻觉的分类框架(§2)。随后,我们深入分析了导致LLMs中幻觉的因素(§3),接着是对用于可靠检测LLMs中幻觉的各种方法和基准的审查(§4)。然后我们详细介绍了旨在减轻LLMs中幻觉的一系列方法(§5)。最后,我们深入探讨了框定当前局限性和未来前景的挑战和开放性问题,提供见解并勾勒出未来研究的潜在路径(§6)。
幻觉的原因
幻觉有多方面的起源,涵盖了大型语言模型(LLMs)能力获取过程的整个光谱。在这一部分,我们将深入探讨LLMs中幻觉的根本原因,主要分为三个关键方面:数据(§3.1)、训练(§3.2)和推理(§3.3)。
数据引起的幻觉
预训练数据是LLMs的基石,使它们获得一般能力和事实知识(周等,2023a)。然而,它可能无意中成为LLM幻觉的来源。这主要表现在两个方面:源自有缺陷数据源的潜在风险(§3.1.1),以及对数据中捕获的事实知识的劣质利用(§3.1.2)。
训练引起的幻觉
大型语言模型(LLMs)的训练过程主要包括两个主要阶段:1)预训练阶段,LLMs在此阶段学习通用表示并捕获世界知识;2)对齐阶段,LLMs被调整以更好地与用户指令和偏好对齐。虽然这个过程为LLMs装备了显著的能力,但这些阶段的任何短板都可能无意中导致幻觉。
推理引起的幻觉
解码在展示LLMs在预训练和对齐之后的能力方面扮演着重要角色。然而,解码策略中的某些不足可能导致LLM幻觉。在本节中,我们将深入探讨根源于解码过程的潜在原因,强调两个关键因素:解码策略的固有随机性(§3.3.1)和不完美的解码表示(§3.3.2)。
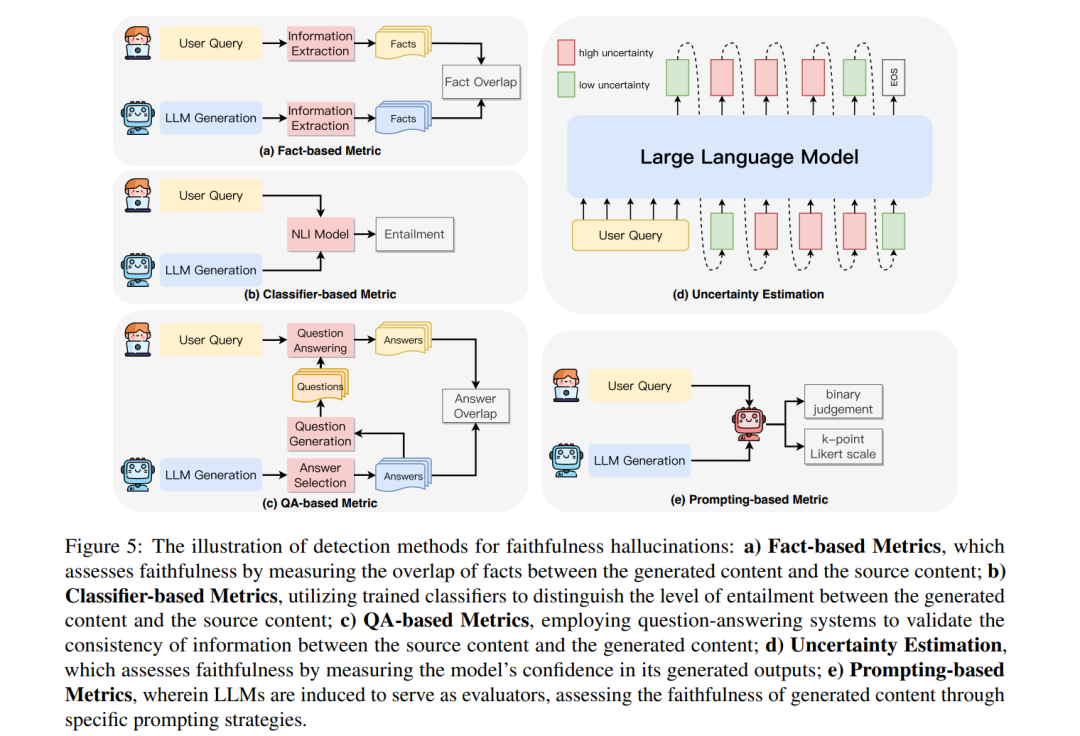
幻觉缓解
在本节中,我们提供了针对缓解大型语言模型(LLMs)中幻觉的现代方法的全面回顾。借鉴在“幻觉的原因”(§3)中讨论的见解,我们系统地根据幻觉的潜在原因对这些方法进行分类。具体来说,我们关注解决与数据相关的幻觉(§5.1)、与训练相关的幻觉(§5.2)和与推理相关的幻觉(§5.3)的方法,每种方法都针对其各自原因固有的特定挑战提供了量身定制的解决方案。
缓解与数据相关的幻觉
与数据相关的幻觉通常作为偏见、错误信息和知识空缺的副产品出现,这些都根本上植根于训练数据中。在这个背景下,我们探索了缓解此类幻觉的各种策略,旨在尽量减少错误信息和偏见的发生,同时也提供知识增强和提高大型语言模型(LLMs)有效利用知识的能力。
缓解与训练相关的幻觉
与训练相关的幻觉通常源自大型语言模型(LLMs)所采用的架构和训练策略的内在局限性。在这一背景下,我们讨论了从训练阶段(§5.2.1)到对齐阶段(§5.2.2)的各种优化方法,旨在缓解训练过程中的幻觉。
缓解与推理相关的幻觉
在大型语言模型(LLMs)中,解码策略在决定生成内容的事实性和忠实性方面起着关键作用。然而,如第§3.3节分析所述,不完美的解码常常导致输出结果可能缺乏事实性或偏离原始上下文。在本小节中,我们探索两种先进策略,旨在改进解码策略,以增强LLMs输出的事实性和忠实性。
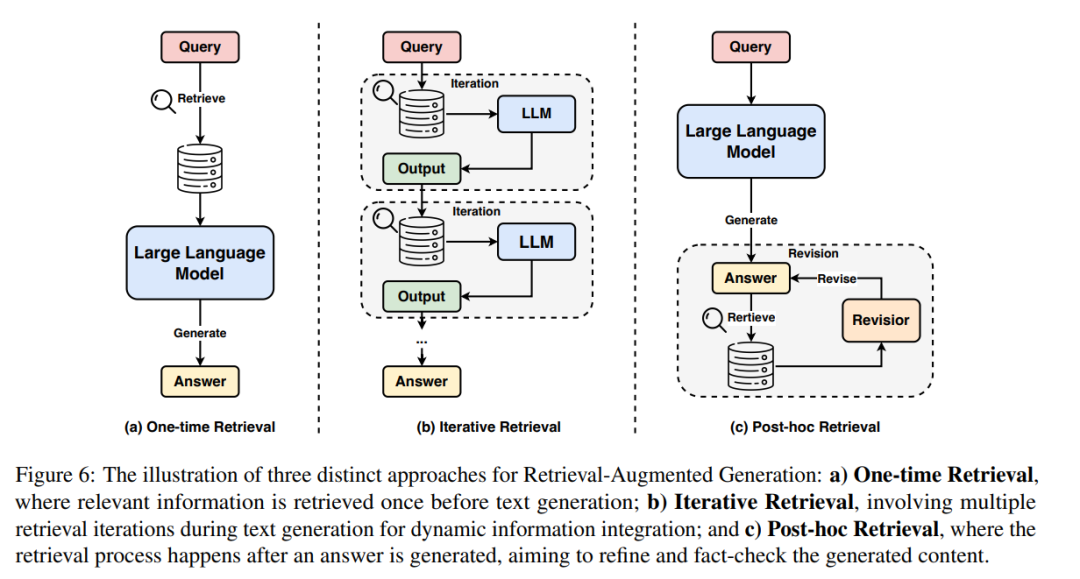
结论
在这项全面的调查中,我们对大型语言模型中的幻觉进行了深入的研究,探讨了它们背后的复杂原因、开创性的检测方法以及相关基准,以及有效的缓解策略。尽管已经取得了重大进步,但大型语言模型中的幻觉问题仍然是一个引人关注的持续问题,需要持续的研究。此外,我们希望这项调查能成为致力于推进安全和可信赖人工智能的研究人员的指导灯塔。通过导航幻觉的复杂景观,我们希望能赋予这些专业人士宝贵的洞见,推动人工智能技术向更高的可靠性和安全性发展。