【AAAI2022】跨域少样本图分类
首篇跨域少样本图分类论文

https://www.zhuanzhi.ai/paper/7d990430868993cdc161e8ced1ca4fcb
-
我们引入了跨域少样本图分类的三个基准 ,并进行了详尽的实验来评估监督、对比和元学习策略的性能。
-
我们提出了一种图编码器,可以学习图的三个一致视图、一个上下文视图和两个拓扑视图,学习任务特定信息的表示,以便快速适应,以及任务无关信息,以便进行知识迁移。
-
我们表明,当与基于指标的元测试框架相结合时,所提出的编码器在所有三个基准上都实现了最佳的平均元测试分类准确度。
方法
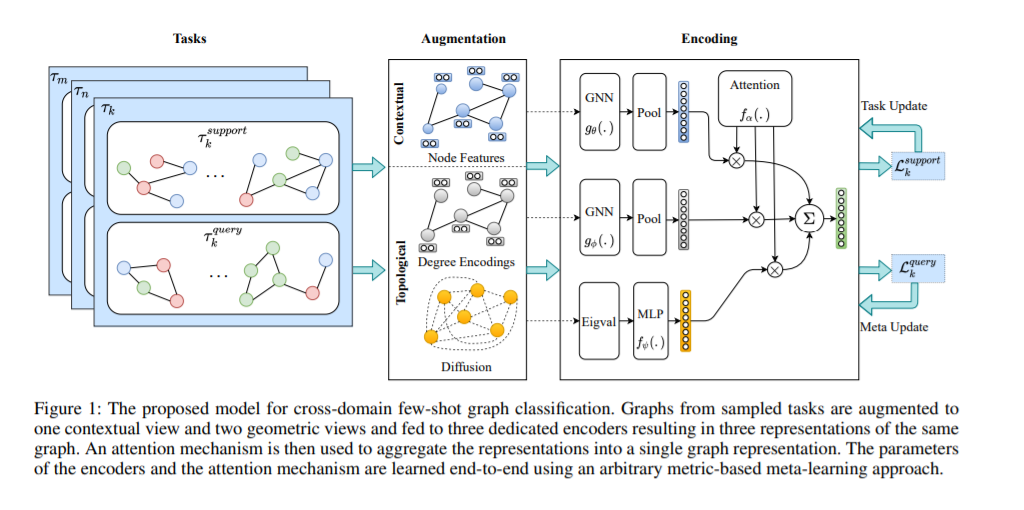
图结构数据可以从两个一致的视图进行分析: 上下文视图和拓扑视图。上下文视图基于初始节点或边缘特征(为了简单和不失一般性,我们只考虑节点特征),并携带特定于任务的信息。另一方面,拓扑视图表示图的拓扑属性,这些拓扑属性是任务无关的,因此可以作为锚点来对齐来自特征空间中不同领域的图。我们利用这种对偶表示,并通过为每个视图设计专用编码器来明确地解开它们,这些视图反过来施加了所需的归纳偏见,以学习特定于任务的域不变特征。在异构的少样本环境中,拓扑特征有助于跨任务的知识迁移,而上下文特征有助于快速适应。我们还使用了一种注意力机制,该机制隐含地限制了任务,并学习从两种视图中聚合学习到的特征。我们采用元学习策略,通过共同学习编码器参数和注意力机制来模拟泛化过程。如图1所示,我们的方法由以下组件组成:
增强机制,将一个采样图转换为一个上下文视图和两个拓扑视图。对初始节点特征和图结构进行增强处理。
编码器包括两个专用的GNN,即图形编码器,和一个MLP,分别用于上下文和拓扑视图,以及一个注意力机制来聚合学习的特征。
元学习机制,基于查询集的错误信号,联合学习专用编码器和注意力模型的参数。
我们详尽地进行了实证评估,以回答以下问题:
(1) 基准的元测试集分类精度的实证上限是多少?
(2) 跨元域是否存在知识迁移?如果没有,是否会发生负迁移?
(3) 基于对比的预训练效果如何?
(4) 基于度量的元学习方法与基于优化的元学习方法相比表现如何?
(5) 使用提出的编码器有什么效果?
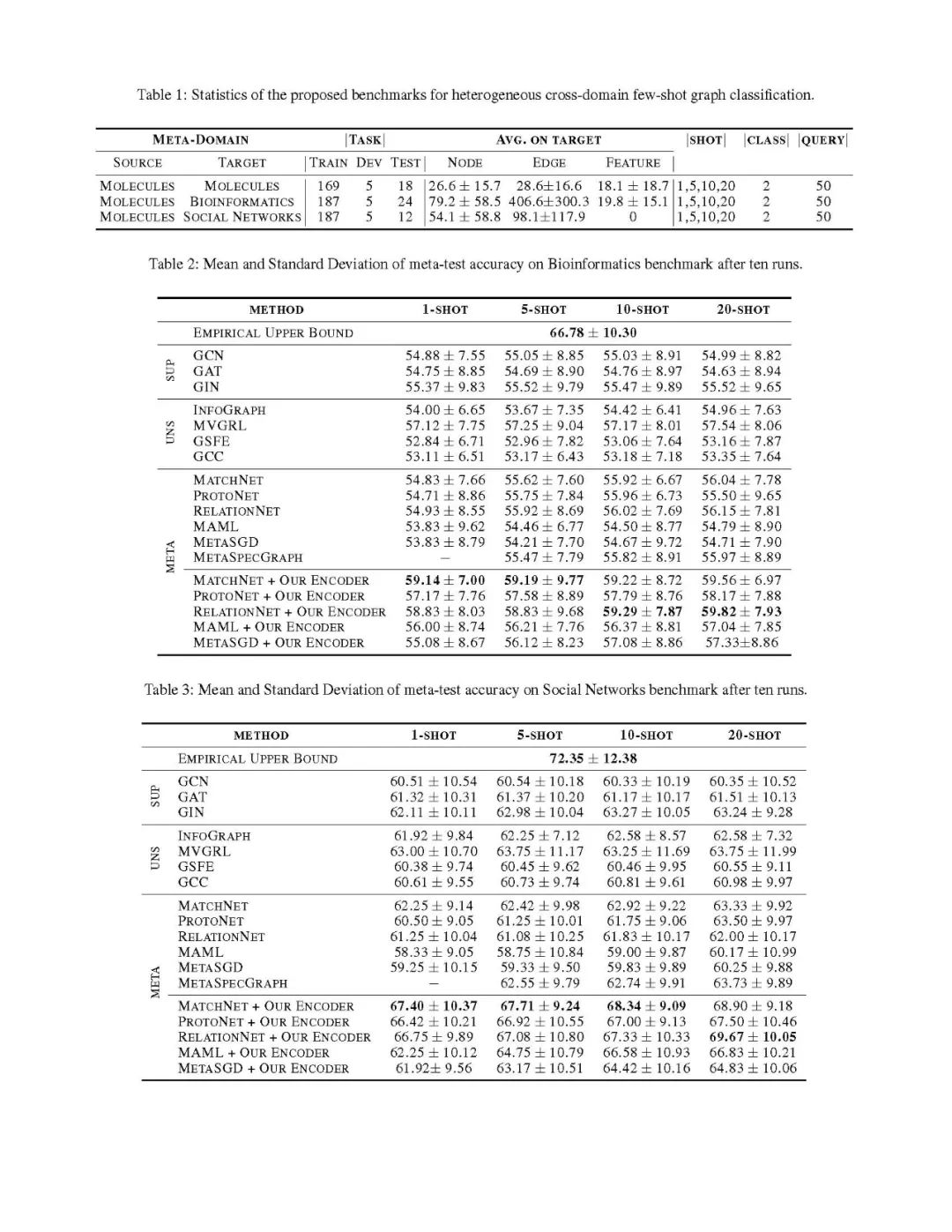
结果表明: (1) 在这三个基准上,都存在可迁移的潜在知识。实验结果证实通过观察元学习和对比方法都优于单纯分类器。(2) 对比方法与元学习方法相比具有更强的性能。例如,在20-shot生物信息学基准测试中,MVGRL的绝对准确度比最佳的元学习方法高出1.57%。(3) 将基于度量的元学习方法与我们提出的编码器相结合,显著提高了性能。例如,在单次测试的情况下,最佳元学习方法结合我们的编码器,在分子、生物信息学和社交网络基准上的绝对精度分别比常规元学习方法的最佳结果高出3.28%、4.29%和5.17%。(4)与我们的编码器相结合,仅用20个例子训练的RelationNet模型,与全监督模型在所有可用的分子数据、生物信息学和社会网络基准上训练的模型相比,准确率分别只有4.46%、6.96%和2.68%。注意,其中一些数据集有成千上万个训练样本。(5) 当我们将知识从分子元训练迁移到社会网络元测试时,我们得到了最大的改进。这是因为社会网络任务不包含任何初始节点特征,因此对它们进行分类完全依赖于任务不可知的几何特征。这表明我们的编码器能够在一个领域学习表达几何表示并泛化到另一个领域。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CFSG” 就可以获取《【AAAI2022】跨域少样本图分类》专知下载链接




